
整个内容分为四个部分,首先就是讲一下 Go 在工程里面的一些组织结构,比方工程是怎么组织的,每一个服务是怎么组织的,每一些服务有一些什么样的角色。第二个的话我们会讲一下在 Go 里面的一些单元测试在我厂的一些实践。第三块的话就是,我们把之前做的一些这种工具化或者约定一些规范,能不能把它变成一些工具链的思考。最后的话简单提一下我自己对配置文件的一些理解。
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
Layout
Go工程项目的整体组织
首先我们看一下整个 Go 工程是怎么组织起来的。
很多同事都在用 GitLab 的,GitLab 的一个 group 里面可以创建很多 project。如果我们进行微服务化改造,以前很多巨石架构的应用可能就拆成了很多个独立的小应用。那么这么多小应用,你是要建 N 个 project 去维护,还是说按照部门或者组来组织这些项目呢?在 B 站的话,我们之前因为是 Monorepo,现在是按照部门去组织管理代码,就是说在单个 GitLab 的 project 里面是有多个 app 的,每一个 app 就表示一个独立的微服务,它可以独立去交付部署。所以说我们看到下面这张图里面,app 的目录里面是有好多个子目录的,比方说我们的评论服务,会员服务。跟 app 同级的目录有一个叫 pkg,可以存放业务有关的公共库。这是我们的一个组织方式。当然,还有一种方式,你可以按照 GitLab 的 project 去组织,但我觉得这样的话可能相对要创建的 project 会非常多。
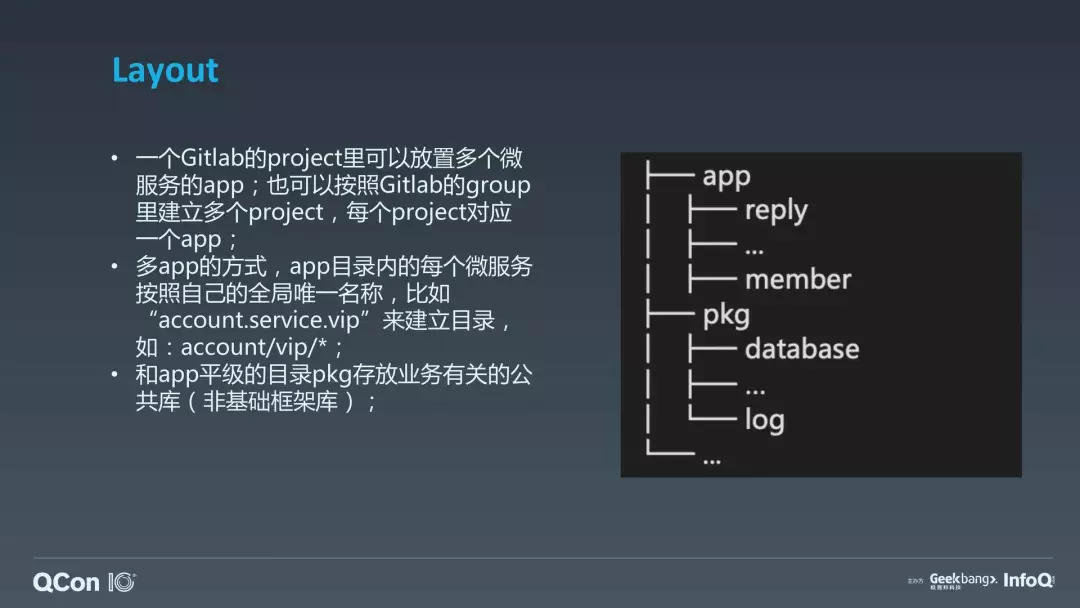
如果你按部门组织的话,部门里面有很多 app,app 目录怎么去组织?我们实际上会给每一个 app 取一个全局唯一名称,可以理解为有点像 DNS 那个名称。我们对业务的命名也是一样的,我们基本上是三段式的命名,比如账号业务,它是一个账号业务、服务、子服务的三段命名。三段命名以后,在这个 app 目录里面,你也可以按照这三层来组织。比如我们刚刚说的账号目录,我可能就是 account 目录,然后 VIP,在 VIP 目录下可能会放各种各样的不同角色的微服务,比方说可能有一些是做 job,做定时任务或者流式处理的一些任务,有可能是做对外暴露的 API 的一些服务,这个就是我们关于整个大的 app 的组织的一种形式。
微服务中的 app 服务分类
微服务中单个 app 的服务里又分为几类不同的角色。我们基本上会把 app 分为 interface(BFF)、service、job(补充:还有一个 task,偏向定时执行,job 偏向流式) 和 admin。
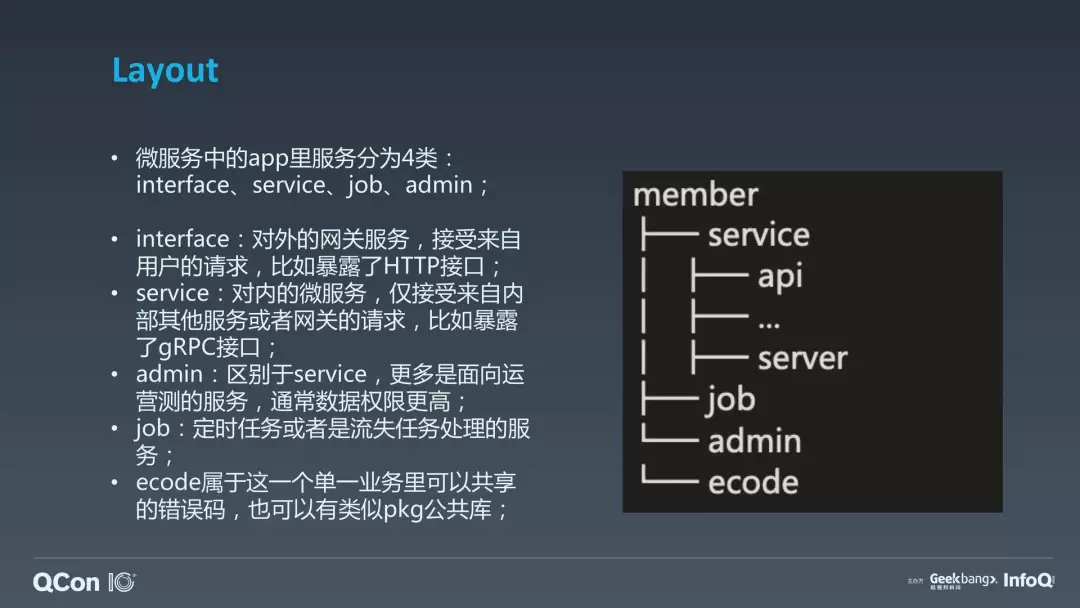
Interface 是对外的业务网关服务,因为我们最终是面向终端用户的 API,面向 app,面向 PC 场景的,我们把这个叫成业务网关。因为我们不是统一的网关,我们可能是按照大的业务线去独立分拆的一些子网关,这个的话可以作为一个对外暴露的 HTTP 接口的一个目录去组织它的代码,当然也可能是 gRPC 的(参考 B 站对外的 gRPC Moss 分享)。
