Paxos 作为一个经典的分布式一致性算法(Consensus Algorithm),在各种教材中也被当做范例来讲解。但由于其抽象性,很少有人基于朴素 Paxos 开发一致性库,而 RAFT 则是工业界里实现较多的一致性算法,RAFT 的论文可以在下面参考资料中找到(In Search of an Understandable Consensus Algorithm),RAFT 通过引入强 leader 角色,解决了 Paxos 算法中很多工程实现难题,同时引入了日志+状态机的概念,将多节点同步进行了高度抽象,解决了很多问题。这里我之所以反其道而行之,选择 Paxos 进行实现,主要是因为:
- Paxos 开源实现较少,经典,各种定义高度抽象(适合作为通用库),挑战性强
- 正确性不依赖 leader 选举,适合快速写入节点切换(抢主),本实现里,单paxos group,3节点本地回环内存存储,3节点并发写性能16k/s,10ms leader lease优化43k/s(MBP13 2018下测试)
- 实现限制少,扩展性强
本实现代码参考了 RAFT 中的概念以及 phxpaxos 的实现和架构设计,实现 multi-paxos 算法,主要针对线程安全和模块抽象进行强化,网络、成员管理、日志、快照、存储以接口形式接入,算法设计为事件驱动,仅包含头文件,便于移植和扩展。
本文假设读者对 Paxos 协议有一定的了解,并不会对 Paxos 算法的推导证明和一些基本概念做过多讲解,主要着重于 Paxos 的工程实现。如果读者对 Paxos 算法的推导证明感兴趣可以阅读参考资料中的相关论文资料。
有了 Paxos 可以干什么
Paxos 如此知名,写了个库可以干些啥炫酷的事情呢?
最直观的,你可以在 Paxos 基础上实现一个分布式系统,它具备:
- 强一致性,保证各个节点的数据都是一样的,及时并发地在多个节点上做写操作
- 高可用性,例如3节点的 Paxos 系统,可以容忍任何一个节点挂掉,同时继续提供服务
基于 Paxos 系统的日志+状态机,可以轻易实现带状态的高可用服务,比如一个分布式 KV 存储系统。再结合快照+成员管理,可以让这个服务具备在线迁移、动态添加多副本等诸多高级功能。是不是心动了呢,让我们进入下面的算法实现环节。
代码地址
Talk is cheap, show me the code.
先放代码仓库链接
个人习惯将基础类算法库直接写成头文件,便于后续代码引用和移植到其他项目中,同时可以让编译器充分内联各种函数,缺点是编译时间变慢。公开的代码中,为了减少额外项目引用,仅带了个日志库(spdlog,同样的 header only),单元测试写的比较简单,感兴趣的小伙伴也可以加些更多的测试。
Paxos 算法基础
这里为避免翻译造成错误理解,下面全部拷贝Paxos Made Simple原文作为参考
算法目标
A consensus algorithm ensures that a single one among the proposed values is chosen
- Only a value that has been proposed may be chosen,
- Only a single value is chosen, and
- A process never learns that a value has been chosen unless it actually has been.
一个最朴素的一致性算法的目的,就是在一堆对等节点中协商出一个大家都公认的值,同时这个值是其中某个节点提出的而且在这个值确定后,能被所有节点获知。
算法实现
关于 Paxos 算法的推导证明,已经有很多文章描述了,这里我就不在赘述,毕竟本文的主要目标是实现一个 Paxos 库,我们着重于代码的实现。
Phase 1. (prepare)
- A proposer selects a proposal number n and sends a prepare request with number n to a majority of acceptors.
- If an acceptor receives a prepare request with number n greater than that of any prepare request to which it has already responded, then it responds to the request with a promise not to accept any more proposals numbered less than n and with the highest-numbered proposal (if any) that it has accepted.
Phase 2. (accept)
- If the proposer receives a response to its prepare requests (numbered n) from a majority of acceptors, then it sends an accept request to each of those acceptors for a proposal numbered n with a value v, where v is the value of the highest-numbered proposal among the responses, or is any value if the responses reported no proposals.
- If an acceptor receives an accept request for a proposal numbered n, it accepts the proposal unless it has already responded to a prepare request having a number greater than n.
