
Neo4j企业版支持Prometheus,可以将集群指标采集到安装目录的../neo4j/metrics目录下,而Prometheus本身的可视化做的并不好,因此利用Grafana进行可视化展示。
在写这篇博客之前没有搜到搭建教程,因此记录下自己的搭建过程。
搭建之前需要在neo4j.conf配置文件中添加以下配置,并重启。
metrics.prometheus.enabled=true metrics.prometheus.endpoint=本机IP地址:2004
至于完整的Neo4j安装教程可以参考我以前的两篇博客
Neo4j单机部署教程(企业版) Neo4j三核心因果集群部署教程(企业版)
开始搭建(以三核心集群为例)
准备工作
所需软件及下载地址:
node_exporter-*.tar.gz(主机信息采集)及prometheus-*.tar.gz:官网下载地址,同一个页面中。
grafana-*.rpm:官网下载地址
grafana-piechart-panel-*.zip(grafana监控模板中有饼图,需要这个插件):官网下载地址
grafana监控模板:官网下载地址
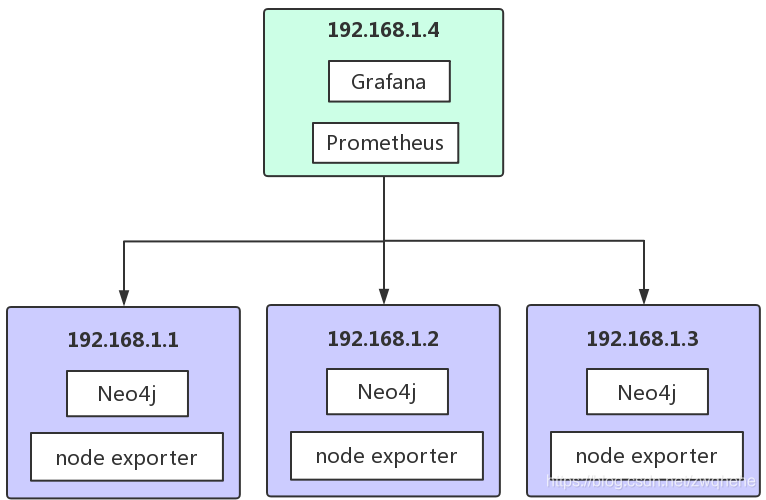
部署Prometheus和Grafana的服务器:192.168.1.4
被监控服务器(即运行Neo4j的服务器):192.168.1.1、192.168.1.2、192.168.1.3
架构如下:
一、在运行Neo4j的服务器安装node_exporter
在三台服务器上, 直接解压运行
解压 tar -zxvf node_exporter-*.tar.gz 进入文件夹 cd node_exporter-* 运行 ./node_exporter &
二、安装prometheus
建议单独部署在一台服务器上。
1、部署。步骤如下:
解压 tar -zxvf prometheus-*.tar.gz 进入文件夹 cd prometheus-* 配置 vi prometheus.yml 添加以下内容(在scrape_configs:下添加) # 