
Flink 1.10 Native Kubernetes原理是什么?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
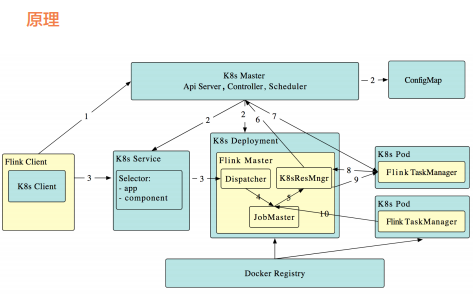 工作原理如下(段首的序号对应图中箭头所示的数字): 1. Flink 客户端首先连接 Kubernetes API Server,提交 Flink 集群的资源描述 文件,包括 configmap,job manager service,job manager deployment 和 Owner Reference。 2. Kubernetes Master 就会根据这些资源描述文件去创建对应的 Kubernetes 实体。以我们最关心的 job manager deployment 为例,Kubernetes 集 群中的某个节点收到请求后,Kubelet 进程会从中央仓库下载 Flink 镜像, 准备和挂载 volume,然后执行启动命令。在 flink master 的 pod 启动后, Dispacher 和 KubernetesResourceManager 也都启动了。 前面两步完成后,整个 Flink session cluster 就启动好了,可以接受提交任务 请求了。 1. 用户可以通过 Flink 命令行即 flink client 往这个 session cluster 提交任 务。此时 job graph 会在 flink client 端生成,然后和用户 jar 包一起通过 RestClinet 上传。 2. 一旦 job 提交成功,JobSubmitHandler 收到请求就会提交 job 给 Dispatcher。接着就会生成一个 job master。 3. JobMaster 向 KubernetesResourceManager 请求 slots。 4. KubernetesResourceManager 从 Kubernetes 集群分配 TaskManager。 每个 TaskManager 都是具有唯一表示的 Pod。KubernetesResourceManager 会 为 TaskManager 生 成 一 份 新 的 配 置 文 件, 里 面 有 Flink Master 的 service name 作为地址。这样在 Flink Master failover 之后, TaskManager 仍然可以重新连上。 5. Kubernetes 集群分配一个新的 Pod 后,在上面启动 TaskManager。 6. TaskManager 启动后注册到 SlotManager。 7. SlotManager 向 TaskManager 请求 slots。 8. TaskManager 提供 slots 给 JobMaster。然后任务就会被分配到这个 slots 上运行。
工作原理如下(段首的序号对应图中箭头所示的数字): 1. Flink 客户端首先连接 Kubernetes API Server,提交 Flink 集群的资源描述 文件,包括 configmap,job manager service,job manager deployment 和 Owner Reference。 2. Kubernetes Master 就会根据这些资源描述文件去创建对应的 Kubernetes 实体。以我们最关心的 job manager deployment 为例,Kubernetes 集 群中的某个节点收到请求后,Kubelet 进程会从中央仓库下载 Flink 镜像, 准备和挂载 volume,然后执行启动命令。在 flink master 的 pod 启动后, Dispacher 和 KubernetesResourceManager 也都启动了。 前面两步完成后,整个 Flink session cluster 就启动好了,可以接受提交任务 请求了。 1. 用户可以通过 Flink 命令行即 flink client 往这个 session cluster 提交任 务。此时 job graph 会在 flink client 端生成,然后和用户 jar 包一起通过 RestClinet 上传。 2. 一旦 job 提交成功,JobSubmitHandler 收到请求就会提交 job 给 Dispatcher。接着就会生成一个 job master。 3. JobMaster 向 KubernetesResourceManager 请求 slots。 4. KubernetesResourceManager 从 Kubernetes 集群分配 TaskManager。 每个 TaskManager 都是具有唯一表示的 Pod。KubernetesResourceManager 会 为 TaskManager 生 成 一 份 新 的 配 置 文 件, 里 面 有 Flink Master 的 service name 作为地址。这样在 Flink Master failover 之后, TaskManager 仍然可以重新连上。 5. Kubernetes 集群分配一个新的 Pod 后,在上面启动 TaskManager。 6. TaskManager 启动后注册到 SlotManager。 7. SlotManager 向 TaskManager 请求 slots。 8. TaskManager 提供 slots 给 JobMaster。然后任务就会被分配到这个 slots 上运行。
实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。


