定义
**<font color="#33aaff">延迟消息</font>:** 生产者发送消息之后,不能立刻被消费者消费,而是应该等到一定时间之后才可以被消费。
**例如:** 在淘宝购物时,当用户提交一个订单之后,如果30min还没有支付的话,就给用户发送一条提示消息
Broker提供延迟消息功能的核心思路是一致的:将延迟消息先存放在一个临时的空间里,等到期后才发送给Topic

如上图所示,实现延迟消息的步骤如下:
1. Producer发送一个延迟消息
2. Broker将其通过临时存储进行存储
3. 延迟服务(delay service)检查消息持否到期,将到期的消息投递到目标Topic里
4. 消费者消费延迟消息
根据上面的流程不难发现,临时存储和延迟服务是实现延迟消息的关键,并且外部的Producer和Consumer是感知不到的
> RocketMQ将延迟消息存储在一个内部主题`SCHEDULE_TOPIC_XXXX`里,只支持固定的时间精度,如5s、10s、1min等
> Kafka原生不支持延迟消息,此时就可以借助代理 + 第三方存储来实现延迟消息
如果要借助第三方存储服务,则在技术选型时需要满足一下几个条件:
**1. 高性能:** 写入延迟要低,MQ的一个重要作用是削峰填谷,所以在高峰期写入性能一定要高,MySQL就不满足
**2. 高可靠:** 延迟消息写入之后,不能丢失
**3. 支持排序:** 要支持按照时间先后来排序,例如先发一条10s的延迟消息A,再发一条5s的延迟消息B,B要比A先消费掉
<br/>
# DDMQ
DDMQ就使用了代理 + 第三方存储来实现延迟消息:
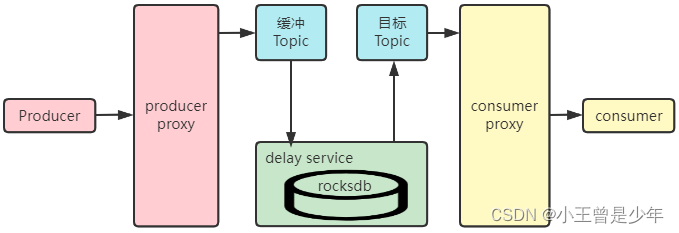
上图的第三方存储技术选型是`rocksdb`,它是一个高性能KV存储(类似于Redis),并且支持排序
**执行步骤:**
1. 生产者将延迟消息发送给代理,代理将其发送到一个缓冲Topic中
2. 消息存储在`rocksdb`里,以时间为key
3. delay service判断消息时间到期后就将其发送到目标Topic里
4. 消费者消费Topic里的数据
<br/>
不难发现,这种设计体现了解耦的思路:
- delay service的延迟投递能力是独立于Broker实现的,无序对Broker做任何改造,所以理论上对于任意MQ类型都可以提供延迟消息能力
## delay service的设计细节
- **高可用:** delay service以分布式部署了多个节点
- **最终一致性:** 每个delay service都要消费缓冲Topic的全量数据,这样就有了多个备份,可以保证数据不丢失
- **避免重复消费:** delay service选择一个主节点Master将消息投递到目标Topic里,这一步可以借助zookeeper来实现
- Master需要将自己当前已经投递到的时间记录到一个共享存储里,如果Master挂了,则会重新选举出一个新的Master,从之前的时间点继续开始投递
<br/><br/>
# RocketMQ中的延迟消息
RocketMQ默认只支持18个时间延迟消息,由配置项`messageDelayLevel`决定:
```java
messageDelayLevel=1s 5s 10s 30s 1m 2m 3m 4m 5m 6m 7m 8m 9m 10m 20m 30m 1h 2h
```
Broker每个节点在启动时都会创建18个级别的队列,如果想要修改,直接在安装了RocketMQ的机器上修改配置文件即可。
## 生产者发送延迟消息
只需要设置一下延迟级别,延迟级别对应上面`messageDelayLevel`的索引:
```java
Message msg = new Message();
msg.setTopic("Topic A");
msg.setTags("Tag A");
msg.setBody("delay message".getBytes());
// 设置延迟级别 = 1,对应延迟1s
msg.setDelayTimeLevel(1);
```
如果设置的延迟级别超过最大值,则会自动设置成最大值
## Broker端处理延迟消息
Broker端处理延迟消息一共分为5个步骤,如下图所示:
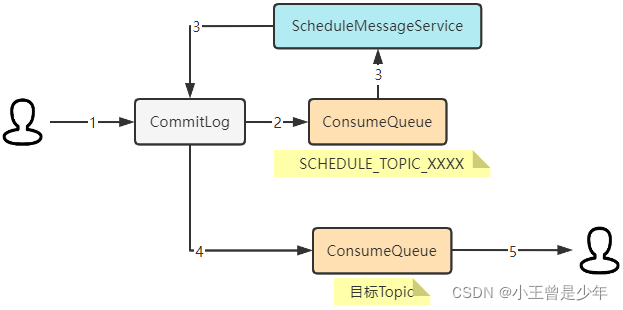