Service 这个角色主要是面向对内通信的微服务,它不直接对外。也就是说,业务网关的请求会转发或者是会 call 我们的内部的 service,它们之间的通讯可能是使用自己的 RPC,在 b 站我们主要是使用 gRPC。使用 gRPC 通讯以后,service 它因为不直接对外,service 之间可能也可以相互去 call。
Admin 区别于 service,很多应用除了有面向用户的一些接口,实际上还有面向企业内部的一些运营侧的需求,通常数据权限更高,从安全设计角度需要代码物理层面隔离,避免意外。
第四个是 ecode。我们当时也在内部争论了很久,我们的错误码定义到底是放在哪里?我们目前的做法是,一个应用里面,假设你有多种角色,它们可能会复用一些错误码。所以说我们会把我们的 ecode 给单独抽出来,在这一个应用里面是可以复用的。注意,它只在这一个应用里面复用,它不会去跨服跨目录应用,它是针对业务场景的一个业务错误码的组织。
App 目录组织
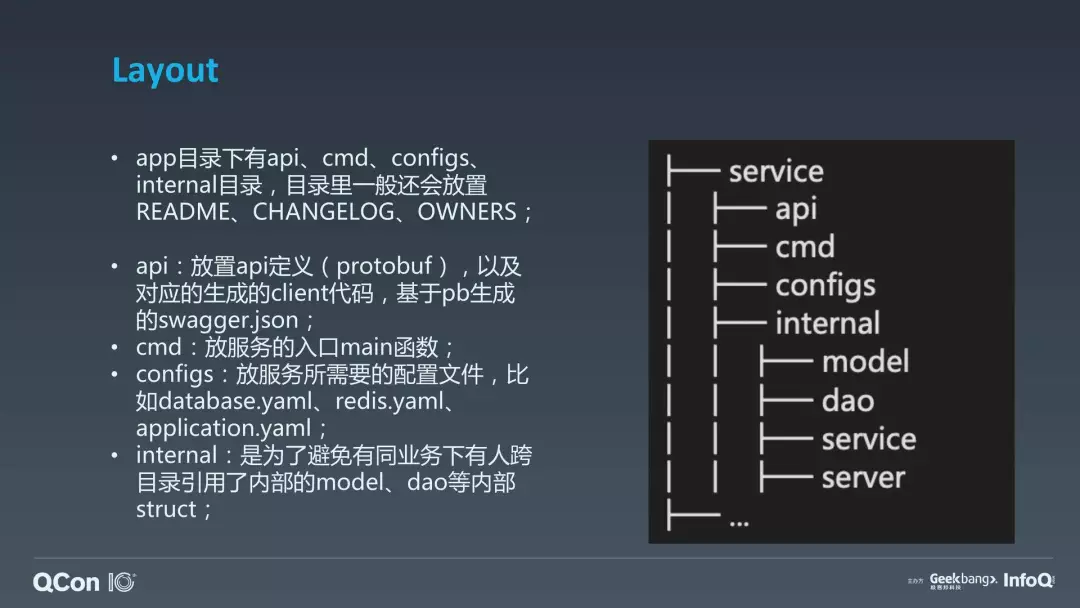
我们除了一个应用里面多种角色的这种情况,现在展开讲一下具体到一个 service 里面,它到底是怎么组织的。我们的 app 目录下大概会有 api、cmd、configs、 internal 目录,目录里一般还会放置 README、CHANGELOG、OWNERS。
API 是放置 api 定义以及对应的生成的 client 代码,包含基于 pb 定义(我们使用 PB 作为 DSL 描述 API) 生成的 swagger.json。
而 cmd,就是放 main 函数的。Configs 目录主要是放一些服务所需的配置文件,比方说说我们可能会使用 TOML 或者是使用 YAML 文件。
Internal 的话,它里面有四个子目录,分别是 model、dao、service 和 server。Model 的定位职责就是对我们底层存储的持久化层或者存储层的数据的映射,它是具体的 Go 的一个 struct。我们再看 dao,你实际就是要操作 MySQL 或者 Redis,最终返回的就是这些 model(存储映射)。Service 组织起来比较简单,就是我们通过 dao 里面的各个方法来完成一个完整的业务逻辑。我们还看到有个 server,因为我一个微服务有可能企业内部不一定所有 RPC 都统一,那我们处于过渡阶段,所以 server 里面会有两个小目录,一个是 HTTP 目录,暴露的是 HTTP 接口,还有一个是 gRPC 目录,我们会暴露 gRPC 的协议。所以在 server 里面,两个不同的启动的 server,就是说一个服务和启动两个端口,然后去暴露不同的协议,HTTP 接 RPC,它实际上会先 call 到 service,service 再 call 到 dao,dao 实际上会使用 model 的一些数据定义 struct。