
Python PDFminer读取PDF内容速度慢是怎么回事?如何解决?:报错
根据网上的Python读取PDF的相关资料,TZ发现了PDFminer这个Python库,但是当我将其用来读取一个约300MB左右,页数在4000左右的PDF文件时,速度真心感人,一个小时大概读取了2000页,也就是一半的内容,这肯定不是我所预期的样子。时间太太太长了。求Python大佬教教小弟如何优化这个问题。万分感谢
下图为PDFminer读取PDF代码
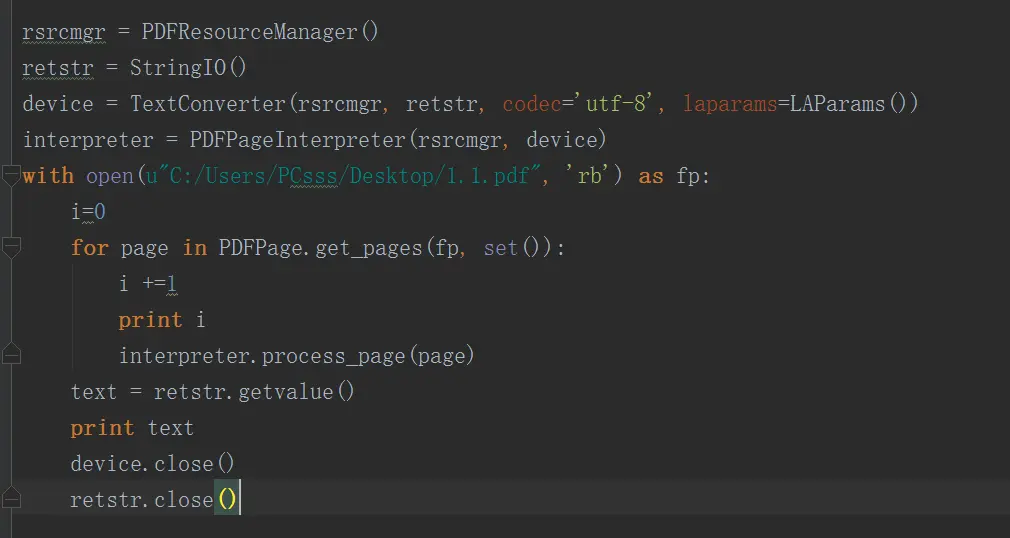
展开
收起
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
1
条回答
写回答
-
在一个月后的今天,把这个问题解决了。换掉了这个三方库,使用的XPD来读取PDF,速度比这个快太多了。
######大哥,XPD是什么库,具体名字叫什么?######多核
######谢谢你的回答,请问多核是什么意思呢?多进程读取么?还是?求大佬赐教2020-06-07 21:32:39赞同 展开评论

相关问答