监控作业的名字,起集群名字就好 - job_name: 'Neo4j-cluster-1' static_configs: # 集群内的节点IP地址 - targets: ['192.168.1.1:2004','192.168.1.2:2004','192.168.1.3:2004'] 启动prometheus ./prometheus --config.file=prometheus.yml &
2、登录。启动之后,登录prometheus查看配置是否成功。地址:192.168.1.4:9000
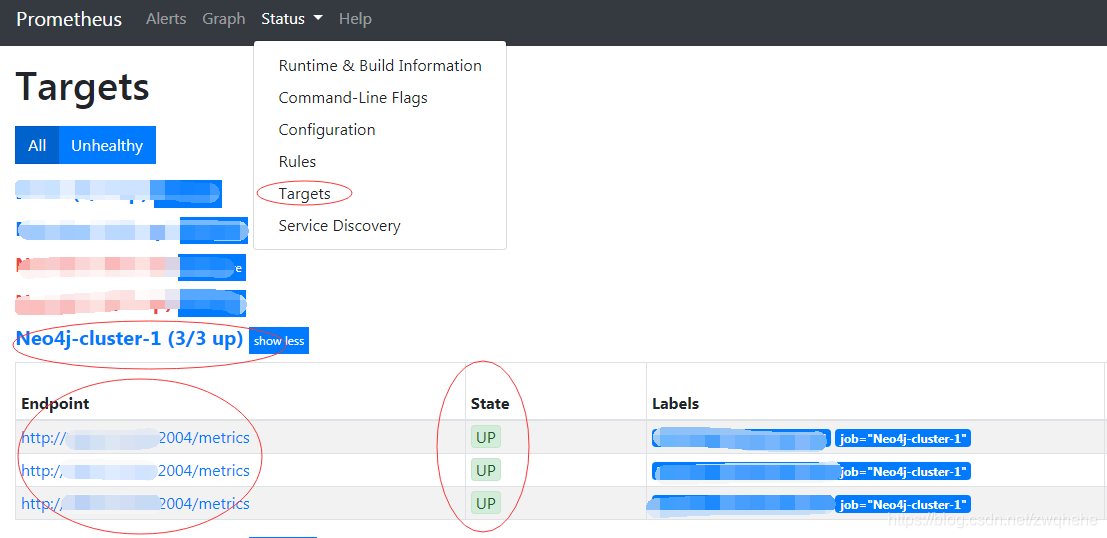
3、检查。点击页面的Status-->Targets。查看job名是不是对的,endpoint地址是不是集群的节点地址,state是不是都是up。如下图:
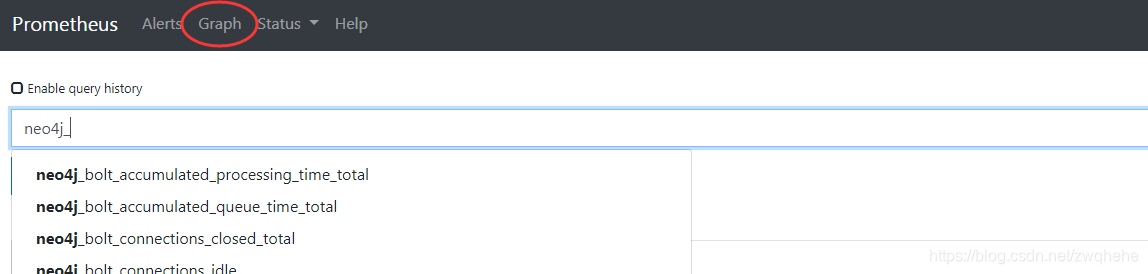
再点击Graph,这里可以查到已经采集到的Neo4j指标,如下图:
