12月25日更新
我遇到这个问题是taskmanager gc时间过长,暂时调整了超时时间,还有其他解决办法吗?
flink on Kubernetes,目前有哪家公司在生产环境使用这种模式运行吗?运行的怎么样?
请问如果想判断某一个数据项的数据发生变化时,触发一个规则,用flink如何实现?
哪位大佬用cdh6.X集成过Flink1.9的? 求用后的建议以及使用感受。
大佬们,就动态维表join,异步Io的方式好还是广播的方式,推荐哪个?
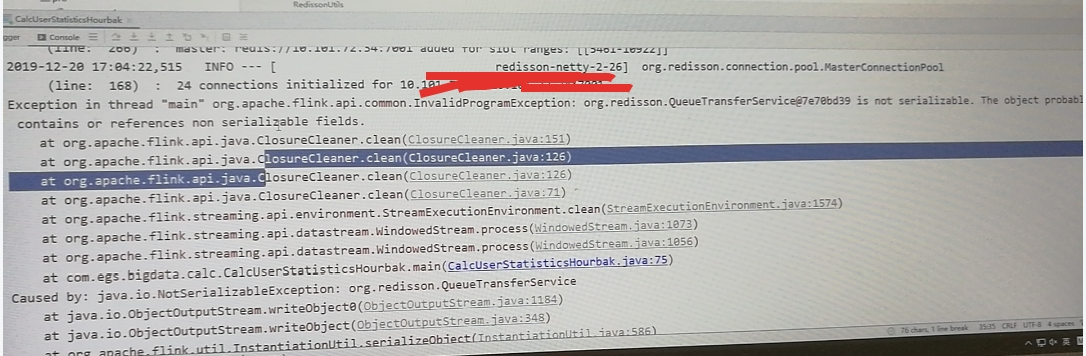
各位大佬,我在richprocesswindowfunction里面用redisson连接redis报刚刚那个错,有没有大佬碰到过
有两个subtask (来源不同的task)在同一台taskmanager 上允许,其中一个subtask反压,会影响另外一个task的subtask吗?
有人对比过flink on yarn 和 flink on Kubernetes 的优缺点吗?
如果想搭建一套分布式的训练集群,除了kafka、TensorFlow、hadoop、flink、zookeeper,还需要搭建什么吗?
各位大佬,最近使用window+watermark+processfunction,当input超过一定峰值时,就会丢数据,是processfunction处理能力这块出现的问题吗?
12月17日更新
如果公司要部署一套flink on k8s,HDFS是不是必要的?
官方demo 都是本地的,我想了解一下alink的算法是如何支持分布式数据的
大佬们,想问个cep的场景,监控用户的轨迹,用户的经纬度会上传到后台。我怎么用cep判断一定的时间间隔内,用户行驶的距离超过某个值,并且数据一直有上传,没有关闭定位啥的。
请问有好的讲解state和checkpoint的文章推荐吗?
哪位大佬知道azkaban中怎么让两个project作为依赖关系吗?
大佬们 这里为什么用的是flatmap 而不是 map 算子呢?
请问大佬,flink处理后的数据,要展现给前端展现出来的话,数据落地一般用的什么存储中间件?
为啥我把checkpoint由增量checkpoint改为普通checkpoint之后反倒不容易超时了?
实时数仓 和维度表进行关联,如何保证维度表更新的数据能够流入到任务中
我按照这个说法 查询了hive的表数据 如何sink输出呢?
基于flink开发,需要具备什么条件?比如需要团队懂什么开发语言?属于研发性的工作内容是什么?属于非研发工作的内容有什么?
怎么屏蔽flink checkpoint 打印的info 日志?
提交job时不指定并行度,应该就是使用默认并行度1,想要请问一下,并行度为1时,一个task manager对应多少个slot呢?最大并行度和最大slot取决那块的资源呢?
欢迎大家加入开发者技术群,一起线上交流
 -
-
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
如果能够分一下类就更好了
12月17日更新
请问下同时消费多个topic的情况下,在richmap里面可以获取到当前消息所属的topic吗?
你们实时读取广业务库到kafka是通过什么读的?kafka connector 的原理是定时去轮询,这样如果表多了,会不会影响业务库的性能?甚至把业务库搞挂?
