
利用内存多叉树实现Ext JS中的无限级树形菜单(一种构建多级有序树形结构JSON的方法)? 400 报错
利用内存多叉树实现Ext JS中的无限级树形菜单(一种构建多级有序树形结构JSON的方法)
目前在Web应用程序开发领域,Ext JS框架已经逐渐被广泛使用,它是富客户端开发中出类拔萃的框架之一。在Ext的UI控件中,树形控件无疑是最为常用的控件之一,它用来实现树形结构的菜单。TreeNode用来实现静态的树形菜单,AsyncTreeNode用来实现动态的异步加载树形菜单,后者最为常用,它通过接收服务器端返回来的JSON格式的数据,动态生成树形菜单节点。生成树有两种思路,一种是一次性生成全部树节点,另一种是异步加载树节点(branch-by-branch)。对于大数据量的菜单节点来说,异步加载是比较合适的选择,但是对于小数据量的菜单来说,一次性生成全部节点应该是最为合理的方案,在实际应用开发中,一般不会遇到特别大数据量的场景,所以一次性生成全部菜单节点是我们重点研究的技术点,本文就是介绍基于Ext JS的应用系统中如何将数据库中的无限级层次数据一次性在界面中生成全部菜单节点(例如在界面中以树形方式一次性展示出银行所有分支机构的信息),同时对每一个层次的菜单节点按照某一属性和规则排序,展示出有序的菜单树。
解决Ext JS无限级树形菜单的问题,可以拓展出更多的应用场景,例如BI(商业智能)系统中的报表分析中的数据钻取功能,也就是多级数据列表的展示,同时对多级数据列表按照某一列数据进行排序;或者可以利用本文的思路扩展出其他的更复杂的应用场景。
让我们先看一段代码片段:
文件一,branchTree.html (Ext树形控件页面)
Ext.onReady(
function(){
var tree = new Ext.tree.TreePanel({
height: 300,
width: 400,
animate:true,
enableDD:true,
containerScroll: true,
rootVisible: false,
frame: true,
loader: new Ext.tree.TreeLoader({dataUrl:'getBranch.do'}), // getBranch.do请求服务器返回无限级的JSON字符串
root : new Ext.tree.AsyncTreeNode({id:'0',text:'根结点'})
});
tree.expandAll();
}
);
文件二,branchTreeJSON.jsp (接收getBranch.do请求,返回无限级JSON字符串)
<%
// 读取银行分支机构的层次数据
List result = DataAccess.getResultList();
// 将层次数据转换为内存多叉树对象(本文下面会详细介绍该数据结构的实现方法)
Node root = ExtTreeHelper.createExtTree(result);
%>
[
<%=root.toString()%> <!-- 以JSON的形式返回响应数据,Ext.tree.TreeLoader会根据此数据生成树形菜单 -->
]
以上两个程序文件是一次性生成无限级树形菜单所必须的,其中最为关键的部分就是如何生成一个无限级的JSON字符串,返回给客户端的Ext树形控件。对于银行分支机构来说,需要返回类似如下的JSON串:
{
id : '100000',
text : '廊坊银行总行',
children : [
{
id : '110000',
text : '廊坊分行',
children : [
{
id : '113000',
text : '廊坊银行开发区支行',
leaf : true
},
{
id : '111000',
text : '廊坊银行金光道支行',
leaf : true
},
{
id : '112000',
text : '廊坊银行解放道支行',
children : [
{
id : '112200',
text : '廊坊银行三大街支行',
leaf : true
},
{
id : '112100',
text : '廊坊银行广阳道支行',
leaf : true
}
]
}
]
}
]
}
同时还可能需要对树中每一个层次的节点按照某一属性(比如分支机构编号)进行排序,以展示出有序的树形菜单。
现在可以把问题概括为:
1、 把层次数据转换成JSON格式的字符串
2、 对树中每一个层次的节点按照某一属性(比如分支机构编号)进行排序
下面介绍解决问题的思路:
在数据结构这门课中,我们都学过二叉树和B树,二叉树属于内存数据结构,B树属于外存数据结构,我们的问题只涉及到内存操作,所以和B树无关,但是无限级树形菜单无法用二叉树来表示,因为每个节点下面都会有多个子节点,所以需要设计一种新的数据结构,用来表示这种多叉树结构,同时还要实现横向排序,即对隶属于同一个父节点下面的所有直接子节点按照某一节点属性和规则进行排序,保持兄弟节点横向有序。如图所示:
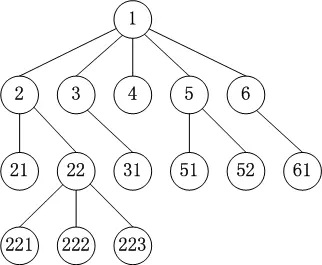
这棵树构造好之后,就可以通过纵向遍历(深度遍历)递归打印出无限级JSON字符串了。
为了区别它和B树(一种外存多叉树),可以称它为内存多叉树。
概括起来分为三步:
1、 构造无序的内存多叉树
2、 实现兄弟节点横向排序方法
3、 实现深度遍历方法,打印出JSON字符串
三、源代码实现(Java语言版)
实现这样一颗树,需要设计三个类:树类(ExtTree.java)、节点类(Node.java)、孩子列表类(Children.java);为了方便演示,还需要构造一些假的层次数据,因此还需要建一个构造假数据的类(VirtualDataGenerator.java),以下代码拷贝出来之后可直接运行测试:
package test;
import java.util.ArrayList;
import java.util.Comparator;
import java.util.HashMap;
import java.util.Iterator;
import java.util.List;
import java.util.Map;
import java.util.Set;
import java.util.Collections;
/**
* 树类
*/
public class ExtTree {
public static void main(String[] args) {
// 读取层次数据结果集列表
List dataList = VirtualDataGenerator.getVirtualResult();
// 节点列表(哈希表,用于临时存储节点对象)
HashMap nodeList = new HashMap();
// 根节点
Node root = null;
// 根据结果集构造节点列表(存入哈希表)
for (Iterator it = dataList.iterator(); it.hasNext();) {
Map dataRecord = (Map) it.next();
Node node = new Node();
node.id = (String) dataRecord.get("id");
node.text = (String) dataRecord.get("text");
node.parentId = (String) dataRecord.get("parentId");
nodeList.put(node.id, node);
}
// 构造无序的内存多叉树
Set entrySet = nodeList.entrySet();
for (Iterator it = entrySet.iterator(); it.hasNext();) {
Node node = (Node) ((Map.Entry) it.next()).getValue();
if (node.parentId == null || node.parentId.equals("")) {
root = node;
} else {
((Node) nodeList.get(node.parentId)).children.addChild(node);
}
}
// 输出无序的树形菜单的JSON字符串
System.out.println(root.toString());
// 对内存多叉树进行横向排序
root.sortChildren();
// 输出有序的树形菜单的JSON字符串
System.out.println(root.toString());
// 程序输出结果如下(无序的树形菜单)(格式化后的结果):
//{
// id : '100000',
// text : '廊坊银行总行',
// children : [
// {
// id : '110000',
// text : '廊坊分行',
// children : [
// {
// id : '113000',
// text : '廊坊银行开发区支行',
// leaf : true
// },
// {
// id : '111000',
// text : '廊坊银行金光道支行',
// leaf : true
// },
// {
// id : '112000',
// text : '廊坊银行解放道支行',
// children : [
// {
// id : '112200',
// text : '廊坊银行三大街支行',
// leaf : true
// },
// {
// id : '112100',
// text : '廊坊银行广阳道支行',
// leaf : true
// }
// ]
// }
// ]
// }
// ]
//}
// 程序输出结果如下(有序的树形菜单)(格式化后的结果):
//{
// id : '100000',
// text : '廊坊银行总行',
// children : [
// {
// id : '110000',
// text : '廊坊分行',
// children : [
// {
// id : '111000',
// text : '廊坊银行金光道支行',
// leaf : true
// },
// {
// id : '112000',
// text : '廊坊银行解放道支行',
// children : [
// {
// id : '112100',
// text : '廊坊银行广阳道支行',
// leaf : true
// },
// {
// id : '112200',
// text : '廊坊银行三大街支行',
// leaf : true
// }
// ]
// },
// {
// id : '113000',
// text : '廊坊银行开发区支行',
// leaf : true
// }
// ]
// }
// ]
//}
}
}
/**
* 节点类
*/
class Node {
/**
* 节点编号
*/
public String id;
/**
* 节点内容
*/
public String text;
/**
* 父节点编号
*/
public String parentId;
/**
* 孩子节点列表
*/
public Children children = new Children();
// 深度遍历,拼接JSON字符串
public String toString() {
String result = "{"
+ "id : '" + id + "'"
+ ", text : '" + text + "'";
if (children != null && children.getSize() != 0) {
result += ", children : " + children.toString();
} else {
result += ", leaf : true";
}
return result + "}";
}
// 对子节点进行横向排序
public void sortChildren() {
if (children != null && children.getSize() != 0) {
children.sortChildren();
}
}
}
/**
* 孩子列表类
*/
class Children {
public List lis
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
写的不错######
补充一些东西:
这是本文的详细数据结构图,如下:
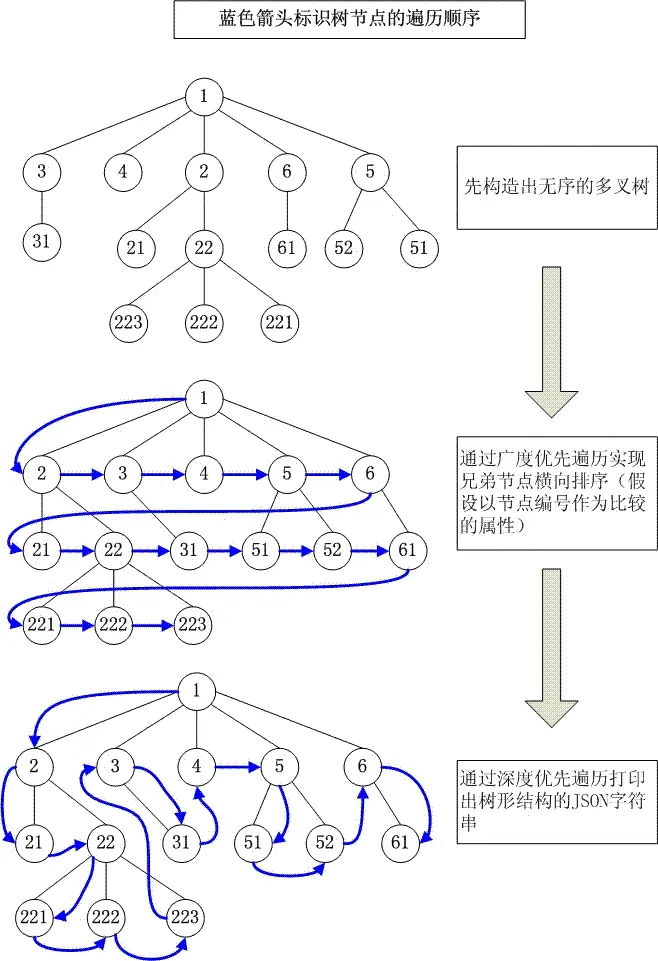
由于这棵树实现了广度优先遍历和深度优先遍历,所以可以称它为“全历树”。
######
再补充一些东西:
这是本文的数据结构图(修改后的),如下:

由于这棵树使用了广度优先遍历和深度优先遍历,实现了树的双遍历,所以可以简称它为“双历树”。
######
看两个图例,有个直观上的认识:
图一,银行分支机构树形结构菜单
图二,BI(商业智能)树形结构报表