至此,Prometheus已经完成了,开始安装Grafana!
三、Grafana部署(这里主要贴下我的配置)
1、直接运行以下命令安装
rpm -ivh grafana-*.rpm
2、启动
service grafana-server start
3、登录
192.168.1.4:3000,默认账号密码admin/admin
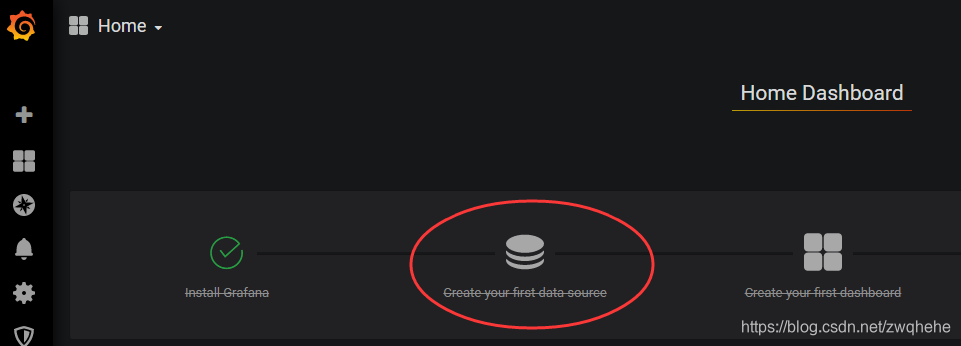
4、创建数据源,如下图:
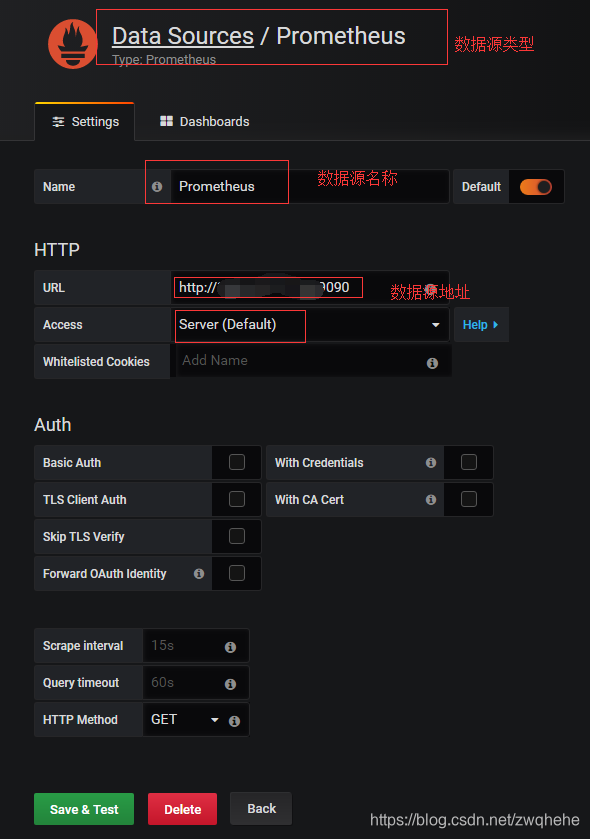
5、数据源配置如下:
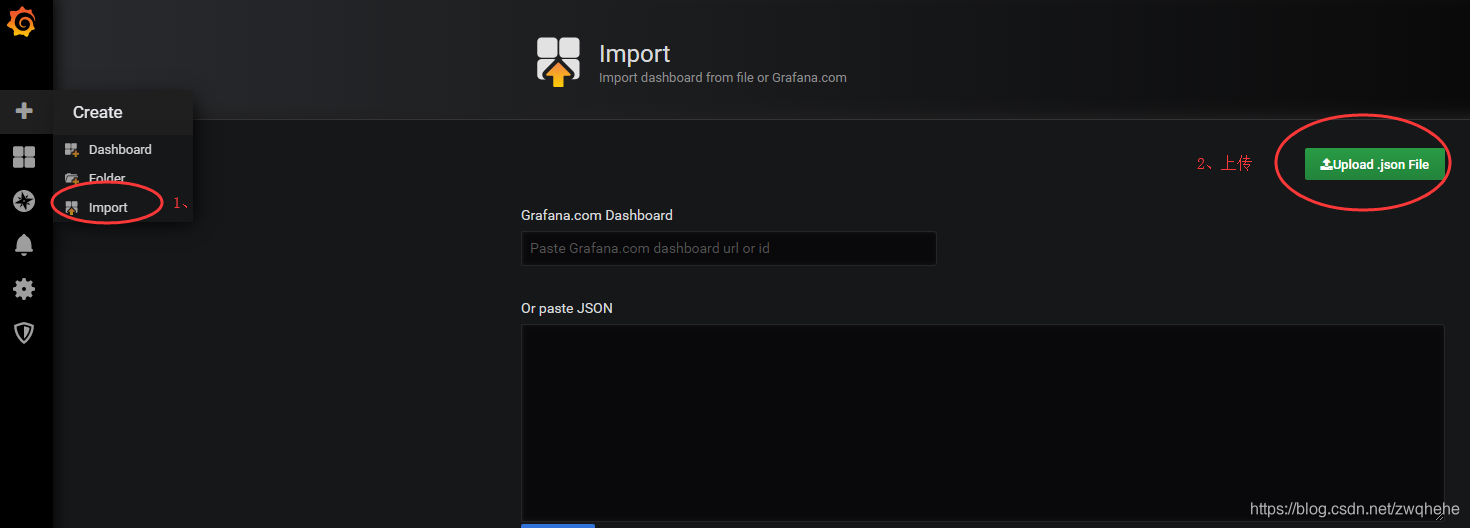
6、导入前面下载的Neo4j模板
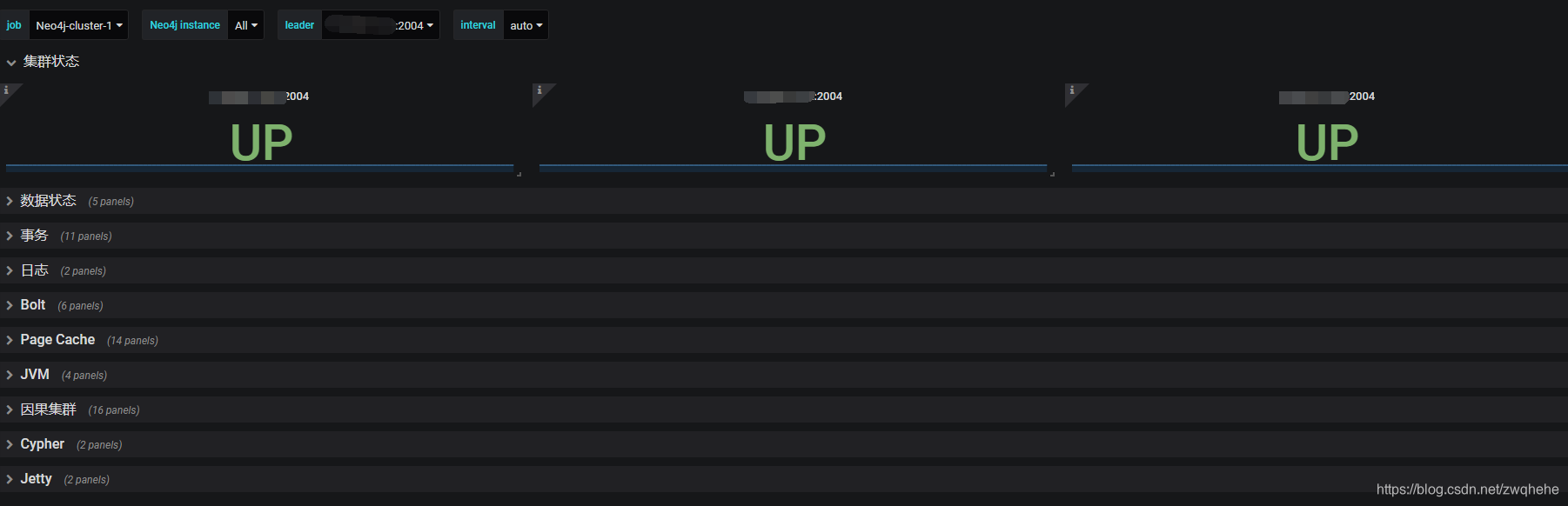
效果如下(我在模板的基础上新增了面板,并进行了分类):
到了这里应该会遇到一个问题,就是模板中的仪表盘数据无法加载,那么将前面下载的grafana-peichart-panel插件拷贝至/var/lib/grafana/plugins/目录下,并 chmod 777 plugins(务必要做,我就因为这个气的吐血)