但这里面有一个非常重要的就是,因为这个结构体不能够直接返回给我们的 api 做外对外暴露来使用,为什么?因为可能从数据库里面取的敏感字段,当我们实际要返回到 api 的时候,可能要隐藏掉一些字段,在 Java 里面,会抽象的一个叫 DTO 的对象,它只是用来传输用的,同理,在我们 Go 里面,实际也会把这些 model 的一些结构体映射成 api 里面的结构体(基于 PB Message 生成代码后的 struct)。
Rob Pike 当时说过的一句话,a little copying is better than a little dependency,我们就遵循了这个理念。在我们这个目录结构里面,有 internal 目录,我们知道 Go 的目录只允许这个目录里面的人去 import 到它,跨目录的人实际是不能直接引用到它的。所以说,我们看到 service 有一个 model,那我的 job 代码,我做一些定时任务的代码或者是我的网关代码有可能会映射同一个 model,那是不是要把这个 model 放到上一级目录让大家共享?对于这个问题,其实我们当时内部也争论过很久。我们认为,每一个微服务应该只对自己的 model 负责,所以我们宁愿去做一小部分的代码 copy,也不会去为了几个服务之间要共享这一点点代码,去把这个 model 提到和 app 目录级别去共用,因为你一改全错,当然了,你如果是拷贝的话,就是每个地方都要去改,那我们觉得,依赖的问题可能会比拷贝代码相对来说还是要更复杂的。
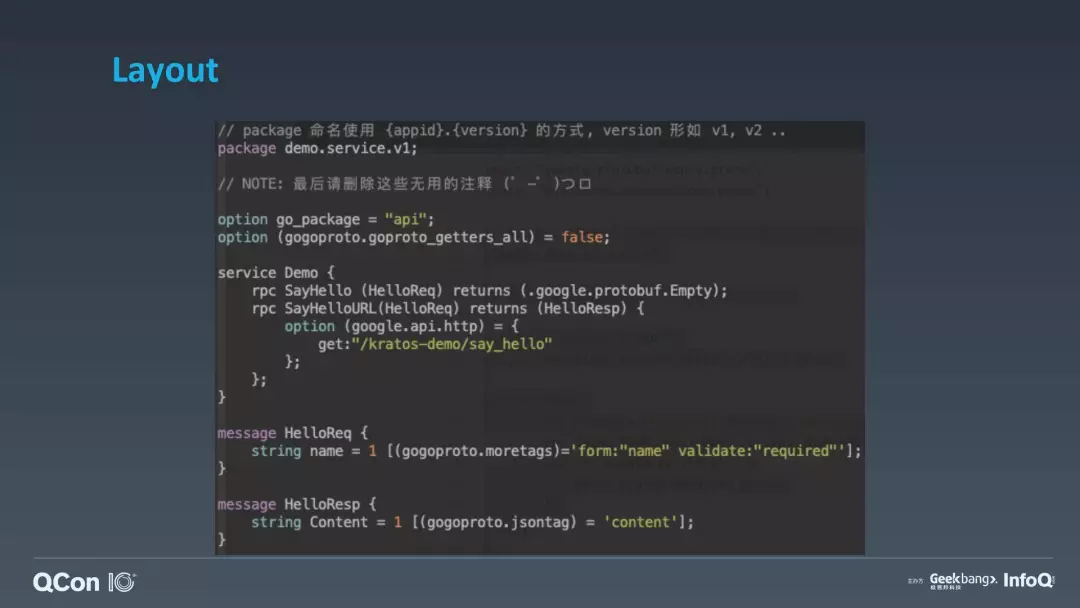
这个是一个标准的 PB 文件,就是我们内部的一个 demo 的 service。最上面的 package 是 PB 的包名,demo.service.v1,这个包使用的是三段式命名,全局唯一的名称。那这个名称为什么不是用 ID?我见过有些公司对内部做的 CMDB 或者做服务树去管理企业内部微服务的时候,是用了一些名称加上 ID 来搞定唯一性,但是我们知道后面那一串 ID 数字是不容易被传播或者是不容易被记住的,这也是 DNS 出来的一个意义,所以我们用绝对唯一的一个名称来表示这个包的名字,在后面带上这一个 PB 文件的版本号 V1。
我们看第二段定义,它有个 Service Demo 代码,其实就表示了我们这个服务要启动的服务的一个名称,我们看到这个服务名称里面有很多个 RPC 的方法,表示最终这一个应用或者这个 service 要对外暴露这几个 RPC 的方法。这里面有个小细节,我们看一下 SayHello 这个方法,实际它有 option 的一个选项。通过这一个 PB 文件,你既可以描述出你要暴露的是 gRPC 协议,又暴露出 HTTP 的一个接口,这个好处是你只需要一个 PB 文件描述你暴露的所有 api。我们回想一下,我们刚刚目录里面有个 api 目录,实际这里面就是放这一个 PB 文件,描述这一个工程到底返回的接口是什么。不管是 gRPC 还是 HTTP 都是这一个文件。还有一个好处是什么?实际上我们可以在 PB 文件里面加上很多的注释。用 PB 文件的好处是你不需要额外地再去写文档,因为写文档和写服务的定义,它本质上是两个步骤,特别容易不一致,接口改了,文档不同步。我们如果基于这一个 PB 文件,它生成的 service 代码或者调用代码或者是文档都是唯一的。