**整个过程分为5个步骤:**
1. 生产者发送延迟消息到Broker里
2. 把消息转发到`SCHEDULE_TOPIC_XXXX`主题下的队列中
3. 延迟服务定期消费`SCHEDULE_TOPIC_XXXX`主题下的消息,到时间了就把它拿到`CommitLog`中
4. 消息重新被投放到目标`Topic`里
5. 消费者消费延迟消息
<hr/>
**1. 生产者发送延迟消息到Broker里**
```java
public PutMessageResult putMessage(final MessageExtBrokerInner msg) {
//事务消息处理
if (tranType == MessageSysFlag.TRANSACTION_NOT_TYPE
|| tranType == MessageSysFlag.TRANSACTION_COMMIT_TYPE) {
// 如果是延迟消息
if (msg.getDelayTimeLevel() > 0) {
// 如果设置的值过大,则设置为最大延迟级别
if (msg.getDelayTimeLevel() > this.defaultMessageStore.getScheduleMessageService().getMaxDelayLevel()) {
msg.setDelayTimeLevel(this.defaultMessageStore.getScheduleMessageService().getMaxDelayLevel());
}
// 修改Topic
topic = ScheduleMessageService.SCHEDULE_TOPIC;
// 根据延迟级别,决定要将其投递到那个队列中
queueId = ScheduleMessageService.delayLevel2QueueId(msg.getDelayTimeLevel());
// 记录原始的 topic 和 队列信息
MessageAccessor.putProperty(msg, MessageConst.PROPERTY_REAL_TOPIC, msg.getTopic());
MessageAccessor.putProperty(msg, MessageConst.PROPERTY_REAL_QUEUE_ID, String.valueOf(msg.getQueueId()));
msg.setPropertiesString(MessageDecoder.messageProperties2String(msg.getProperties()));
// 修改topic和队列信息
msg.setTopic(topic);
msg.setQueueId(queueId);
}
}
// ......
}
```
可以看到,RocketMQ的Broker端在存储生产者写入消息时,首先将其写入`CommitLog`里,为了不让用户立刻就能消费到这条消息,这里先将`Topic`的名称修改为`SCHEDULE_TOPIC_XXXX`,并且根据设置的延迟级别选择将消息投放到哪一个队列里。
在修改`Topic`的名称时,还会将原来要发送到的`Topic`和队列信息存储在消息的属性里
<br/>
**2. 把消息转发到`SCHEDULE_TOPIC_XXXX`主题下的队列中**
这一步的操作是异步执行的,在转发过程中会对延迟消息进行特殊处理,主要是计算这条消息什么时间要被投递到最终的`Topic`里
> 投递时间 = 存储消息的世界 + 延迟时间
ConsumeQueue的单个存储结构如图所示:

- `Commit Log Offset`:消息在Commit中的存放位置
- `Size`:消息体大小
- `Message Tag HashCode`:消息Tag的hash值记录在此。对于延迟消息,这里记录的是消息的投递时间,<font color = "#ff3333">所以才是8Byte而不是4Byte</font>
```java
public DispatchRequest checkMessageAndReturnSize(java.nio.ByteBuffer byteBuffer, final boolean checkCRC, final boolean readBody) {
// ......
try {
// ......
{ // 获取延迟级别
String t = propertiesMap.get(MessageConst.PROPERTY_DELAY_TIME_LEVEL);
// 如果消息需要投递到`SCHEDULE_TOPIC_XXXX`主题里
if (ScheduleMessageService.SCHEDULE_TOPIC.equals(topic) && t != null) {
int delayLevel = Integer.parseInt(t);
// 延迟级别大于0,则计算目标投递时间,并将其记录在Message Tag HashCode里
if (delayLevel > 0) {
tagsCode = this.defaultMessageStore.getScheduleMessageService().computeDeliverTimestamp(delayLevel,
storeTimestamp);
}
}
}
}
// ....
return new DispatchRequest(//
topic, // 1
queueId, // 2
physicOffset, // 3
totalSize, // 4
tagsCode, // 5
storeTimestamp, // 6
queueOffset, // 7
keys, // 8
uniqKey, //9
sysFlag, // 9
preparedTransactionOffset// 10
);
} catch (Exception e) {
}
return new DispatchRequest(-1, false /* success */);
}
```
<br/>
**3. 延迟服务定期消费`SCHEDULE_TOPIC_XXXX`主题下的消息,到时间了就把它拿到`CommitLog`中**
Broker内部的`ScheduleMessageService`类提供延迟服务,该服务消费`SCHEDULE_TOPIC_XXXX`主题下的消息,并投递到目标`Topic`下。
```java
public void start() {
if (started.compareAndSet(false, true)) {
// 创建定时器
this.timer = new Timer("ScheduleMessageTimerThread", true);
// 循环所有的延迟级别,delayLevelTable记录每个延迟级别对应的延迟时间
for (Map.Entry<Integer, Long> entry : this.delayLevelTable.entrySet()) {
Integer level = entry.getKey();
Long timeDelay = entry.getValue();
Long offset = this.offsetTable.get(level);
if (null == offset) {
offset = 0L;
}
// 针对每个延迟级别创建一个TimerTask
if (timeDelay != null) {
this.timer.schedule(new DeliverDelayedMessageTimerTask(level, offset), FIRST_DELAY_TIME);
}
}
this.timer.scheduleAtFixedRate(new TimerTask() {
@Override
public void run() {
try {
if (started.get()) ScheduleMessageService.this.persist();
} catch (Throwable e) {
log.error("scheduleAtFixedRate flush exception", e);
}
}
}, 10000, this.defaultMessageStore.getMessageStoreConfig().getFlushDelayOffsetInterval());
}
}
```
可以看出,`ScheduleMessageService`启动时会启动一个`Timer`,并根据延迟级别的个数创建对应数量的`TimerTask`,每个`TimerTask`负责一个延迟级别中的消息的投递。
<font color="#aaaaff">每个`TimerTask`在检查消息是否到期时,首先会检查对应队列中尚未投递的第一条消息,如果这条消息没到期,说明后面的消息都没到期,就不用再做进一步的检查了。</font>
<br/>
在第1步执行时,已经存下了原先要投递到的目标`TOPIC`和队列信息,这里只需要重新设置一下即可。此外,在第2步的执行过程里`Message Tag HashCode`存储的是消息的投递时间,这里要重新计算成生产者设置的Tag的hash值。
<br/>
**4. 消息重新被投放到目标`Topic`里**
与第2步类似,只不过这里的`Topic`已经改成了目标`Topic`,此时消费者就可以消费到这条消息
<br/><br/>
# 延迟消息与消息重试机制的关系
RocketMQ提供了消息消费失败重试的机制,当消息被消费失败时,如果返回的值是`RECONSUME_LATER`的话就会重试:
```java
DefaultMQPushConsumer consumer = new DefaultMQPushConsumer();
consumer.registerMessageListener(new MessageListenerConcurrently() {
public ConsumeConcurrentlyStatus consumeMessage(List<MessageExt> list, ConsumeConcurrentlyContext consumeConcurrentlyContext) {
return ConsumeConcurrentlyStatus.RECONSUME_LATER;
}
});
```
默认的重试次数是16次,并且会随着失败次数的增加,重试的时间间隔也会增加,具体如下表:
| 重试次数 | 时间间隔 |重试次数 |时间间隔 |重试次数 |时间间隔 |重试次数 |时间间隔 |
|--|--|--|--|--|--|--|--|
| 1 | 10s |5 | 3min|9 | 7min| 13|20min |
|2 |30s |6 |4min | 10|8min | 14|30min |
| 3 | 1min |7 |5min |11 |9min | 15|1h |
| 4 | 2min | 8|6min |12 |10min |16 | 2h|
实际上,消息重试的时间间隔,就对应延迟消息的后16个级别:
messageDelayLevel=1s5s10s30s1m2m3m4m5m6m7m8m9m10m20m30m1h2h
原因是消息重试的底层也是借助延迟消息来实现的,在消费失败的情况下会重新把消息当做延迟消息投递回去,官方文档也给了说明: