
各位 我遇到一个问题 sparksession在操作算子中使用 本地可以正常跑通 但是部署到集群上会报错 。哪位大佬给指点一下 方向

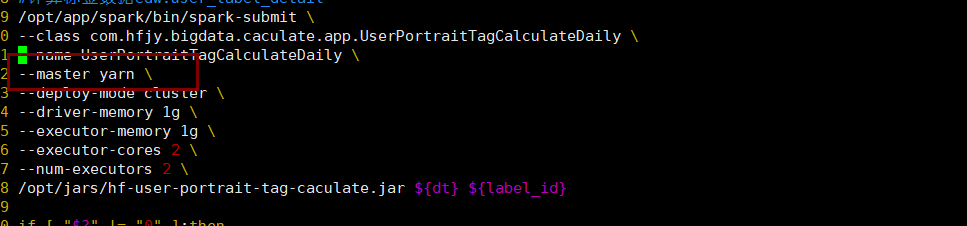
这种方式 在本地ok 在集群不可以,指定了--master yarn
我这是在操作算子中使用sparksession 报这个错 玄奎
代码里没有setmaster
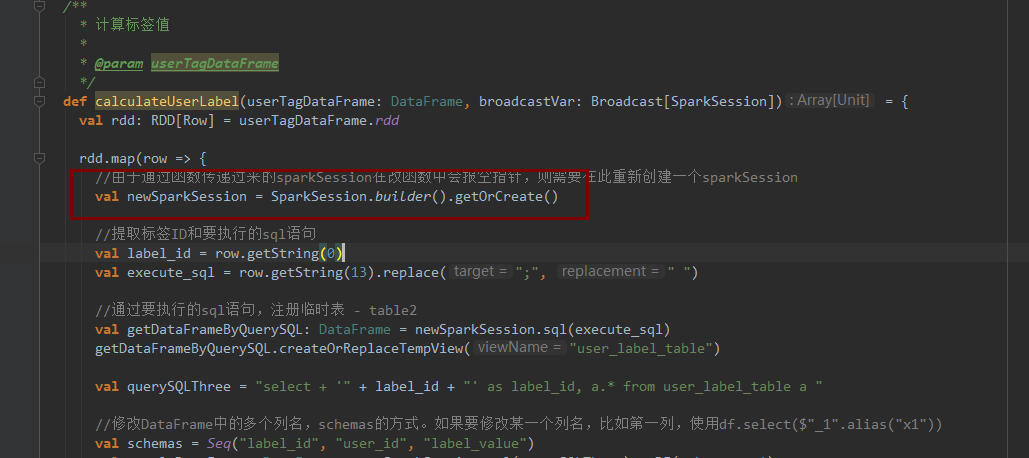
我这是main()方法里面声明的 但是我还需要在操作算子里面再声明一个 为了在算子里面使用sparksession
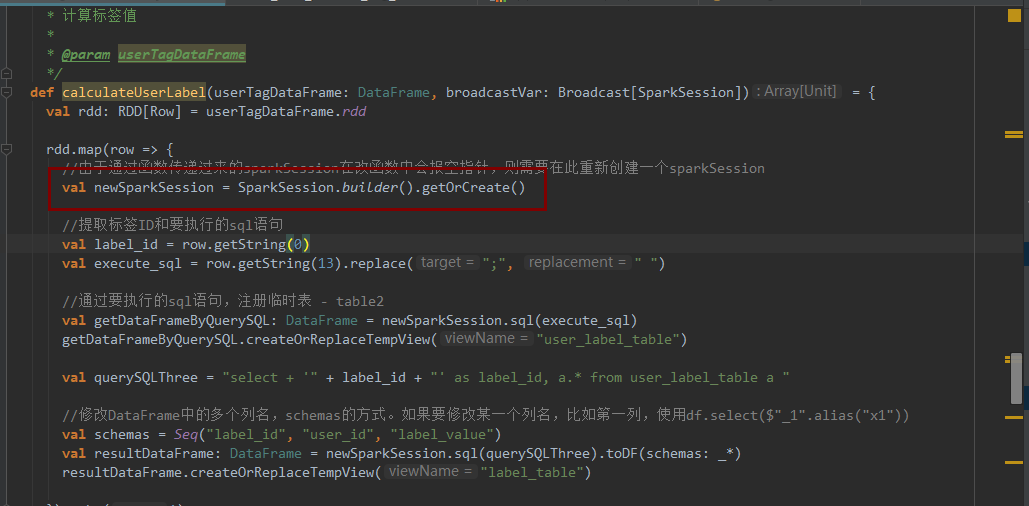
放外面 操作算子使用 会报空指针异常 sparksession会报空指针
把sparksession广播出去 也不行
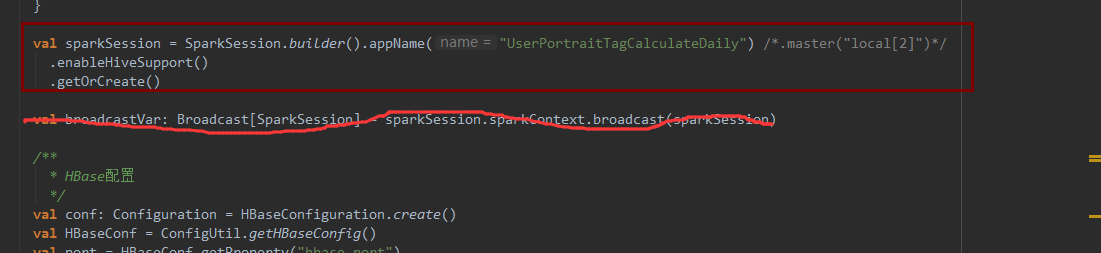
刚刚使用广播的方式 结果 在本地还是可以 集群就不行
本地跑 设置master了, 打包到集群 出现有问题
userTagDataFrame.sparkSession就能拿到session了,不用再创建,再创建是新的,必须指定master
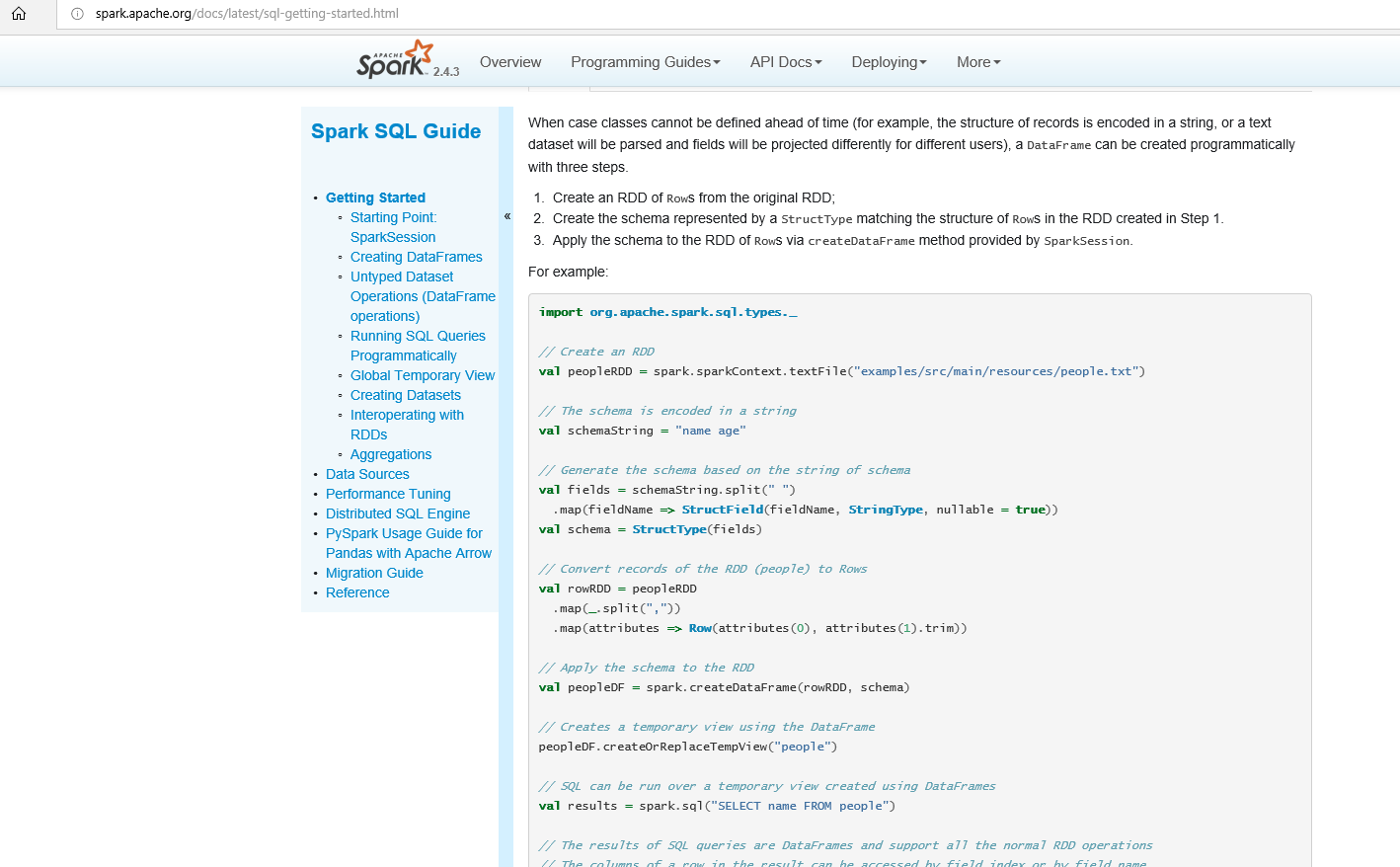