依赖顺序与 api 维护
就像我刚刚讲到的,model 是一个存储层的结构体的一一映射,dao 处理一些数据读写包,比方说数据库缓存,server 的话就是启动了一些 gRPC 或者 HTTP Server,所以它整个依赖顺序如下:main 函数启动 server,server 会依赖 api 定义好的 PB 文件,定义好这些方法或者是服务名之后,实际上生成代码的时候,比方说 protocbuf 生成代码的时候,它会把抽象 interface 生成好。然后我们看一下 service,它实际上是弱依赖的 api,就是说我的 server 启动以后,要注册一个具体的业务代码的逻辑,映射方法,映射名字,实际上是弱依赖的 api 生成的 interface 的代码,你就可以很方便地启动你的 server,把你具体的 service 的业务逻辑给注入到这个 server,和方法进行一一绑定。最后,dao 和 service 实际上都会依赖这个 model。
因为我们在 PB 里面定义了一些 message,这些 message 生成的 Go 的 struct 和刚刚 model 的 struct 是两个不同的对象,所以说你要去手动 copy 它,把它最终返回。但是为了快捷,你不可能每次手动去写这些代码,因为它要做 mapping,所以我们又把 K8s 里类似 DeepCopy 的两个结构体相互拷贝的工具给抠出来了,方便我们内部 model 和 api 的 message 两个代码相互拷贝的时候,可以少写一些代码,减少一些工作量。
上面讲的就是我们关于工程的一些 layout 实践。简单回溯一下,大概分为几块,第一就是 app 是怎么组织的,app 里面有多种角色的服务是怎么组织的,第三就是一个 app 里面的目录是怎么组织的,最后我重点讲了一下 api 是怎么维护的。
Unittest
测试方法论

现在回顾一下单元测试。我们先看这张图,这张图是我从《Google 软件测试之道》这本书里面抠出来的,它想表达的意思就是最小型的测试不能给我们的最终项目的质量带来最大的信心,它比较容易带来一些优秀的代码质量,良好的异常处理等等。但是对于一个面向用户场景的服务,你只有做大型测试,比方做接口测试,在 App 上验收功能的这种测试,你应用交付的信心可能会更足。这个其实要表达的就是一个“721 原则”。我们就是 70% 写小型测试,可以理解为单元测试,因为它相对来说好写,针对方法级别。20% 是做一些中型测试,可能你要连调几个项目去完成你的 api。剩下 10% 是大型测试,因为它是最终面向用户场景的,你要去使用我们的 App,或者用一些测试 App 去测试它。这个就是测试的一些简单的方法论。
