一.引言
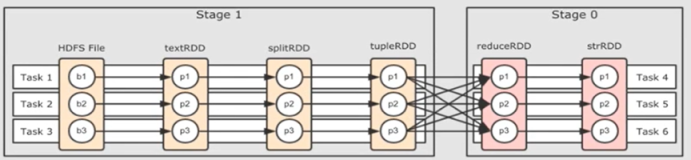
使用 spark 读取 parquet 文件,共有 M 个 parquet 文件,于是启动了 P Executor x Q Cores 进行如下 WordCount 代码测试,其中 P x Q = M 即 Core 数目与 parquet 文件数一一对应:

 编辑
编辑
其中每个 row 的 47 列对应的 parquet 文件名样例如下:
/usr/hadoop/part-01005-abcd14fd-f70f-40c5-a30e-fb3ea22c192e-c000.snappy.parquet

程序为了统计每个 parquet 内文件数量是否一致。由于 P[Executor] x Q[Core] = M [Parquet Num],所以认为每一个 Task 处理一个 Parquet,所以应该每一个日志都打印 Path + wordCount 结果即一一对应,但是实际操作发现 Path + wordCount 存在一对多的情况,遂开始排查。
二.Println 线程安全问题
由于默认 P x Q = M 的情况下 Task 会与 Parquet 执行一一对应,所以应该每个 partition 都执行 foreachPartition 的 task(1) 操作去打印路径,所以实际打印路径数与读取 parquet 数量不一致时,首先想到的是线程安全的问题,而不是 partition 合并。所以把 println 换成了线程安全的 Spark Logging:
object TestReadParquetV2 extends Logging { ... println(s"[$parquetId] Path: $path") ↓ logInfo(s"[$parquetId] Path: $path") ... }

切换后重新运行程序发现日志还是存在一对多的情况,且与 println 日志一致:

 编辑
编辑
其中 TestReadParquet 是 LogInfo 打印的路径,FileScanRDD 是 Executor 扫描文件打印的日志,这里 scan 扫描的打印日志数量多于 LogInfo 打印的日志,所以排除是打印的线程安全问题导致的,出现一对多的情况就是因为 Spark 内部对多个 Partition 进行了合并,从而导致两边不一致。后续又重新查看了源码发现错怪了 println,其内部也是线程安全的:

 编辑
编辑
结论:println 线程安全,误会一场。
三.spark.sql.files.openCostInBytes

 编辑
编辑
既然是因为 partition 合并导致了 Task 和 Parquet 的日志没有一一对应,接下来就得找一下 Spark.sql.files 的相关参数了,看看调整后能否一一对应,首先找到了 spark.sql.files.openCostInBytes,浅翻译一下:
打开文件的估计成本(以字节数衡量)可以同时扫描。这在将多个文件放入分区时使用。最好是高估,这样小文件的分区会比大文件的分区(先安排)更快。此配置仅在使用基于文件的源(如Parquet、JSON和ORC)时有效。官方的解释看的有点蒙,大致意思是用于合并小文件,该参数默认 4M,表示小于 4M 的小文件会合并到一个分区中。样例中每个 parquet 文件为 8M,我把这个参数改为 1M 看下是否会取消合并:
--conf spark.sql.files.openCostInBytes=1048576 \

修改 spark-submit 脚本,增加 conf 配置,也可以在代码中 SparkConf 配置:

 编辑
编辑
结论: 执行后依然是一对多的情况,没有达到 Task 与 Parquet 的一对一处理要求。
四.spark.sql.files.maxPartitionBytes (👍)

 编辑
编辑
openCostInBytes 参数可以看作是 partition 的最小 bytes 要求,刚才试了一下不生效,现在试一下 partition 的最大 bytes 要求,maxPartitionBytes 参数规定了读取文件时要打包到单个分区中的最大字节数。此配置仅在使用基于文件的源(如Parquet、JSON和ORC)时有效:
--conf spark.sql.files.maxPartitionBytes=9437184 \

样例中每个 parquet 文件为 8M,规定最大 partition 大小为 9M,只要 8+8 合并,16M 就会超过 9M 的限制,下面看下这样配置是否生效:

 编辑
编辑
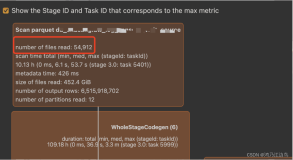
这次没有问题了,Scan 扫描了 3个 RDD,LogInfo 打印了3个 RDD 的日志。
结论:将 maxPartitionBytes 调整到文件大小附近可以实现 Partition - Task 的一对一处理。
五.spark.sql.parquet.adaptiveFileSplit
该参数是控制 SparkSql 文件切分的自适应开关,但是并不是在读取处切分,而是针对读取内容切分,例如 Parquet 存储10列,程序只用到2列,程序内会进行优化逻辑。
--conf spark.sql.parquet.adaptiveFileSplit=false \


 编辑
编辑
结论:adaptiveFileSplit 参数不能实现 Partition - Task 的一对一处理。
六.spark.sql.adaptive.enabled

 编辑
编辑
spark.sql.adaptive.enabled 参数主要应用于 sql 查询时的自适应操作,在 file 读取操作时添加未生效:
--conf spark.sql.adaptive.enabled=false \


 编辑
编辑
结论:spark.sql.adaptive.enabled 适用于查询不适用于读取分区合并,不能实现 Task-Partition 一对一操作。
七.总结
尝试了这么多参数,只有 spark.sql.files.maxPartitionBytes 参数满足了 Task-Partition 一一对应的需求,不过这里也不是真实意义上的一一对应,查看 Executor 的日志可以看到:

 编辑
编辑
A.一一对应
虽然配置的是 P[Executor] x Q[Core] = M [Parquet Num],预想的 Task-Partition 一对一是每一个 Core 都执行到一个 Parquet,但实际操作中有个 Core 执行了 N 个 Parquet,N > 1,而有一些 Core 则一个 Parquet 都没有执行,所以上述 maxPartitionBytes 近满足了每个 parquet 文件不被拆分的被一个 task 执行,并不能保证每个 core 都只执行1个 parquet,即使资源和core分配满。
B.有多有少
为什么出现有多有少的情况,因为一些 Executor 指定较快或率先申请到资源启动,所以此时会将其他还未执行或还在等待资源的 Task 调度到快的或者已经执行完的 Executor 上执行,上述任务是小数据量下的 WordCount 所以很快执行完毕,如果每个任务都持续时间较长且分配资源都正常,则可以达到真正的一个 core 执行一个 Parquet。
C.Task 数量
可以看到,大部分配置或者默认配置都是将小的 parquet 合并,因为这样即节省资源同时运行速度不会受太大影响。实际生产环境中,如果没有特殊的需求可以不完全要求一个 parquet 对应一个 task,如果想要将 task 的量优化到合理的范围内,可以参照自己的程序,例如 Parquet 一共10列,程序内使用 5列,则可以将对应的 maxPartitionBytes 参数调大到相应文件大小的5倍,这样虽然总数据量是5倍,但是实际读取的列数只相当于一个 parquet 的 10列,其次注意 spark 一个 block 默认为 128m,考虑到并行和资源相对充沛的情况下,也无需将 maxPartitionBytes 改的过大。