有没有flink 1.9 连接 hive的例子啊?官网文档试了,没成功
实时数仓用什么存储介质来存储维表,维表有大有小,大的大概5千万左右。 各位大神有什么建议和经验分享吗?
kafkaSource.setStartFromTimestamp(timestamp); 发现kafkasource从指定时间开始消费,有些topic有效,有效topic无效,大佬们有遇到过吗?
各位大佬,flink两个table join的时候,为什么打印不出来数据,已经赋了关联条件了,但是也不报错
各位大佬 请教一下 一个faile的任务 会在这里面存储展示多久啊?
各位大佬,我的程序每五分钟一个窗口做了基础指标的统计,同时还想统计全天的Uv,这个是用State就能实现吗?
大佬们,flink的redis sink是不是只适用redis2.8.5版本?
那位大神,给一个java版的flink1.7 读取kafka数据,做实时监控和统计的功能的代码案例。
请问下风控大佬,flink为风控引擎做数据支撑的时候,怎么应对风控规则的不断变化,比如说登录场景需要实时计算近十分钟内登录次数超过20次用户,这个规则可能会变成计算近五分钟内登录次数超过20次的。
想了解一下大家线上Flink作业一般开始的时候都分配多少内存?广播没办法改CEP
谁能帮忙提供一下flink的多并行度的情况下,怎么保证数据有序 例如map并行度为2 那就可能出现数据乱序的情况啊
请教下现在从哪里可以可以看单任务的运行状况和内存占用情况,flink页面上能看单个任务的内存、cpu
大佬们 flink1.9 停止任务手动保存savepoint的命令是啥?
ide里面调试没有问题,部署到集群就会报错了,可能什么问题?
请教一下对于长时间耗内存很大的任务,大家都是开checkpoint机制,采用rocksdb做状态后端吗?
请问下大佬,flink jdbc读取mysql,tinyin字段类型自动转化为Boolean有没有好的解决方法
Flink 1.9版本的Blink查询优化器,Hive集成,Python API这几个功能好像都是预览版,请问群里有大佬生产环境中使用这些功能了吗?
各位大佬,在一个 Job 计算过程中,查询 MySQL 来补全额外数据,是一个好的实践嘛?还是说流处理过程中应该尽量避免查询额外的数据?
12月9日更新
成功做完一次checkpoint后,会覆盖上一次的checkpoint吗?
flink的异步io,是不是只是适合异步读取,并不适合异步写入呀?
请问一下,flink将结果sink到redis里面会不会对存储的IO造成很大的压力,如何批量的输出结果呢?
大佬们,flink 1.9.0版本里DataStream api,若从kafka里加载完数据以后,从这一个流中获取数据进行两条业务线的操作,是可以的吗?
flink 中的rocksdb状态怎么样能可视化的查看有大佬知道吗?
感觉flink 并不怎么适合做hive 中的计算引擎来提升hive 表的查询速度
大佬们,task端rocksdb状态 保存路径默认是在哪里的啊?我想挂载个新磁盘 把状态存到那里去
flink 的state 在窗口滑动到下一个窗口时候 上一个窗口销毁时候 state会自己清除吗?
使用jdbcsink的时候,如果连接长时间不使用 就会被关掉,有人遇到过吗?使用的是ddl的方式
想问下老哥们都是怎么统计一段时间的UV的? 是直接用window然后count嘛?
12月3日更新
请教一下,为什么我flume已经登录成功了keytab认证的kafka集群,但是就是消费不到数据呢?
flink 写入mysql 很长一段时间没有写入,报错怎么解决呢?
flink timestamp转换为date类型,有什么函数吗
flink 连接hbase 只支持1.4.3版本? onnector: type: hbase version: "1.4.3"
flink 开发里数据源配置了RDS,但是在RDS里没有看到创建的表,是为什么呢?
Tumbling Window里的数据,是等窗口期内的数据到齐之后一次性处理,还是到了一条就处理一条啊
双流join后再做time window grouping. 但是双流join会丢失时间属性,请问大家如何解决
stream processing with apache flink,这本书的中译版 现在可以买吗?
flink on yarn时,jm和tm占用的内存最小是600M,这个可以修改吗?
