为了方便大数据开发者快速找到相关技术问题和答案,开发者社区策划了大数据计算技术1000问内容,包含Flink、Spark等流式计算(实时计算)、离线计算、Hbase等实践中遇到的技术问题和面试问题等维度内容。
我们会以每天至少50条的速度,增加优秀的大数据问答内容。
为了方便开发者线上交流,社区组建了大数据钉钉群,有数千人在里边讨论技术问题,点击这里加入群组织吧。https://developer.aliyun.com/article/713951
友情提示:1000问的内容含量比较大,收藏该页面不迷失哦
hive表关联查询,如何解决数据倾斜的问题?
hive内部表和外部表的区别
Spark 相关试题 Spark Core面试篇01
随着Spark技术在企业中应用越来越广泛,Spark成为大数据开发必须掌握的技能。希望能给大家带来帮助。
Spark master使用zookeeper进行HA的,有哪些元数据保存在Zookeeper?
Spark master HA 主从切换过程不会影响集群已有的作业运行,为什么?
Spark on Mesos中,什么是的粗粒度分配,什么是细粒度分配,各自的优点和缺点是什么?
Apache Spark有哪些常见的稳定版本,Spark1.6.0的数字分别代表什么意思?
Spark技术栈有哪些组件,每个组件都有什么功能,适合什么应用场景?
简单说一下hadoop和spark的shuffle相同和差异?
Mapreduce和Spark的都是并行计算,那么他们有什么相同和区别
二、选择题
spark 的 master 和 worker 通过什么方式进行通信的:
spark.deploy.recoveryMode 不支持那种:
Task 运行在下来哪里个选项中 Executor 上的工作单元:
hive 的元数据存储在 derby 和 MySQL 中有什么区别:
Master 的 ElectedLeader 事件后做了哪些操作
【Spark面试2000题41-70】Spark core面试篇02
Spark有哪些聚合类的算子,我们应该尽量避免什么类型的算子?
Spaek程序执行,有时候默认为什么会产生很多task,怎么修改默认task执行个数?
为什么Spark Application在没有获得足够的资源,job就开始执行了,可能会导致什么问题发生?
Spark为什么要持久化,一般什么场景下要进行persist操作? 为什么要进行持久化?
介绍一下cogroup rdd实现原理,你在什么场景下用过这个rdd?
一、面试30题(第71-100题)
hbase预分区个数和spark过程中的reduce个数相同么
如何理解Standalone模式下,Spark资源分配是粗粒度的?
什么是二次排序,你是如何用spark实现二次排序的?互联网公司常面
窄依赖父RDD的partition和子RDD的parition是不是都是一对一的关系?
Hadoop中,Mapreduce操作的mapper和reducer阶段相当于spark中的哪几个算子?
不需要排序的hash shuffle是否一定比需要排序的sort shuffle速度快?
conslidate是如何优化Hash shuffle时在map端产生的小文件?
spark.default.parallelism这个参数有什么意义,实际生产中如何设置?
spark.storage.memoryFraction参数的含义,实际生产中如何调优?
spark.shuffle.memoryFraction参数的含义,以及优化经验?
介绍一下你对Unified Memory Management内存管理模型的理解?
Yarn中的container是由谁负责销毁的,在Hadoop Mapreduce中container可以复用么?
提交任务时,如何指定Spark Application的运行模式?
不启动Spark集群Master和work服务,可不可以运行Spark程序?
spark on yarn Cluster 模式下,ApplicationMaster和driver是在同一个进程么?
运行在yarn中Application有几种类型的container?
你们提交的job任务大概有多少个?这些job执行完大概用多少时间?
YarnClient模式下,执行Spark SQL报这个错:
spark.driver.extraJavaOptions这个参数是什么意思,你们生产环境配了多少?
导致Executor产生FULL gc 的原因,可能导致什么问题?
Hbase 相关问题
Storm 相关问题
大数据相关问题
面试系列重新继续发布,题目都是好题目,答案作为参考是可以的,作为学习素材,仅供大家参考。
hadoop的TextInputFormat作用是什么,如何自定义实现
hadoop和spark的都是并行计算,那么他们有什么相同和区别
hadoop的TextInputFormat作用是什么,如何自定义实现?
hadoop和spark的都是并行计算,那么他们有什么相同和区别?
不配置spark.deploy.recoveryMode选项为ZOOKEEPER,会有什么不好的地方
java.lang.OutOfMemory, unable to create new native
spark-shell提交Spark Application如何解决依赖库
ERROR XSDB6: Another instance 。。。
java.lang.IllegalArgumentException: java.net.UnknownHostException: dfscluster
Spark Streaming 和kafka整合后读取消息报错: OffsetOutOfRangeException
在 echo $JAVA_HOME /home/pipi/ENV/jdk
【大咖问答】对话《深入浅出 Node.js》作者,阿里云SDK团队负责人 朴灵
大数据平台与Hadoop、HDFS、Mapreduce、YARN之间有何关系呢?