单元测试原则

我们怎么去对待 Go 里面的单元测试?在《Google 软件测试之道》这本书里面,它强调的是对于一个小型测试,一个单元测试,它要有几个特质。它不能依赖外部的一些环境,比如我们公司有测试环境,有持续集成环境,有功能测试环境,你不能依赖这些环境构建自己的单元测试,因为测试环境容易被破坏,它容易有数据的变更,数据容易不一致,你之前构建的案例重跑的话可能就会失败。
我觉得单元测试主要有四点要求。第一,快速,你不能说你跑个单元测试要几分钟。第二,要环境一致,也就是说你跑测试前和跑测试后,它的环境是一致的。第三,你写的所有单元测试的方法可以以任意顺序执行,不应该有先后的依赖,如果有依赖,也是在你测试的这个方法里面,自己去 setup 和 teardown,不应该有 Test Stub 函数存在顺序依赖。第四,基于第三点,你可以做并行的单元测试,假设我写了一百个单元测试,一个个跑肯定特别慢。
doker-compose

最近一段时间,我们演进到基于 docker-compose 实现跨平台跨语言环境的容器依赖管理方案,以解决运行 unittest 场景下的容器依赖问题。
首先,你要跑单元测试,你不应该用 VPN 连到公司的环境,好比我在星巴克点杯咖啡也可以写单元测试,也可以跑成功。基于这一点,Docker 实际上是非常好的解决方式。我们也有同学说,其他语言有一些 in-process 的 mock,是不是可以启动 MySQL 的 mock ,然后在 in-process 上跑?可以,但是有一个问题,你每一个语言都要写一个这样的 mock ,而且要写非常多种,因为我们中间件越来越多,MySQL,HBase,Kafka,什么都有,你很难覆盖所有的组件 Mock。这种 mock 或者 in-process 的实现不能完整地代表线上的情况,比方说,你可能 mock 了一个 MySQL,检测到 query 或者 insert ,没问题,但是你实际要跑一个 transaction,要验证一些功能就未必能做得非常完善了。所以基于这个原因,我们当时选择了 docker-compose,可以很好地解决这个问题。
我们对开发人员的要求就是,你本地需要装 Docker,我们开发人员大部分都是用 Mac,相对来说也比较简单,Windows 也能搞定,如果是 Linux 的话就更简单了。本地安装 Docker,本质上的理解就是无侵入式的环境初始化,因为你在容器里面,你拉起一个 MySQL,你自己来初始化数据。在这个容器被销毁以后,它的环境实际上就满足了我们刚刚提的环境一致的问题,因为它相当于被重置了,也可以很方便地快速重置环境,也可以随时随地运行,你不需要依赖任何外部服务,这个外部服务指的是像 MySQL 这种外部服务。当然,如果你的单元测试依赖另外一个 RPC 的 service 的话,PB 的定义会生成一个 interface,你可以把那个 interface 代码给 mock 掉,所以这个也是能做掉的。对于小型测试来说,你不依赖任何外部环境,你也能够快速完成。
