
时间轮+磁盘存储是什么
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
什么是时间轮呢?其实我们可以简单的将其看做是一个多维数组。在很多框架中都使用了时间轮来做一些定时的任务,用来替代我们的Timer,比如我之前讲过的有关本地缓存Caffeine一篇文章,在Caffeine中是一个二层时间轮,也就是二维数组,其一维的数据表示较大的时间维度比如,秒,分,时,天等,其二维的数据表示该时间维度较小的时间维度,比如秒内的某个区间段。当定位到一个TimeWhile[i][j]之后,其数据结构其实是一个链表,记录着我们的Node。在Caffeine利用时间轮记录我们在某个时间过期的数据,然后去处理。 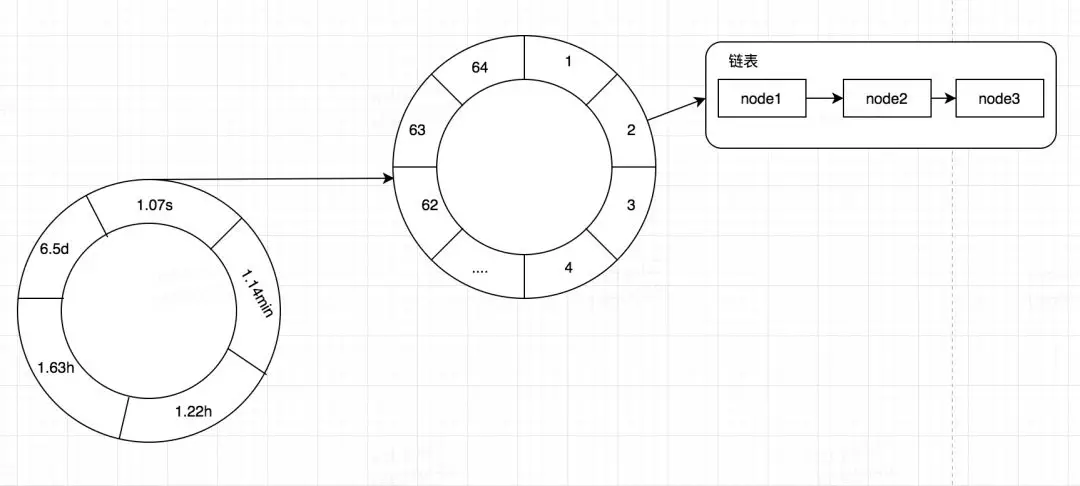
由于时间轮是一个数组的结构,那么其插入复杂度是O(1)。我们解决了效率之后,但是我们的内存依旧不是无限的,我们时间轮如何使用呢?答案当然就是磁盘,在去哪儿开源的QMQ中已经实现了时间轮+磁盘存储,这里为了方便描述我将其转化为RocketMQ中的结构来进行讲解,实现图如下:
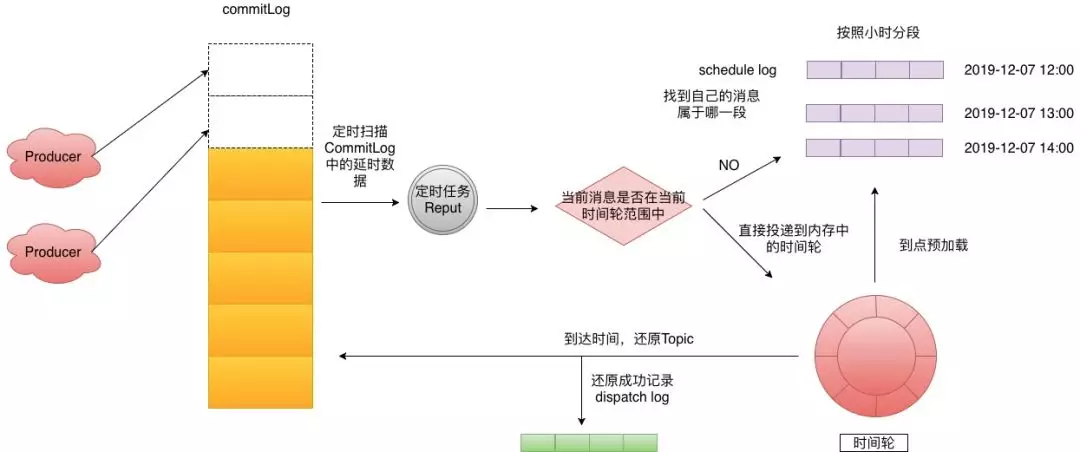
Step 1: 生产者投递延时消息到CommitLog,这个时候使用了偷换Topic的那招,来达到后面的效果。
Step 2: 后台有一个Reput的任务定时拉取,延时Topic相关的Message。
Step 3: 判断这个Message是否在当前时间轮范围中,如果不在则来到Step4,如果在的话就直接将消息投递进入时间轮。
Step 4: 找到当前消息所属的scheduleLog,然后写入进去,去哪儿默认划分是一个小时为一段,这里可以根据业务自行调整。
Step 5:时间轮会定时预加载下个时间段的scheduleLog到内存。
Step 6: 到点的消息会还原topic再次投递到CommitLog,如果投递成功这里会记录dispatchLog。记录的原因是因为时间轮是内存的,你不知道已经执行到哪个位置了,如果执行到最后最后1s钟的时候挂了,这段时间轮之前的所有数据又得重新加载,这里是用来过滤已经投递过的消息。
时间轮+磁盘存储我个人觉得比上面的RocksDB要更加正统一点,不依赖其他的中间件就可以完成,可用性自然也就更高,当然阿里云的RocketMQ具体怎么实现的这个两种方案都有可能。