各位大佬,使用默认的窗口Trigger,在什么情况下会触发两次啊?窗口关闭后,然后还来了这个窗口期内的数据,并且开了allowedLateness么?
flink web里可以像storm那样 看每条数据在该算子中的平均耗时吗?
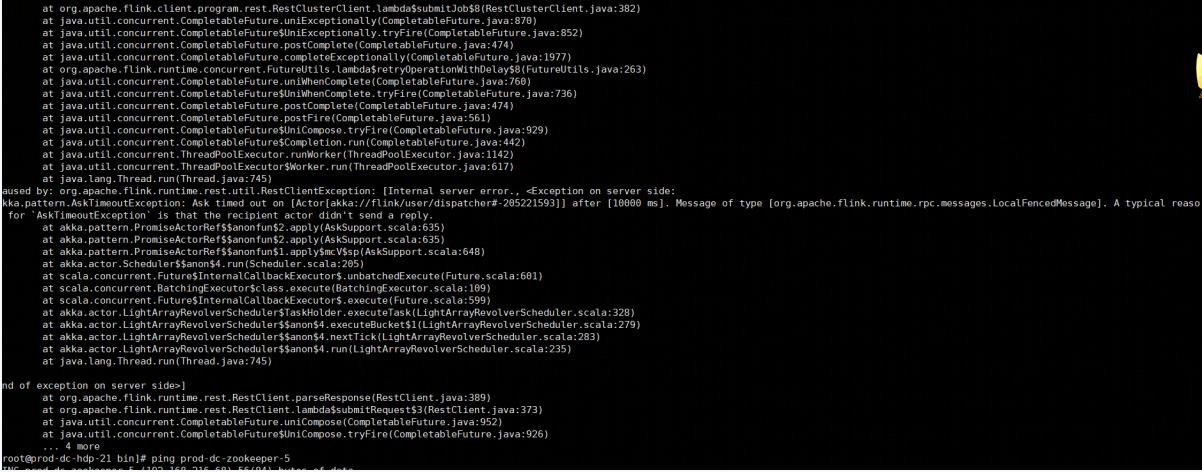
各位大佬,flink任务的并发数调大到160+以后,每隔几十分钟就会出现一次TM节点连接丢失的异常,导致任务重启。并发在100时运行比较稳定,哪位大佬可以提供下排查的思路?
感觉stateful function 是下一个要发力的点,这个现在有应用案例吗?
flink消费kafka,可以从指定时间消费的吗?目前提供的接口只是根据offset消费?有人知道怎么处理?
flink 的Keyby是不是只是repartition而已?没有将key相同的数据放到一个组合里面
开源1.9的sql中怎么把watermark给用起来,有大神知道吗?
采用了checkpoint,程序停止了之后,什么都不改,直接重启,还是能接着继续运行吗?如果可以的话,savepoint的意义又是什么呢?
有人做过flink 的tpc-ds测试吗,能不能分享一下操作的流程方法
checkpoint是有时间间隔的,也就可以理解为checkpoint是以批量操作的,那如果还没进行ckecnpoint就挂了,下次从最新的一次checkpoint重启,不是重复消费了?
kafka是可以批量读取数据,但是flink是一条一条处理的,应该也可以一条一条提交吧。
各位大佬,flink sql目前是不是不支持tumbling window join,有人了解吗?
你们的HDFS是装在taskmanager上还是完全分开的,请问大佬们有遇到这种情况吗?
大佬们flink检查点存hdfs的话怎么自动清理文件啊 一个128M很快磁盘就满了
请教一下各位,这段代码里面,我想加一个trigger,实现每次有数据进window时候,就输出,而不是等到window结束再输出,应该怎么加?

大家怎么能动态的改变 flink WindowFunction 窗口数据时间
flink on yarn之后。yarn的日志目录被写满,大家如配置的?