创建一个schame,rdd+schame就是df
本问题来自阿里云开发者社区的【11大垂直技术领域开发者社群】。https://developer.aliyun.com/article/706511 点击链接欢迎加入感兴趣的技术领域群。
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
在Spark应用中,尤其是在使用SparkSession操作算子时遇到问题,尤其是本地运行正常但部署到YARN集群上出现问题,通常涉及几个常见的原因。以下是一些可能的解决方案和排查方向:
资源配置问题:确保你的YARN集群有足够的资源(内存、CPU核数)来运行你的任务。资源不足会导致任务被拒绝或执行失败。
依赖冲突或缺失:检查你的项目依赖是否正确打包并上传到了集群的所有节点上。有时候,本地环境与集群环境的依赖不一致会导致问题。
SparkSession实例共享:如提示所述,你不需要在每个操作算子内部重新创建SparkSession。你应该在程序的入口点(通常是main方法)创建一个全局的SparkSession实例,并在需要的地方通过该实例进行操作。这样可以避免因多次初始化导致的配置混乱或资源占用问题。
广播变量问题:如果尝试使用广播变量传递SparkSession,这实际上是不必要的,因为SparkSession应该是每个Executor上下文的一部分,而不是通过广播变量传递。广播变量主要用于大数据量的只读数据共享,而非像SparkSession这样的运行时环境对象。
配置一致性:确认你在本地运行时使用的配置(比如Hadoop配置、Spark配置)与提交到YARN集群时使用的配置相匹配。可以通过设置spark-submit命令行参数或者在代码中通过SparkConf设置来确保这一点。
日志和错误信息:仔细查看集群上的日志输出,特别是YARN的应用日志和Spark executor的日志,这些日志通常会提供更详细的错误信息,帮助定位问题所在。
权限问题:如果你的代码涉及到文件系统操作(例如读写HDFS),确保应用具有相应的权限,特别是在分布式环境下。
版本兼容性:确认你的Spark版本与Hadoop、YARN以及其他相关组件的版本之间是兼容的。版本不兼容可能导致一些隐晦的问题。
针对你提到的空指针异常,确保在任何使用SparkSession之前它已经被正确初始化且非空。如果在操作算子内部确实需要访问SparkSession,考虑将它作为参数传递给那些函数,而不是在函数内部再次创建。
最后,根据错误的具体信息进行针对性的解决是非常关键的,因此建议详细查看集群上的错误日志,并根据上述方向逐一排查。