另外,docker-compose 是声明式的 API,你可以声明你要用 MySQL,Redis,这个其实就是一个配置文件,非常简单。这个就是我们在单元测试上的一些实践。
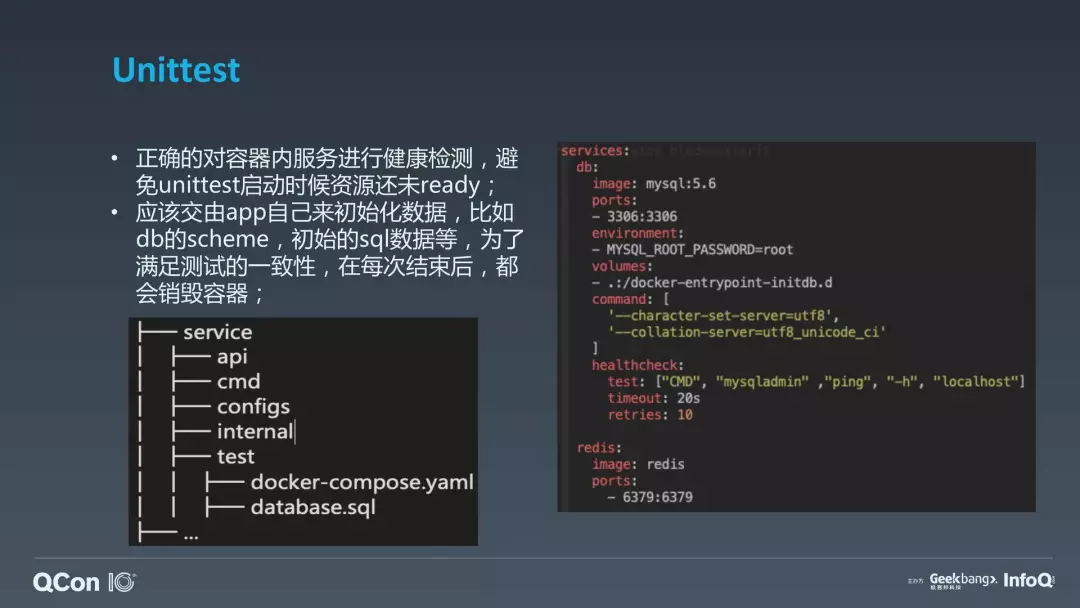
我们现在看一下,service 目录里面多了一个 test 目录,我们会在这个里面放 docker-compose 的 YAML 文件来表示这次单元化测试需要初始化哪些资源,你要构建自己的一些测试的数据集。因为是这样的,你是写 dao 层的单元测试的话,可能就需要 database.sql 做一些数据的初始化,如果你是做 service 的单元测试的话,实际你可以把整个 dao 给 mock 掉,我觉得反而还相对简单,所以我们主要针对场景就是在 dao 里面偏持久层的,利用 docker-compose 来解决。
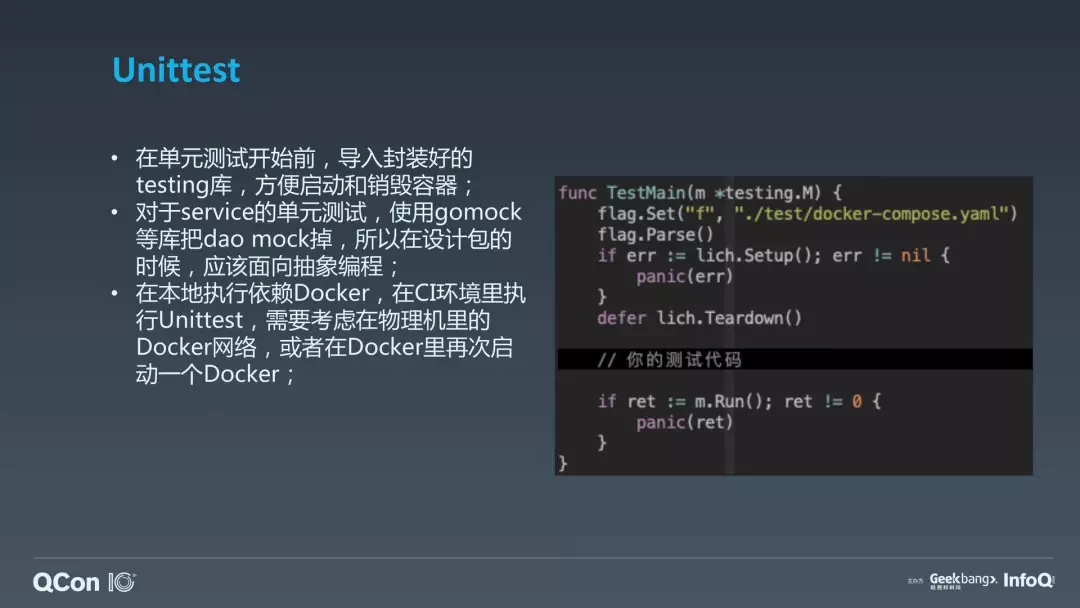
容器的拉起,容器的销毁,这些工作到底谁来做?是开发同学自己去拉起和销毁,还是说你能够把它做成一个 Library,让我们的同学写单元测试的时候比较方便?我倾向的是后者。所以在我们最终写单元测试的时候,你可以很方便地 setup 一个依赖文件,去 setup 你的容器的一些信息,或者把它销毁掉。所以说,你把环境准备好以后,最终可以跑测试代码也非常方便。当然我们也提供了一些命令函,就是 binary 的一些工具,它可以针对各个语言方便地拉起容器和销毁容器,然后再去执行代码,所以我们也提供了一些快捷的方式。
刚刚我也提到了,就是我们对于 service 也好,API 也好,因为依赖下层的 dao 或者依赖下层的 service,你都很方便 mock 掉,这个写单元测试相对简单,这个我不展开讲,你可以使用 GoMock 或者 GoMonkey 实现这个功能。
Toolchain

我们利用多个 docker-compose 来解决 dao 层的单元测试,那对于我刚刚提到的项目的一些规范,单元测试的一些模板,甚至是我写了一些 dao 的一些占位符,或者写了一些 service 代码的一些占位符,你有没有考虑过这种约束有没有人会去遵循?所以我这里要强调一点,工具一定要大于约束和文档,你写了约束,写了文档,那么你最终要通过工具把它落实。所以在我们内部会有一个类似 go tool 的脚手架,叫 Kratos Tool,把我们刚刚说的约定规范都通过这个工具一键初始化。
对于我们内部的工具集,我们大概会分为几块。第一块就是 API 的,就是你写一个 PB 文件,你可以基于这个 PB 文件生成 gRPC,HTTP 的框架代码,你也可以基于这个 PB 文件生成 swagger 的一些 JSON 文件或者是 Markdown 文件。当然了,我们还会生成一些 API,用于 debug 的 client 方便去调试,因为我们知道,gRPC 调试起来相对麻烦一些,你要去写代码。
