
在采集一个视频资讯网站时发现其用了防盗链和爬虫、禁用cookies会报错,完全模拟采集后全是乱码。
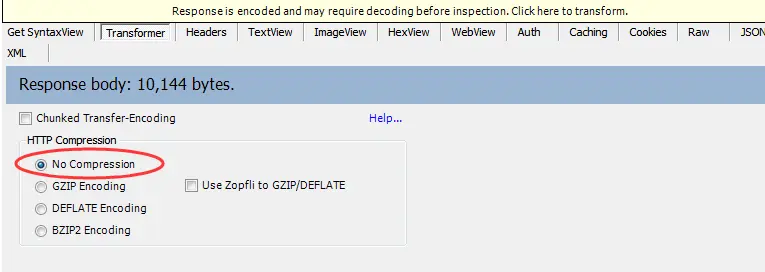
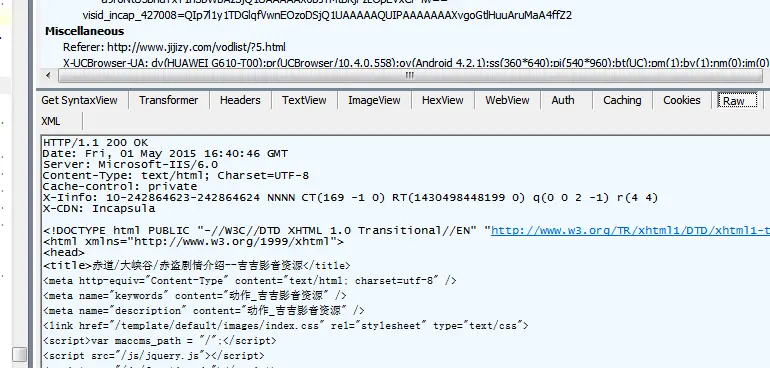
用fillder抓包设置no compression 之后就可以看到正常的HTML代码了,不知道这是社么原理,如何解决?
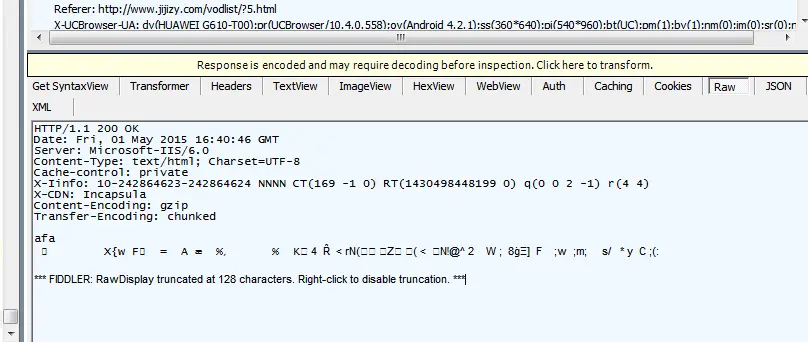
点击no compression后能正常显示HTML
<?php
header('content-type:text/html;charset=utf8');
set_time_limit(0);
$curl = curl_init('http://www.jijizy点com/vod/?24229.html');
$header = array();
$header[] = 'Host: www.jijizy.com';
$header[] = 'Referer: http://www.jijizy点com/vodlist/?5.html';
$header[] = 'Accept-Encoding: gzip';
$header[] = 'Accept-Language: zh-CN';
$header[] = 'Cookie: ASPSESSIONIDCQSCBQTQ=KENHHCCBNJIHOENLHOPPDDEP; visid_incap_427008=QIp7l1y1TDGlqfVwnEOzoDSjQ1UAAAAAQUIPAAAAAAAXvgoGtlHuuAruMaA4ffZ2; incap_ses_260_427008=a9roNtU3BnuYxY1nSbWbAzSjQ1UAAAAAX0bJTMtBKjPzLOpEVxCP4w==';
$header[] = 'Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8,UC/145,plugin/1,alipay/un';
$header[] = 'Connection: keep-alive';
$header[] = 'X-UCBrowser-UA: dv(HUAWEI G610-T00);pr(UCBrowser/10.4.0.558);ov(Android 4.2.1);ss(360*640);pi(540*960);bt(UC);pm(1);bv(1);nm(0);im(0);sr(0);nt(2);';
curl_setopt($curl, CURLOPT_HTTPHEADER, $header);
// 不输出header头信息
curl_setopt($curl, CURLOPT_HEADER, 0);
// 伪装浏览器
//curl_setopt($curl, CURLOPT_USERAGENT, 'Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2272.118 Safari/537.36');
// 保存到字符串而不是输出
curl_setopt($curl, CURLOPT_RETURNTRANSFER, 1);
$rs = curl_exec($curl);
curl_close($curl);
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
cookie不应该提前设置.应该是去第一次抓取页面的时候保存COOKIE不是这个的问题gzip压缩了,并不是乱码的问题回复<aclass='referer'target='_blank'>@wsy5344:请求header中不要加:Accept-Encoding即可。这个怎么解决压缩后的数据,设置好header头就可以解决。<atarget="_blank"rel="nofollow">http://blog.ppsql.net/index.php?keyword=采集
把$header[]='Accept-Encoding:gzip';去掉