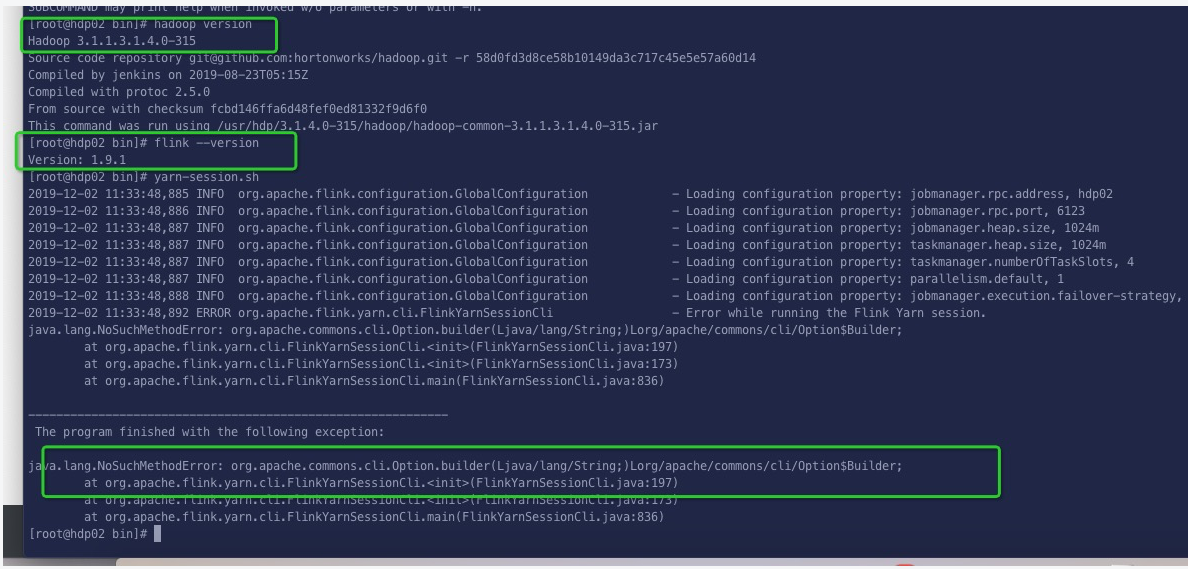
Flink1.9 启动 yarn-session报这个错误 怎么破?
yarn 模式下,checkpoint 是存在 JobManager的,提交任务也是提交给 JobManager 的吧?
heckpoint机制,会不会把window里面的数据全部放checkpoint里面?
Flink On Yarn的模式下,如果通过REST API 停止Job,并触发savepiont呢
jenkins自动化部署flink的job,一般用什么方案?shell脚本还是api的方式?
各位大佬,开启增量checkpoint 情况下,这个state size 是总的checkpoint 大小,还是增量上传的大小?
想用状态表作为子表 外面嵌套窗口 如何实现呢 因为状态表group by之后 ctime会失去时间属性,有哪位大佬知道的?
richmapfuntion的open/close方法,和处理数据的map方法,是在同一个线程,还是不同线程调用的?
flink on yarn 提交 参数 -p 20 -yn 5 -ys 3 ,我不是只启动了5个container么?
我对数据流先进行了keyBy,print的时候是有数据的,一旦进行了timeWindow滑动窗口就没有数据了,请问是什么情况呢?
用java api写的kafka consumer能消费到的消息,但是Flink消费不到,这是为啥?
我state大小如果为2G左右 每次checkpoint会不会有压力?
link-table中的udaf能用deltaTrigger么?
flink1.7.2,场景是一分钟为窗口计算每分钟传感器的最高温度,同时计算当前分钟与上一分钟最高温
如果要对客户端提交作业到flink进行访问控制,你们有类似的这种使用场景吗?
Flink能够做实时ETL(oracle端到oracle端或者多端)么?
怎么保证整个链路的exactly one episode精准一次,从source 到flink到sink?
在SQL的TUMBLE窗口的统计中,如果没数据进来的,如何让他也定期执行,比如进行count计算,让他输出0?
flink里面broadcast state想定时reload怎么做?我用kafka里的stream
有人用增量cleanupIncrementally的方式来清理状态的嘛,感觉性能很差。
flink sink to hbase继承 RichOutputFormat运行就报错
flink写es,因为半夜es集群做路由,导致写入容易失败,会引起source的反压,然后导致checkpoint超时任务卡死,请问有没有办法在下游es处理慢的时候暂停上游的导入来缓解反压?
各位大佬,以天为单位的窗口有没有遇到过在八点钟的时候会生成一条昨天的记录?
想问一下,我要做一个规则引擎,需要动态改变规则,如何在flink里面执行?
flink-1.9.1/bin/yarn-session.sh: line 32: construc
我要用sql做一个规则引擎,需要动态改变规则,如何在flink里面执行?
我要用sql做一个规则引擎,需要动态改变规则,如何在flink里面执行?
一般公司的flink job有没有进程进行守护?有专门的工具或者是自己写脚本?这种情况针对flink
kafka能不能通过java获取topic的消息所占空间大小?
Flink container was removed这个咋解决的。我有时候没有数据的时候也出现这
大家有没有这种场景,数据从binlog消费,这个信息是订单信息,同一个订单id,会有不同状态的变更
问大家个Hive问题,新建的hive外部分区表, 怎么把HDFS数据一次性全部导入hive里 ?
flink里面的broadcast state值,会出现broad流的数据还没put进mapstat
Flink SQL DDL 创建表时,如何定义字段的类型为proctime?
请问下窗口计算能对历史数据进行处理吗?比如kafka里的写数据没停,窗口计算的应用停掉一段时间再开起
请问下,想统计未退费的订单数量,如果一个订单退费了(发过来一个update流),flink能做到对结果进行-1吗,这样的需求sql支持吗?
使用Flink sql时,对table使用了group by操作。然后将结果转换为流时是不是只能使用的toRetractStream方法不能使用toAppendStream方法。
你们的去重容许有误差?因为bloom filter其实只能给出【肯定不存在】和【可能存在】两种结果。对于可能存在这种结果,你们会认为是同一条记录?
如何基于flink 实现两个很大的数据集的交集 并集 差集?
各位好,请教一下,滑动窗口,每次滑动都全量输出结果,外部存储系统压力大,是否有办法,只输出变化的key?
RichSinkFunction close只有任务结束时候才会去调用,但是数据库连接一直拿着,最后成了数据库连接超时了,大佬们有什么好的建议去处理吗??
请问一下各位老师,flink flapmap 中的collector.collect经常出现Buffer pool is destroyed可能是什么原因呢?
用asyncIO比直接在map里实现读hbase还慢,在和hbase交互这块儿,每个算子都加了时间统计
请教一下,在yarn上运行,会找不到 org.apache.flink.streaming.util
请问下大佬,flink1.7.2对于sql的支持是不是不怎么好啊 ,跑的数据一大就会报错。
flink 有那种把多条消息聚合成一条的操作吗,比如说每五十条聚合成一条
请问 阿里云实时计算(Blink)支持这4个源数据表吗?DataHub Kafka MQ MaxCompute?
为啥checkpoint时间会越来越长,请问哪位大佬知道是因为啥呢?
请问Flink的最大并行度跟kafka partition数量有关系吗? source的并行度应该最好是跟partition数量一致吧,那剩下的算子并行度呢?
请教一下,有没有flink ui的文章呢?在这块内存配置,我给 TM 配置的内存只有 4096 M,但是这里为什么对不上呢?请问哪里可以看 TM 内存使用了多少呢?
请教个问题,fink RichSinkFunction的invoke方法是什么时候被调用的?
interval不支持left join那怎么可以实现把窗口内左表的数据也写到下游呢?
各位 1、sink如何只得到最终的结果而不是也输出过程结果 ;2、不同的运算如何不借助外部系统的存储作为另外一个运算的source
请教各位一个问题,flink中设置什么配置可以取消Generic这个泛型,如图报错:
有大佬在吗,线上遇到个问题,但是明明内存还有200多G,然后呢任务cancel不了,台也取消不了程序
大佬们、有没有人遇到过使用一分钟的TumblingEventTimeWindows,但是没有按时触发窗口、而是一直等到下一条消息进来之后才会把这个窗口的数据发送出去的?
大佬们、有没有人遇到过使用一分钟的TumblingEventTimeWindows,但是没有按时触发窗口、而是一直等到下一条消息进来之后才会把这个窗口的数据发送出去的?
flink timestamp转换为date类型,有什么函数吗
flink 写入mysql 很长一段时间没有写入,报错怎么解决呢?
有没有大佬知道实时报表怎么做?就是统计的结果要实时更新,热数据。