在使用大数据开发套件中odps_sql,怎么实现一个任务,比如从原始表抽取12月份的数据,插入到新的表分区12月
Java对于大数据处理有没有好的方法?一直都只接触python处理海量数据,但是应该处理数据不可能仅仅局限于一种语言,或者说Java在这方面是不是存在某种缺陷。
flink 对比 spark 的优势很明显嘛?优势在哪些方面呢?
大数据平台与Hadoop、HDFS、Mapreduce、YARN之间有何关系呢?
用python写flink程序,从哪里import各种operation?
在flink集群模式下,能不能指定某个节点的solt来执行一个task?
当Spark在S3上读取大数据集时,在“停机时间”期间发生了什么?
用python写flink程序,从哪里import各种operation?
在flink集群模式下,能不能指定某个节点的solt来执行一个task?
当Spark在S3上读取大数据集时,在“停机时间”期间发生了什么?
flink用IDEA本地运行可以读取HDFS数据,然后把项目打包提交到flink集群,无法读取HDFS数据,出现以下错误,这是为何?
Spark,Scala:如何从Rdd或dataframe中删除空行?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
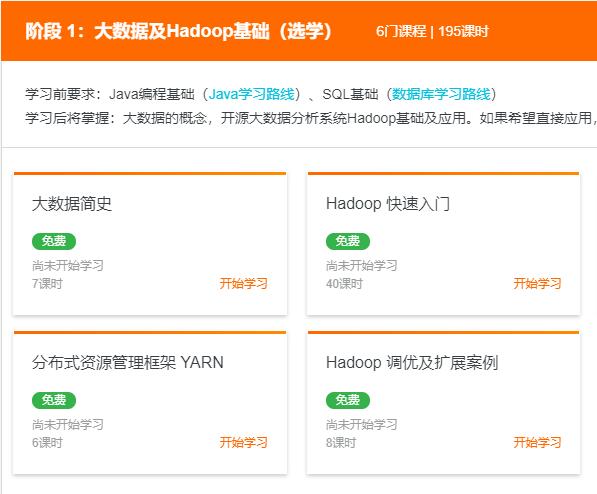
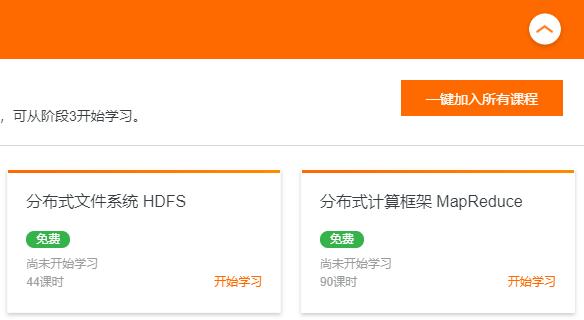
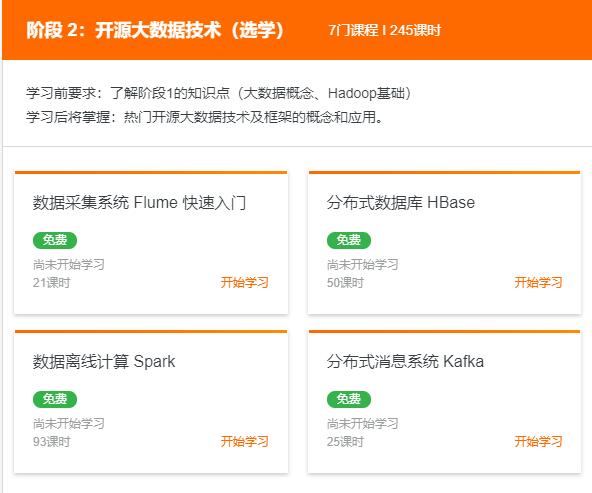
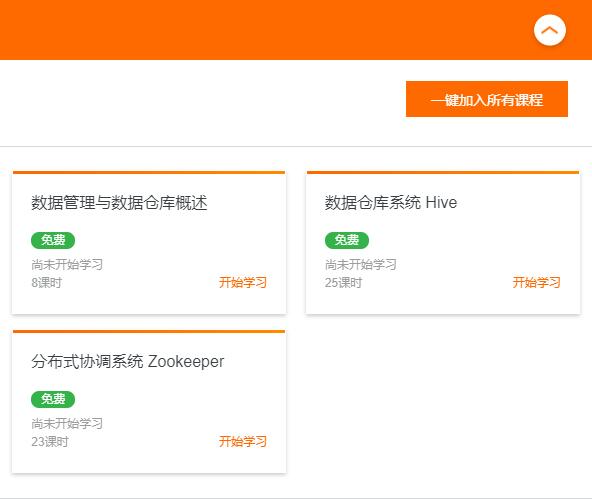
非常感觉收集汇总,阿里云关于大数据的课程也很多非常优秀的课程可以免费申请学习,点击下面相应课程即可免费学习: