
物模型中文乱码
中文乱码
项目上线到至今代码和产品物模型属性未更改过,近日数据提交一项属性中文乱码
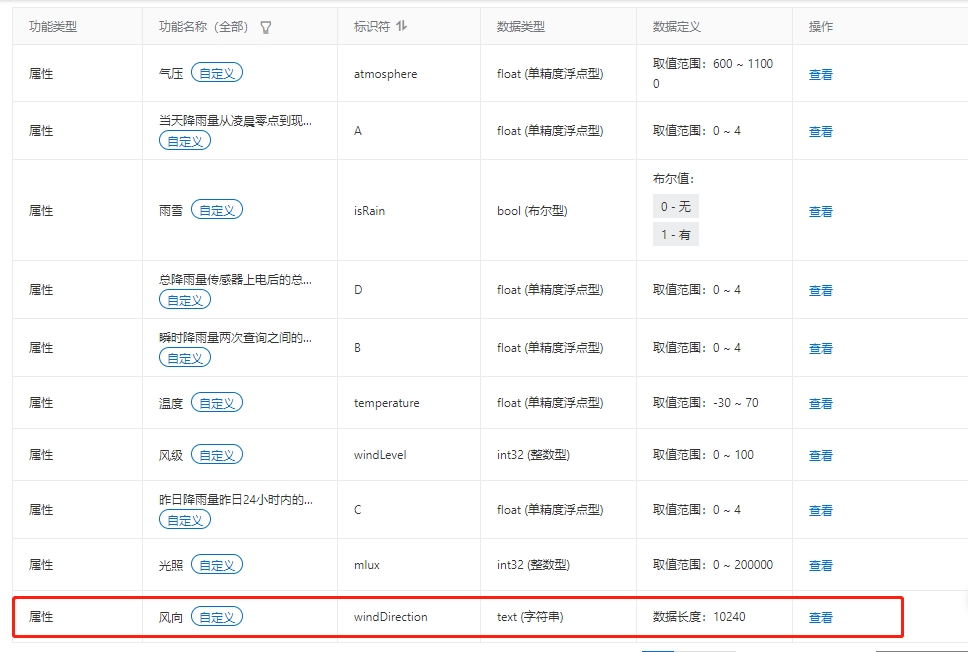
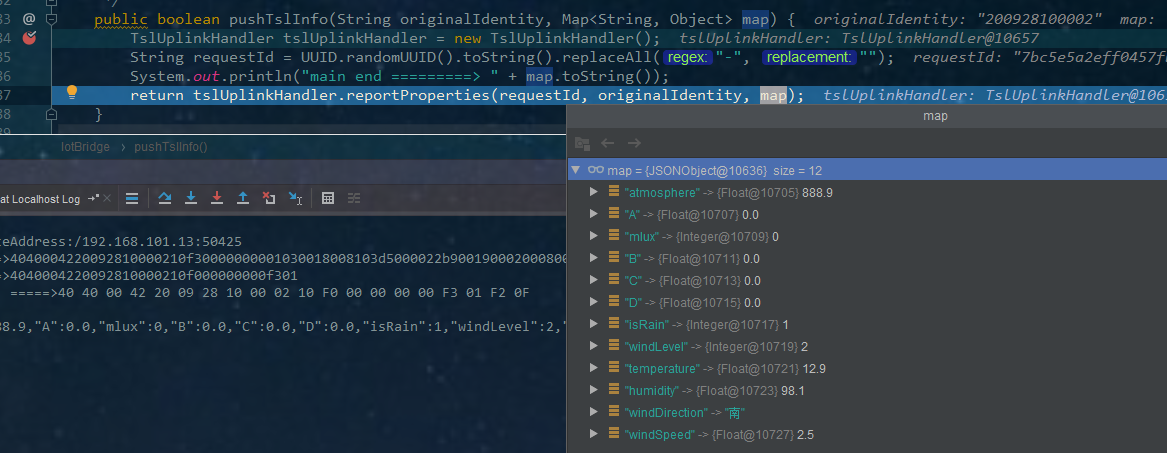
具体代码截图如下 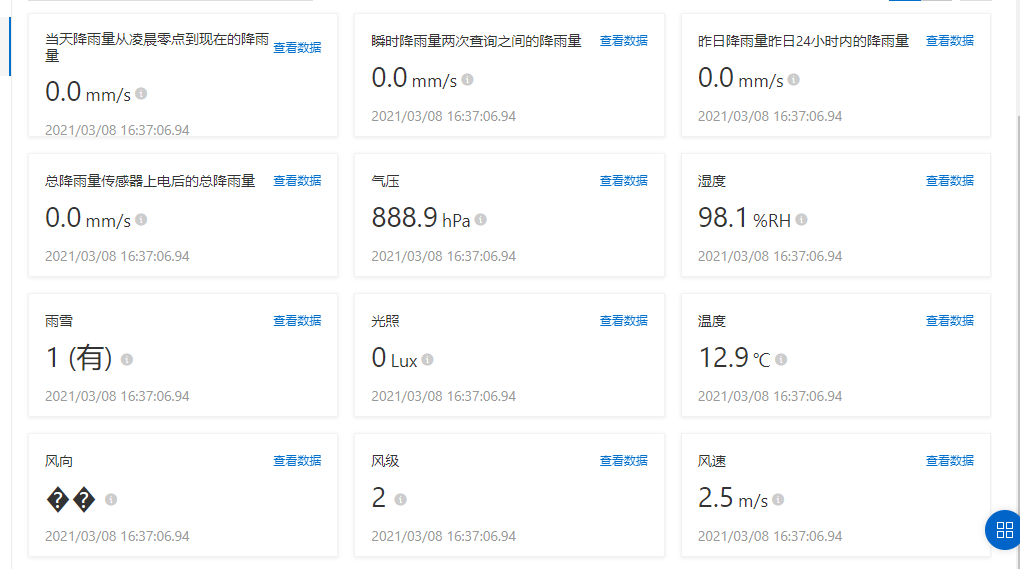
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
根据您提供的问题描述和知识库中的参考资料,以下是关于中文乱码问题的详细分析与解决方案:
1. 问题背景分析
项目上线后代码和物模型属性未发生更改,但近日提交的一项属性出现了中文乱码。这种情况可能由以下原因导致: - 数据传输过程中编码格式不一致。 - 数据存储或解析时未正确处理中文字符。 - 物模型消息解析脚本中可能存在编码问题。
结合知识库中的相关资料,中文乱码问题通常与数据类型、编码设置或解析逻辑有关。
2. 可能的原因及解决方法
2.1 数据传输编码问题
在物联网平台中,设备与云端通信时,若未明确指定编码格式(如UTF-8),可能导致中文字符在传输过程中被错误解析。
解决方法: - 确保设备端和云端均使用统一的编码格式(推荐使用UTF-8)。 - 如果使用的是MaxCompute Spark,可以在配置项中添加以下参数以确保编码一致性:
spark.executor.extraJavaOptions="-Dfile.encoding=UTF-8"
spark.driver.extraJavaOptions="-Dfile.encoding=UTF-8"
2.2 数据存储类型问题
如果属性值存储在数据库中(如SQL Server),且字段类型为VARCHAR而非NVARCHAR,则可能导致中文字符无法正确存储或查询。
解决方法: - 检查数据库表结构,将字段类型从VARCHAR改为NVARCHAR,并确保插入数据时使用前置词N以避免乱码问题。例如:
INSERT INTO temp
SELECT N'中文字符'
UNION ALL
SELECT N'其他字符';
2.3 物模型消息解析脚本问题
在物联网平台中,设备自定义数据格式需要通过消息解析脚本转换为Alink JSON格式。如果脚本中未正确处理中文字符,可能导致乱码。
解决方法: - 检查消息解析脚本,确保在rawDataToProtocol和protocolToRawData函数中正确处理中文字符。例如,在JavaScript脚本中,可以使用Buffer对象进行编码转换:
function rawDataToProtocol(bytes) {
const str = Buffer.from(bytes).toString('utf8');
return JSON.parse(str);
}
function protocolToRawData(json) {
const str = JSON.stringify(json);
return Buffer.from(str, 'utf8');
}
2.4 属性标识符冲突
物模型属性的标识符不能使用保留关键字(如set、get、property等)。如果属性标识符命名不当,可能导致解析异常。
解决方法: - 检查物模型属性的标识符是否符合规范。标识符应仅包含大小写英文字母、数字和下划线(_),且长度不超过50个字符。例如:
{
"identifier": "custom_property",
"dataType": "text"
}
3. 具体排查步骤
3.1 检查设备端编码设置
- 确认设备端上报属性时使用的编码格式是否为UTF-8。
- 如果使用MQTT协议,检查连接信息中的
url是否携带正确的端口(如1883)。
3.2 检查云端接收逻辑
- 在云端接收属性时,确认是否正确解析了中文字符。例如,参考以下代码片段:
Map<String, ValueWrapper> data = (Map<String, ValueWrapper>) ((InputParams) result).getData(); ValueWrapper.StringValueWrapper value = (ValueWrapper.StringValueWrapper) data.get("propertyName"); if (value != null) { System.out.println("Received property value: " + value.getValue()); }
3.3 验证数据库存储
- 查询数据库中存储的属性值,确认是否出现乱码。如果字段类型为
VARCHAR,建议改为NVARCHAR并重新插入数据。
3.4 审核消息解析脚本
-
检查消息解析脚本是否正确处理了中文字符。如果使用Python脚本,可以参考以下示例:
def raw_data_to_protocol(bytes): return json.loads(bytes.decode('utf-8')) def protocol_to_raw_data(json_data): return json.dumps(json_data).encode('utf-8')
4. 重要提醒
- 加粗提示:在修改数据库字段类型或调整编码设置时,请务必先备份数据,以免造成数据丢失。
- 如果问题仍未解决,建议联系阿里云技术支持团队,提供详细的日志信息以便进一步排查。
通过以上步骤,您可以逐步定位并解决中文乱码问题。希望这些信息对您有所帮助!