
python: "too many values to unpack" ?报错
代码:
__author__ = 'Kevin'
import random
rawdata = open("D:/recommend/ml-100k/u.data")
def SplitData(data, M, k, seed) :
test = []
train = []
random.seed(seed)
for user, item in data :
if random.randint(0,M) == k:
test.append([user,item])
else:
train.append([user,item])
return train, test
if __name__ == "__main__":
SplitData(rawdata,8,5,4)
这个数据集是Movielens里100000份电影评分数据,报错如下,请问怎么解决?:
C:\Python27\python.exe D:/recommend/read.py
Traceback (most recent call last):
File "D:/recommend/read.py", line 18, in <module>
SplitData(rawdata,8,5,4)
File "D:/recommend/read.py", line 10, in SplitData
for user, item in data :
ValueError: too many values to unpack
u.data前几行数据如下:
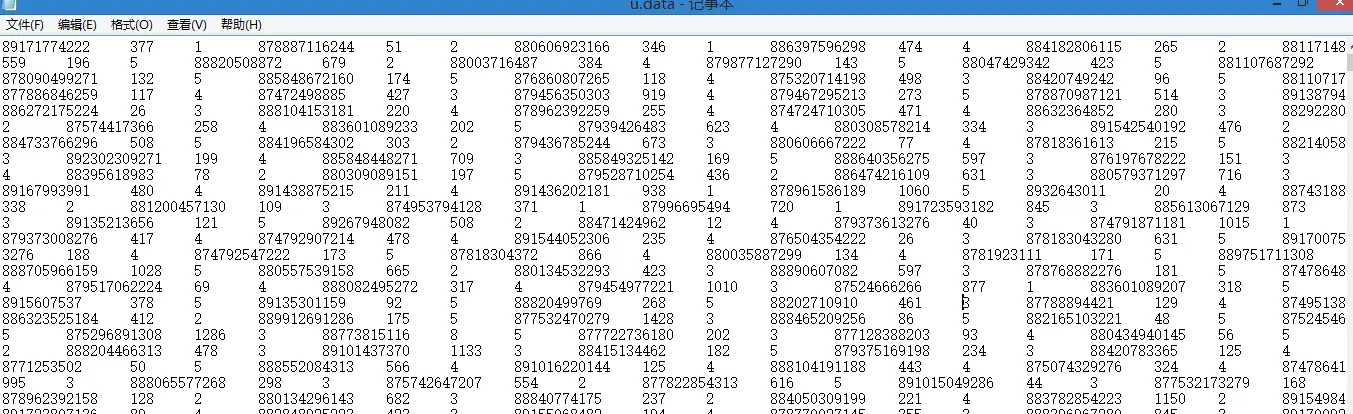
展开
收起
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
1
条回答
写回答
-
https://developer.aliyun.com/profile/5yerqm5bn5yqg?spm=a2c6h.12873639.0.0.6eae304abcjaIB
u.data每一行有两列数据?
forlineindata:user,item=line.split()[:2]
回复 @lakerl:感觉也没有明确的换行,那你只有把每一行读取出来split,然后extend到一个列表里面,最后再对这个列表进行处理数据集三个一组,分别是user,item,ratings(评分)回复 @lakerl:关键是你的user和item代表什么?在文件中怎么对应的不是,我把u.data前几行数据截图上传了,你看下1.换一个带行号的正常的编辑器(记事本去死,去看看SublimeText,Notepad++)吧……你这样叫我怎么知道每一行到底是什么格式中间白白的是空格还是Tab啊……
2.如果你的格式是:
user item ratings(换行) user item ratings
这样写:
foreach_lineindata:
user,item,_=each_line.split()
如果你数据其实就一行,可以简单粗暴地这么写:
all_data=data.read()
foruser,item,_inzip(all_data[0::3),all_data[1::3],all_data[2::3]): #稍大数据性能会很低,可以尝试做成iter
for user,itemin data.items():数据格式太乱了字符串需要split成2份才能赋值给2个变量。
2020-06-14 22:42:35赞同 展开评论
相关问答