
今天主要来聊两个问题:给一个数组,如何同时求出最大值和最小值,如何同时求出最大值和第二大值?
这两个问题看起来都特别简单,一个 for 循环,几个大小判断 if 语句不就行了嘛?其实不然,其中的细节操作十分精妙,渐进时间复杂度肯定是 O(n) 无法再减少,但如果深究算法的执行速度,仍然有优化空间。
相信你看完本文之后,会对分治思想和归纳思想有更深刻的认识,会对这种看似简单的问题另眼相看。
我们先按正常的思路,写出来两个问题的代码:
// 返回最大值和最小值
int[] max_and_min(int[] nums) {
int n = nums.length;
int max = nums[0];
int min = nums[0];
for (int i = 0; i < n; i++) {
if (nums[i] > max)
max = nums[i];
if (nums[i] < min)
min = nums[i];
}
return new int[]{max, min};
}
// 返回最大值和第二大值
int[] max1_and_max2(int[] nums) {
int n = nums.length;
int max1, max2;
max1 = max2 = Integer.MIN_VALUE;
for (int i = 0; i < n; i++) {
if (nums[i] > max1) {
max2 = max1;
max1 = nums[i];
} else if (nums[i] > max2) {
max2 = nums[i];
}
}
return new int[] {max1, max2};
}
显然两个算法的时间复杂度都是 O(n),但如果我们以 if 判断的次数作为算法效率的评估标准,算一下 for 循环中 if 语句的判断次数:
第一个算法显然需要固定2n次 if 比较,第二个算法最坏情况需要2n次 if 比较。
接下来,我们想办法优化这两个算法,使这两个算法只需要固定的1.5n次比较。
为啥一般的解法还能优化呢?**肯定是因为没有充分利用信息,存在冗余计算。**具体来说,看这两个 if 语句:
if (nums[i] > max) max = nums[i];if (nums[i] < min) min = nums[i];
当第一个 if 语句判定为 true 时,第二个 if 语句还需要执行吗?显然第二个 if 一定判定为 false,根本不需要执行了。
如何避免这种冗余计算提高效率呢?可以这样,对于索引变量i,每次向前步进 2 个元素,先比较这两个元素的大小,然后大的那个去和max比较,小的那个去和min比较,代码如下:
int[] max_and_min(int[] nums) {
int max = nums[0];
int min = nums[0];
// 每次步进两个元素
for (int i = 0; i < nums.length; i += 2) {
if (nums[i] > nums[i + 1]) {
max = Math.max(max, nums[i]);
min = Math.min(min, nums[i + 1]);
} else {
max = Math.max(max, nums[i + 1]);
min = Math.min(min, nums[i]);
}
}
return new int[]{max, min};
}
这样的话,每次 for 循环需要 3 次大小比较(if 一次,Math.max/min共两次),for 循环需要进行n/2次,那么总共的比较次数就是1.5n次了。
PS:清晰起见,这里假设数组大小n是偶数,奇数的话在最后增加一个判断即可,这里就不处理了。
对于这个问题,还有另一种优化方法,那就是分治算法。大致的思路是这样:
先将数组分成两半,分别找出这两半数组的最大值和最小值,然后max就是两个最大值中更大的那个,min就是两个最小值中更小的那个。
分治算法涉及递归,时间复杂度仍然是1.5n,和上面这个算法效率一样,这里就不实现了。下个问题来用分治算法递归实现,看完之后你应该可以自己用分治思想解决这个问题了。
这个问题咋分治呢?分治思想的套路就是分而治之,先把原问题不断平分成两个子问题,然后通过子问题的答案得到原问题的答案。
具体到这个问题来说,我们把nums中的元素视为集合A,先将集合A平分为两个集合P和Q,分别求出P,Q中的最大元素和第二大元素(称为p1, p2和q1, q2),然后通过这 4 个数字得到集合A的最大元素和第二大元素(称为max1和max2)。具体实现直接看代码:
int[] max1_and_max2(int[] nums) { return divide_conquer(nums, 0, nums.length);}// 返回集合 A 在索引区间 [i, j) 的最大元素和第二大元素int[] divide_conquer(int[] A, int i, int j) { // base case if (j - i == 2) { if (A[i] < A[i + 1]) { return new int[] {A[i + 1], A[i]}; } else { return new int[] {A[i], A[i + 1]}; } } // 解决两个子问题 int[] left = divide_conquer(A, i, (i + j) / 2); int[] right = divide_conquer(A, (i + j) / 2, j); int p1 = left[0], p2 = left[1]; int q1 = right[0], q2 = right[1]; // 通过子问题的结果合并原问题的答案 // 有点绕,后文有解释 int max1, max2; if (p1 > q1) { max1 = p1; max2 = Math.max(p2, q1); } else { max1 = q1; max2 = Math.max(q2, p1); } return new int[] {max1, max2};}