还有一些工具是针对 project 的,一键生成整个应用的 layout,非常方便。我们还提了 model,就是方便 model 和 DTO,DTO 就是 API 里面定义的 message 的 struct 做 DeepCopy,这个也是一个工具。
对于 cache 的话,我们操作 memcache,操作 Redis 经常会要做什么逻辑?假如我们有一个 cache aside 场景,你读了一个 cache,cache miss 要回原 DB,你要把这个缓存回塞回去,甚至你可能这个回塞缓存想异步化,甚至是你要去读这个 DB 的时候要做归并回源(singleflight),我们把这些东西做成一些工具,让它整个回源到 DB 的逻辑更加简单,就是把这些场景描述出来,然后你通过工具可以一键生成这些代码,所以也是会比较方便。
我们再看最后一个,就是 test 的一些工具。我们会基于项目里面,比方说 dao 或者是 service 定义的 interface 去帮你写好 mock 的代码,我直接在里面填,只要填代码逻辑就行了,所以也会加速我们的生产。
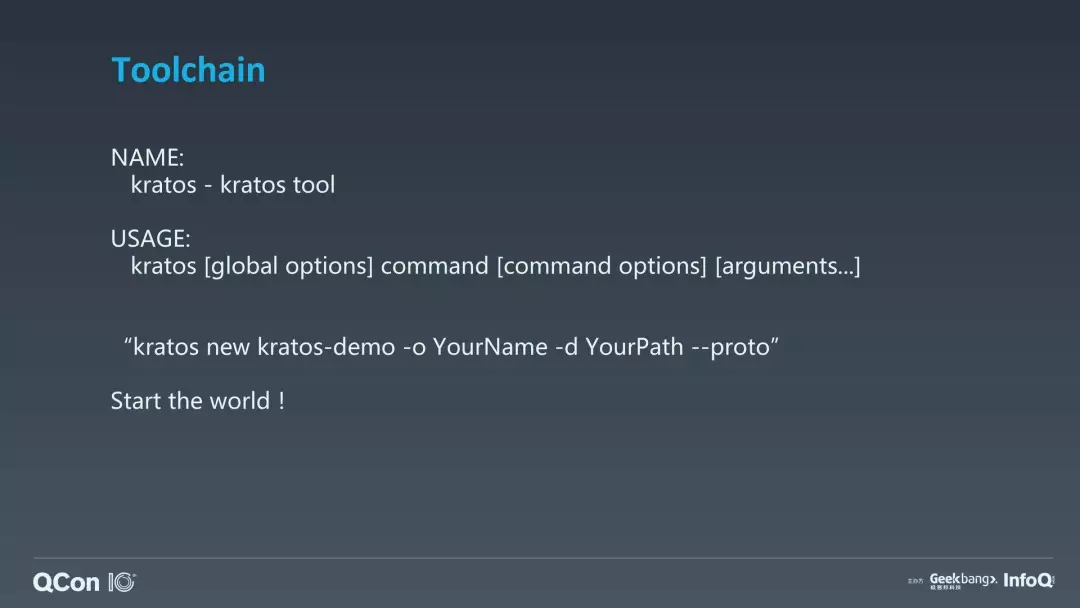
上图是 Kratos 的一个 demo,基本就是支持了一些 command。这里就是一个 kratos new kratos-demo 的一个工程,-d YourPath 把它导到某一个路径去,--proto 顺便把 API 里面的 proto 代码也生成了,所以非常简单,一行就可以很快速启动一个 HTTP 或者 gRPC 服务。
我们知道,一个微服务的框架实际非常重,有很多初始化的方式等等,非常麻烦。所以说,你通过脚手架的方式就会非常方便,工具大于约定和文档这个这个理念就是这么来的。
Configuration
讲完工具以后,最后讲一下配置文件。我为什么单独提一下配置文件?实际它也是工程化的一部分。我们一个线上的业务服务包含三大块,第一,应用程序,第二,配置文件,第三,数据集。配置文件最容易导致线上出 bug,因为你改一行配置,整个行为可能跟 App 想要的行为完全不一样。而且我们的代码的开发交付需要经过哪些流程?需要 commit 代码,需要 review,需要单元测试,需要 CD,需要交付到线上,需要灰度,它的整个流程是非常长的。在一步步的环境里面,你的 bug 需要前置解决,越前置解决,成本越低。因为你的代码的开发流程是这么一个 pipeline,所以 bug 最终流到线上的概率很低,但是配置文件没有经过这么复杂的流程,可能大家发现线上有个问题,决定要改个线上配置,就去配置中心或者配置文件改,然后 push 上线,接着就问题了,这个其实很常见。
从 SRE 的角度来说,导致线上故障的主因就是来自配置变更,所以 SRE 很大的工作是控制变更管理,如果能把变更管理做好,实际上很多问题都不会出现。配置既然在整个应用里面这么重要,那在我们整个框架或者在 Go 的工程化实践里面,我们应该对配置文件做一些什么事情?
