
在阿里云容器服务上运行基于 TensorFlow 的 Alexnet
AlexNet 是 2012 年由 Alex Krizhevsky 使用五层卷积、三层完全连接层开发的 CNN 网络,并赢得了 ImageNet 竞赛(ILSVRC)。AlexNet 证明了 CNN 在分类问题上的有效性(15.3% 错误率),而此前的图片识别错误率高达 25%。这一网络的出现对于计算机视觉在深度学习上的应用具有里程碑意义。
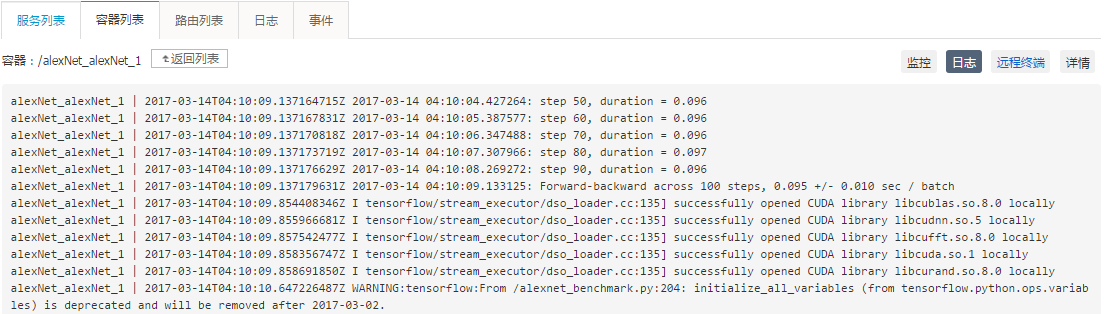
AlexNet 也是深度学习框架常用的性能指标工具,TensorFlow 就提供的
alexnet_benchmark.py 可以测试 GPU 和 CPU 上的性能。本文档以 AlexNet 为例,向您展示如何在阿里云容器服务上简单快速地运行 GPU 应用。
前提条件
需要基于北京 HPC 或者 GN4 规格族 GPU 云服务器的容器服务。


版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
您已经详细描述了在阿里云容器服务上部署基于 TensorFlow 的 AlexNet 模型的步骤,这里我再简要概括一下关键流程和补充一些可能需要的信息:
前提条件确认:
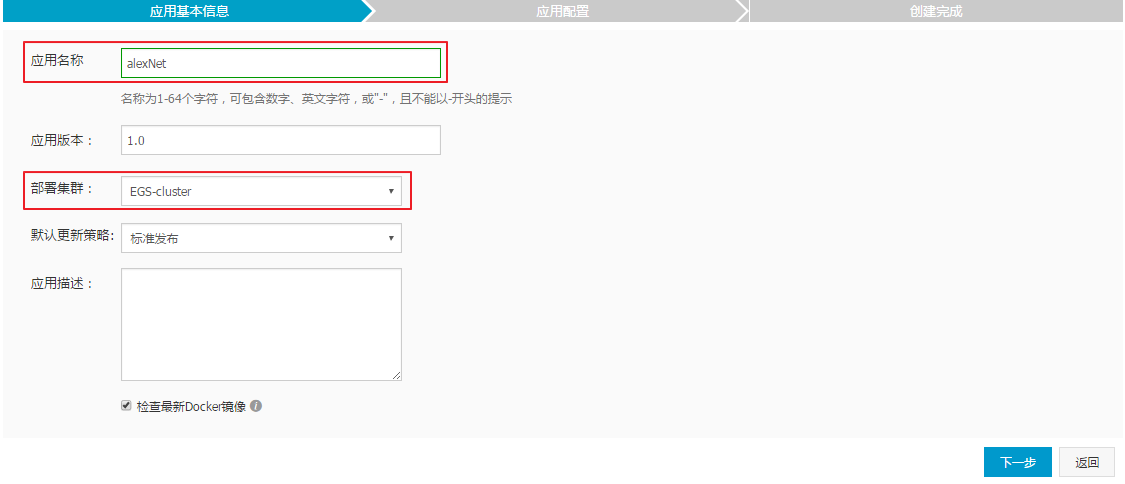
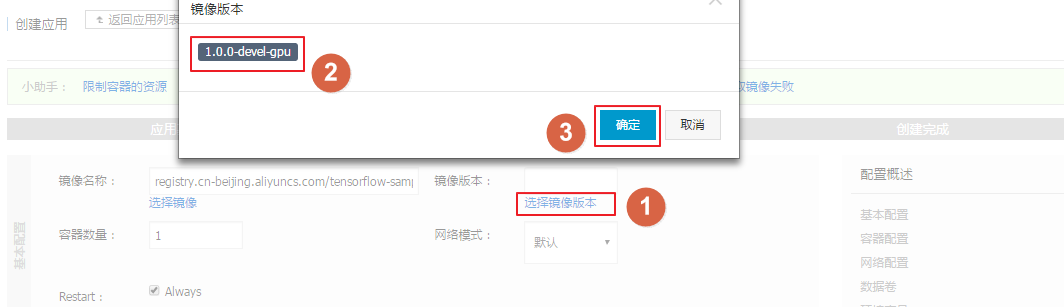
镜像选择与应用创建:
registry.cn-beijing.aliyuncs.com/tensorflow-samples/alexnet_benchmark:1.0.0-devel-gpu。alexNet),选择正确的GPU集群,并配置镜像版本为1.0.0-devel-gpu。配置容器运行参数:
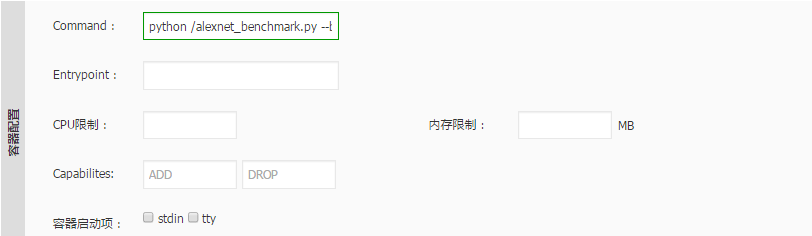
python /alexnet_benchmark.py --batch_size 128 --num_batches 100,这将执行AlexNet的性能测试脚本。aliyun.gpu,值为所需的GPU数量,例如1。应用部署与监控:
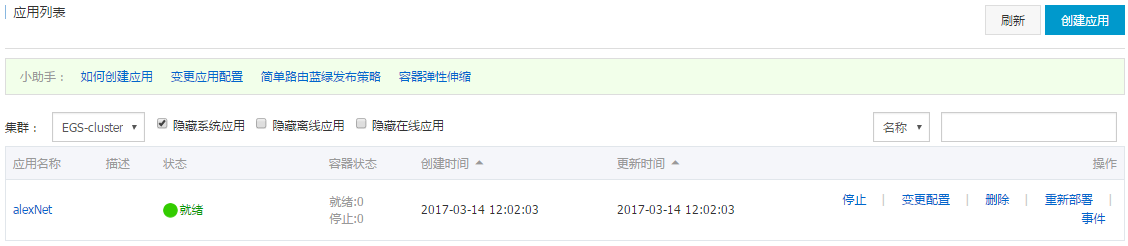
alexNet应用的状态。注意事项:
--batch_size和--num_batches参数。通过上述步骤,您可以高效地在阿里云容器服务上部署和评估AlexNet模型的性能,这对于深度学习项目开发和优化来说是一个非常实用的流程。
