
根目录是fin,子目录是abc,oss路径应该是'fin/abc/text.xlsx',按照这个变量进行上传文件后不会报错,但是bucket里也没有增加对应路径的文件,只会增加'abc'这个子目录。
def Upload(file_path,uploda_path):
#print(file_path,uploda_path)
auth = oss2.Auth('LTAI5**********22NHn','Allr******************3w')#API的token
bucket = oss2.Bucket(auth, 'http://oss-cn-shanghai.aliyuncs.com', 'p****st-p****te')#API的endpoint和Bucket库名
with open(file_path, 'rb') as fileobj:
# Seek方法用于指定从第1000个字节位置开始读写。上传时会从您指定的第1000个字节位置开始上传,直到文件结束。
fileobj.seek(0, os.SEEK_SET)
# Tell方法用于返回当前位置。
current = fileobj.tell()
# 填写Object完整路径。Object完整路径中不能包含Bucket名称。
#bucket.put_object(uploda_path, fileobj)
bucket.put_object(uploda_path, fileobj)
file_path = r"D:\\Text\\DJ\\Oss_Text_Upload10.xlsx"
uploda_path = "fin/abc/12345.xlsx"
Upload(file_path,uploda_path)
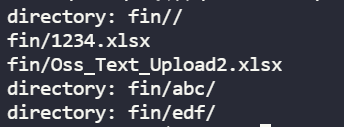 这是上传后的查询结果,根本没有传进去。只是建立了abc这个子目录
这是上传后的查询结果,根本没有传进去。只是建立了abc这个子目录
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