我觉得是几个。第一,我们的目标是什么?配置文件不应该太复杂,我见过很多框架,或者是业务的一些框架,它实际功能非常强大,但是它的配置文件超级多。我就发现有个习惯,只要有一个同事写错了这个配置,当我新起一个项目的时候,一定会有人把这个错误的配置拷贝到另外一个系统里面去。然后当发现这个应用出问题的时候,我们一般都会内部说一下,你看看其他同事有没有也配错的,实际这个配错概率非常高。因为你的配置选项越多,复杂性越高,它越容易出错。所以第一个要素就是说,尽量避免复杂的配置文件。配得越多,越容易出错。
第二,实际我们的配置方式也非常多,有些用 JSON,有些用 YAML,有些用 Properties,有些用 INI。那能不能收敛成通用的一种方式呢?无论它是用 Python 的脚本也好,或者是用 JSON 也好,你只要有一种唯一的约定,不需要太多样的配置方式,对我们的运维,对我们的 SRE 同时来说,他跨项目的变更成本会变低。
第三,一定要往简单化去努力。这句话其实包含了几个方面的含义。首先,我们很多配置它到底是必须的还是可选的,如果是可选,配置文件是不是就可以把它踢掉,甚至不要出现?我曾经有一次看到我们 Java 同事的配置 retry 有一个重试默认是零,内部重试是 80 次,直接把 Redis cluster 打故障了,为什么?其实这种事故很低级,所以简单化努力的另外一层含义是指,我们在框架层面,尤其是提供 SDK 或者是提供 framework 的这些同事尽量要做一些防御编程,让这种错配漏配也处于一个可控的范围,比方重试 80 次,你觉得哪个 SDK 会这么做?所以这个是我们要考虑的。但是还有一点要强调的是,我们对于业务开发的同事,我们的配置应该足够的简单,这个简单还包含,如果你的日志基本上都是写在这个目录,你就不要提供这个配置给他,反而不容易出错。但是对于我们内部的一些 infrastructure,它可能需要非常复杂的配置来优化,根据我的场景去做优化,所以它是两种场景,一种是业务场景,足够简单,一种是我要针对我的通用的 infrastructure 去做场景的优化,需要很复杂的配置,所以它是两种场景,所以我们要想清楚你的业务到底是哪一种形态。
还有一个问题就是我们配置文件一定要做好权限的变更和跟踪,因为我们知道上线出问题的时候,我们的第一想法不是查 bug,是先止损,止损先找最近有没有变更。如果发现有变更,一般是先回滚,回滚的时候,我们通常只回滚了应用程序,而忘记回滚了配置。每个公司可能内部的配置中心,或者是配置场景,或者跟我们的二进制的交付上线都不一样,那么这里的理念就是你的应用程序和配置文件一定是同一个版本,或者是某种意义上让他们产生一个版本的映射,比方说你的应用程序 1.0,你的配置文件 2.0,它们之间存在一个强绑定关系,我们在回滚的时候应该是一起回滚的。我们曾经也因为类似的一些不兼容的配置的变更,二进制程序上线,但配置文件忘记回滚,出现过事故,所以这个是要强调的。
另外,配置的变更也要经过 review,如果没问题,应该也是按照 App 发布一样,先灰度,再放量,再全量等等类似的一种方式去推,演进式的这种发布,我们也叫滚动发布,我觉得配置文件也是一样的思路。
加入阿里云钉钉群享福利:每周技术直播,定期群内有奖活动、大咖问答 
