
各位大佬,能否帮忙看一下这个是不是出现了严重的过拟合现象?
本人用的是LSTM的方法,试了一些方法都没法改善,求大佬的帮忙
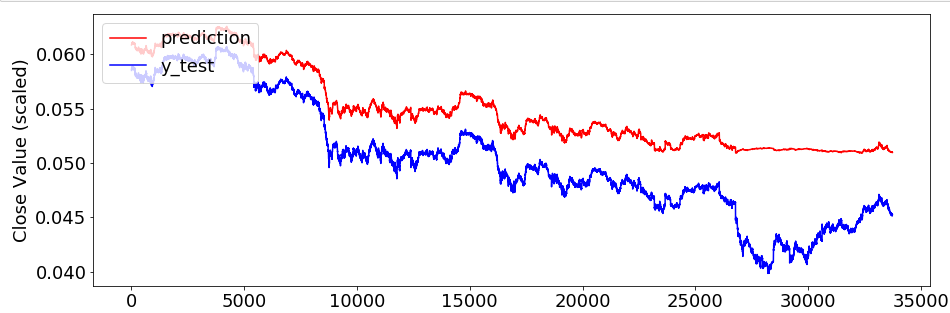
本问题来自阿里云开发者社区的【11大垂直技术领域开发者社群】。https://developer.aliyun.com/article/713951 点击链接欢迎加入感兴趣的技术领域群。
展开
收起
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
阿里云 AI 助理回答
针对您使用LSTM(长短期记忆网络)遇到的性能提升难题,这里有一些建议,希望能帮助到您。LSTM在处理序列数据时非常有效,但优化模型以获得更好的性能往往需要综合考虑多个方面。以下是一些可能的改进方向:
-
数据预处理:
- 标准化/归一化:确保输入数据被适当地标准化或归一化,这有助于加速训练过程并提高模型稳定性。
- 填充和截断:对于变长序列,合理地填充或截断序列至固定长度,可以简化模型处理流程。
- 特征工程:尝试添加有意义的特征或者进行特征选择,去除噪声。
-
模型架构调整:
- 增加层数:尝试增加LSTM层的数量,更深的网络可能捕捉更复杂的模式,但也要注意过拟合的风险。
- 双向LSTM:如果序列中的前后信息都很重要,使用双向LSTM可以同时利用过去和未来的上下文信息。
- 注意力机制:引入注意力机制可以让模型学习到在不同时间步上分配不同权重的能力,从而更好地聚焦于关键信息。
- GRU或Transformer:如果LSTM效果不佳,可以尝试其他序列模型如GRU(门控循环单元)或Transformer,它们在某些任务上可能表现更好。
-
正则化与防止过拟合:
- Dropout:在LSTM层中加入Dropout层,随机丢弃一部分神经元,减少模型复杂度,防止过拟合。
- 早停法:监控验证集上的损失或准确率,当指标不再改善时提前终止训练。
- 正则化项:如L1、L2正则化,可以在损失函数中加入,约束模型参数大小。
-
优化器与学习率策略:
- 更换优化器:Adam、RMSprop等自适应学习率的优化器通常比SGD表现好,但也可以尝试其他新型优化器如Nadam、AdamW。
- 学习率调度:使用学习率衰减策略,如指数衰减、余弦退火或使用学习率预热,可以帮助模型跳出局部最优。
-
超参数调优:
- 网格搜索或随机搜索:系统地调整超参数组合,寻找最佳配置。
- 贝叶斯优化:更高效的超参数调优方法,通过构建概率模型来指导搜索过程。
-
模型集成:
- 投票或平均:训练多个LSTM模型,然后对它们的预测结果进行投票或平均,可以提高泛化能力。
- 堆叠集成:将多个模型作为特征输入给另一个模型,进一步提升性能。
-
硬件与环境:
- 确保您的计算资源足够,尤其是GPU内存,以及使用最新的深度学习框架版本,这些都能影响训练效率和最终性能。
最后,建议详细记录每次实验的设置和结果,以便追踪哪些改动有效,哪些无效,这是优化过程中非常重要的一步。希望这些建议能对您有所帮助!如果您在阿里云上运行模型,还可以考虑使用阿里云的机器学习平台PAI或ElasticDL等服务,它们提供了丰富的工具和优化策略来支持深度学习模型的训练和部署。
有帮助
无帮助
AI 助理回答生成答案可能存在不准确,仅供参考
相关问答