
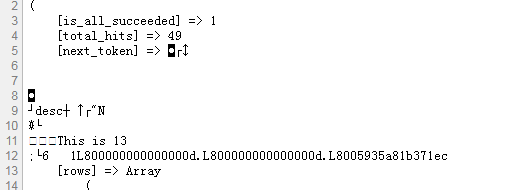
你们有没有碰到过 next_token 乱码?
本问题来自阿里云开发者社区的【11大垂直技术领域开发者社群】。https://developer.aliyun.com/article/706511 点击链接欢迎加入感兴趣的技术领域群。
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
next_token乱码的问题可能出现在使用阿里云API网关或者某些需要分页查询的接口时。这个token是用来标识请求序列和分页信息的。如果遇到next_token出现乱码的情况,通常不是因为next_token本身乱码,而是传输、存储或处理过程中字符编码不一致导致的显示问题。
解决此类问题可以尝试以下几个步骤:
检查编码设置:确保在接收和处理next_token的整个过程中,所有系统(包括但不限于客户端、服务器、数据库等)的字符编码设置一致,推荐使用UTF-8编码。
传输层编码处理:如果通过HTTP请求传递next_token,确保Content-Type头部正确设置了字符编码(如application/json; charset=utf-8),并且在发送和接收数据时正确处理了编码。
编码转换:如果确实接收到的是乱码,尝试在代码中将接收到的字符串转换为正确的编码格式。在Python中,可以使用str.encode('utf-8')或str.decode('utf-8')进行编码或解码操作。
复现与日志检查:尝试复现问题场景,并仔细检查涉及next_token处理的所有环节的日志,看是否在某个环节出现了编码错误的提示。
API文档确认:再次查阅相关的阿里云产品API文档,确认next_token的正确使用方式以及是否有特定的编码要求。
如果以上方法都不能解决问题,建议直接在阿里云开发者社区对应的产品板块提问,提供更详细的错误信息和你的使用场景,以便获得更专业的技术支持。