7、如果一点数据都么有,那八成是模板的变量设置有问题,导致无法读取Prometheus的数据。我当初就做了点修改才有的数据,具体改了什么也记不清了,我把最终配置全贴出来供大家参考。修改变量的地方:点击上一页面右上角的小齿轮,在点击下图侧边栏的Variables就可以看到了。
总共四个变量,如下图:
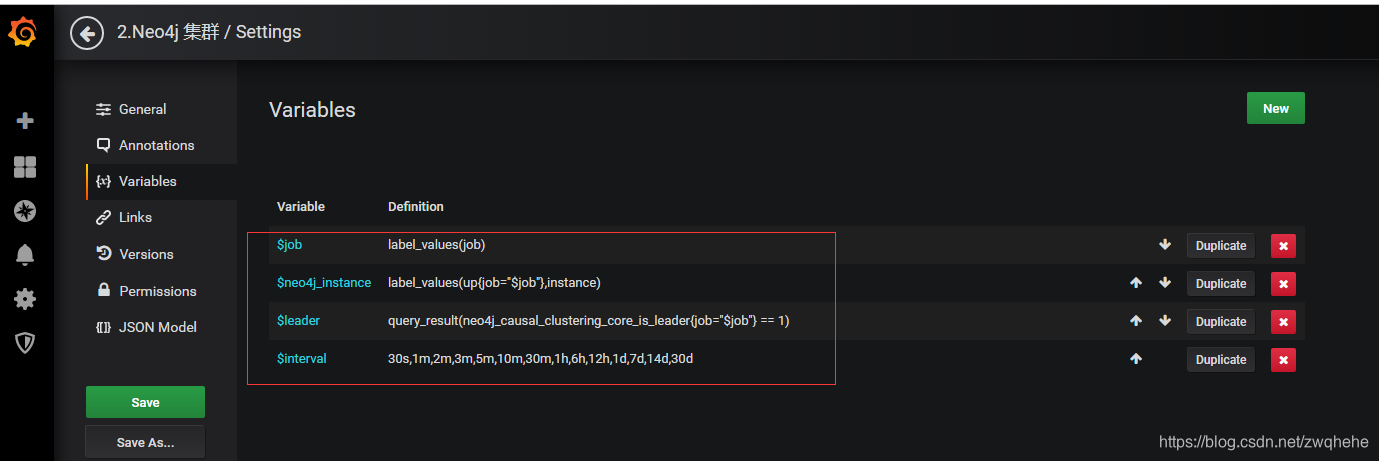
$job变量配置:
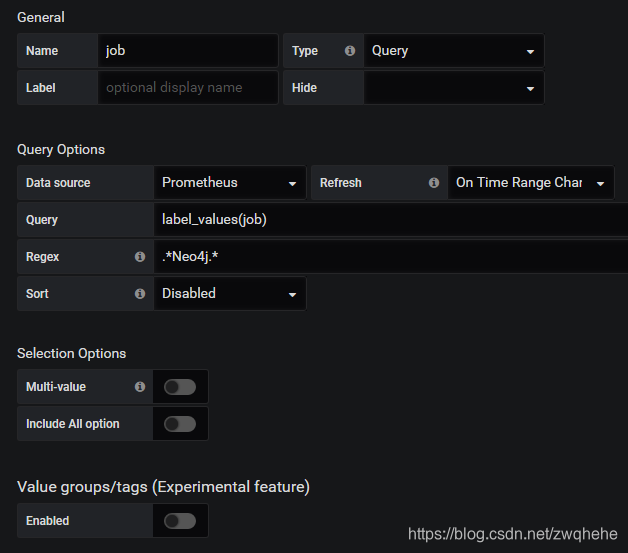
$neo4j_instance变量配置:
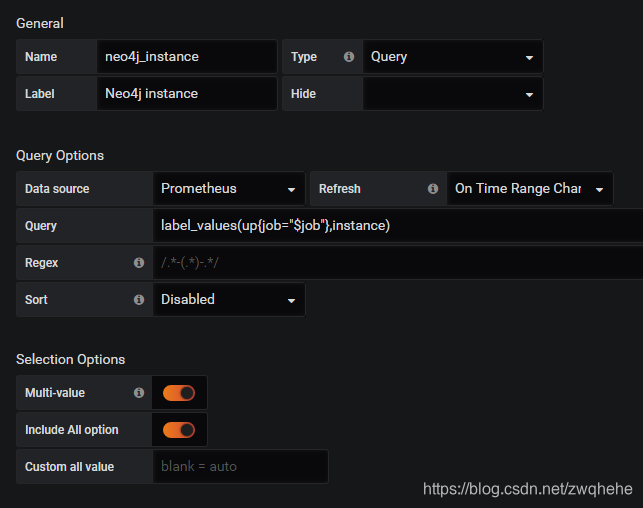
$leader变量配置
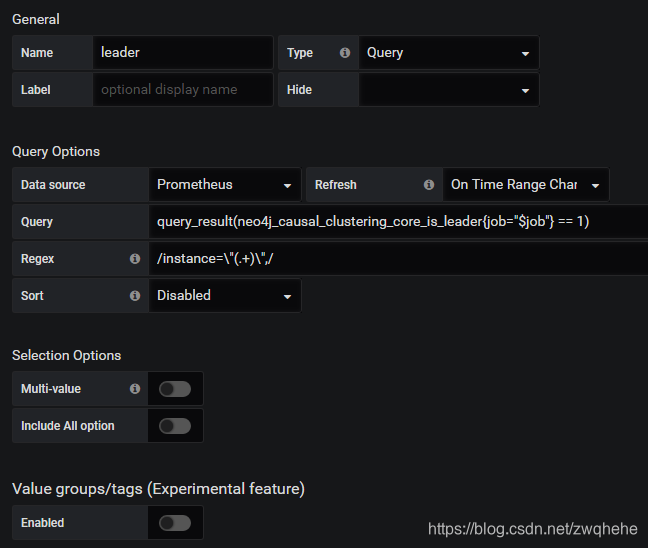
由于几个月前搭建的,可能有些步骤会有遗漏,有问题可以评论哦。
周五了,溜了溜了。