为了清晰起见,假设数组的大小都是 2 的幂,以省去一些边界处理代码。解释一下由子问题的答案合并原问题的答案的逻辑:
if (p1 > q1) { max1 = p1; max2 = Math.max(p2, q1);} else {...}
首先肯定是两个子集中的最大值比较,如果p1比q1大,p1显然就是原集合A的最大值;此时就不用考虑q2了,因为q1大于q2,第二大的值只需要在q1和p2中选择即可。else 分支同理。
因此,算法在 if else 的比较次数为 2,总的时间复杂度是多少呢?这就涉及递归算法的复杂度分析,设算法的复杂度为 (n为递归函数处理的元素个数,或者称为问题规模),那么可以得到如下公式:
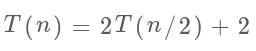
其中是因为 2 个子问题的递归调用,每个子问题的规模是原来的 1/2;之后加 2 是每次合并子问题结果得到原问题结果时进行的 2 次大小判断。
递归的** base case **是,意思是如果问题规模只有 2,一次大小比较即可得到结果,代码中有体现。
这个递归式如何解出答案呢?有很多方法,比如说高中学过的「特征方程」,或者算法分析常用的「主定理」等等,对于这个问题很容易解,这里就直接写答案了:
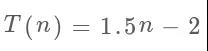
可见分治法解决这个问题的比较次数基本上是1.5n,比一开始的算法最坏情况下2n的比较次数要好一些。
PS:其实这个分治算法可以再优化,比较次数可以进一步降到 n + log(n),但是稍微有点麻烦,所以这里就不展开了。
对于第一个求最大值和最小值的问题的分治算法和这道题基本一样,只是最后合并子问题答案的部分不同,而且更简单,读者可以尝试写一下第一题的分治解法。
肯定有读者会问,以上这些解法到底是怎么想出来的,有规律可循还是单纯的奇技淫巧?
首先,分治算法是一种比较常用的套路,一般都是把原问题一分为二,然后合并两个问题的答案。如果可以利用分治解决问题,复杂度一般可以优化,比如以上两个问题,分治法复杂度都是1.5n,比一般解法要好。
其次,对于同时求最大值最小值的那个问题,怎么想到一次前进 2 步的呢?这个其实也是有技巧的,这就是「归纳技巧」。
我们公众号之前有很多讲动态规划的文章,其中 动态规划设计之最长递增子序列 就写过,写状态转移方程的方法就是数学归纳法,其实归纳法不止适用于动态规划,很多算法问题都有归纳思想的影子,可以认为递归算法都是运用归纳思想。
但是第一个问题我们并没有递归呀,我们是一个 for 循环遍历数组的呀?习惯上是这样,但如果你愿意,可以把迭代改成递归:
// 返回最大值和最小值
int[] max_and_min(int[] nums) {
return helper(nums, nums.legnth - 1);
}
// 返回在区间 [0, n] 中的最大值和最小值
int[] helper(int[] nums, int n) {
// base case
if (n == 1) {
if (nums[0] > nums[1])
return (nums[0], nums[1]);
else
return (nums[1], nums[0]);
}
int preMax, preMin;
(preMax, preMin) = helper(nums, n - 1);
// 进行两次大小比较
int max, min;
max = Math.max(preMax, nums[n]);
min = Math.min(preMin, nums[n]);
return (max, min);
}
这段代码是那个一般解法的递归版本,复杂度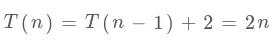 ,有 base case,有递归逻辑:
,有 base case,有递归逻辑:
我现在想解决原问题f(n),假设知道了子问题f(n-1)的结果,就可以得到原问题的结果。
如果你能明白这个递归关系(归纳假设),就有可能想到每次前进 2 步的优化解法。归纳假设是可以随意加强、减弱的,现在我们是假设已知f(n-1)去求f(n),那么不妨试试假设已知f(n-2)或f(n-3)去求f(n)?
最后可以发现,通过f(n-2)去推断f(n)是最高效的,写成迭代就是每次前进两步的 for 循环,复杂度为:
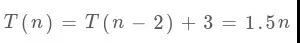
对于动态规划问题也是一样的,前文经常说对 dp 数组不同的定义可以得到完全不同的解法,这其实就是归纳假设。不同的定义都可以完成任务,但是效率可能会有差异,比方说这篇文章 动态规划:不同的定义产生不同的解法 就列举了一个例子。
来源 | github
作者 | labuladong
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