最基础的流程则是这个两轮投票,为了实现投票,我们需要对描述中的实体进行代码实现。
基类Cbase
base.h 定义了算法中所需要的实体,主要包括,投票 ballot_number_t,值 value_t,acceptor 状态 state_t,角色间传递的消息 message_t。
struct ballot_number_t final {
proposal_id_t proposal_id;
node_id_t node_id;
};
struct value_t final {
state_machine_id_t state_machine_id;
utility::Cbuffer buffer;
};
struct state_t final {
ballot_number_t promised, accepted;
value_t value;
};
struct message_t final {
enum type_e {
noop = 0,
prepare,
prepare_promise,
prepare_reject,
accept,
accept_accept,
accept_reject,
value_chosen,
learn_ping,
learn_pong,
learn_request,
learn_response
} type;
// Sender info.
group_id_t group_id;
instance_id_t instance_id;
node_id_t node_id;
/**
* Following field may optional.
*/
// As sequence number for reply.
proposal_id_t proposal_id;
ballot_number_t ballot;
value_t value;
// For learner data transmit.
bool overload; // Used in ping & pong. This should be consider when send learn request.
instance_id_t min_stored_instance_id; // Used in ping and pong.
std::vector<learn_t> learn_batch;
std::vector<Csnapshot::shared_ptr> snapshot_batch;
};同时 base.h 定义了一个节点的基类 Cbase,用于描述了该基础节点的状态、当前 log instance id、锁等内容,同时提供一些基础的 index 推进、消息收发、成员判别、消息存储功能。下面截取了 Cbase 的部分代码。
template<class T>
class Cbase {
// Const info of instance.
const node_id_t node_id_;
const group_id_t group_id_;
const write_options_t default_write_options_;
std::mutex update_lock_;
std::atomic<instance_id_t> instance_id_;
Cstorage &storage_;
Ccommunication &communication_;
CpeerManager &peer_manager_;
bool is_voter(const instance_id_t &instance_id);
bool is_all_peer(const instance_id_t &instance_id, const std::set<node_id_t> &node_set);
bool is_all_voter(const instance_id_t &instance_id, const std::set<node_id_t> &node_set);
bool is_quorum(const instance_id_t &instance_id, const std::set<node_id_t> &node_set);
int get_min_instance_id(instance_id_t &instance_id);
int get_max_instance_id(instance_id_t &instance_id);
void set_instance_id(instance_id_t &instance_id);
bool get(const instance_id_t &instance_id, state_t &state);
bool get(const instance_id_t &instance_id, std::vector<state_t> &states);
bool put(const instance_id_t &instance_id, const state_t &state, bool &lag);
bool next_instance(const instance_id_t &instance_id, const value_t &chosen_value);
bool put_and_next_instance(const instance_id_t &instance_id, const state_t &state, bool &lag);
bool put_and_next_instance(const instance_id_t &instance_id, const std::vector<state_t> &states, bool &lag);
bool reset_min_instance(const instance_id_t &instance_id, const state_t &state);
bool broadcast(const message_t &msg,
Ccommunication::broadcast_range_e range,
Ccommunication::broadcast_type_e type);
bool send(const node_id_t &target_id, const message_t &msg);
};Proposer 角色 Cpropose
proposer.h 负责实现 Paxos 算法中的 proposer 的行为,包括提出决议,处理 acceptor 回复的消息等。
on_prepare_reply 处理 acceptor 返回 prepare 流程的响应,相对于 Paxos 论文中的描述,这里需要对消息做详细的检测,判断是当前上下文中需要处理的消息后,加入到响应统计集合中,最后根据多数派原则,做出进一步判断,是放弃还是继续进入下一步 accept 流程。
response_set_.insert(msg.node_id);
if (message_t::prepare_promise == msg.type) {
// Promise.
promise_or_accept_set_.insert(msg.node_id);
// Caution: This will move value to local variable, and never touch it again.
update_ballot_and_value(std::forward<message_t>(msg));
} else {
// Reject.
reject_set_.insert(msg.node_id);
has_rejected_ = true;
record_other_proposal_id(msg);
}
if (base_.is_quorum(working_instance_id_, promise_or_accept_set_)) {
// Prepare success.
can_skip_prepare_ = true;
accept(accept_msg);
} else if (base_.is_quorum(working_instance_id_, reject_set_) ||
base_.is_all_voter(working_instance_id_, response_set_)) {
// Prepare fail.
state_ = proposer_idle;
last_error_ = error_prepare_rejected;
notify_idle = true;
}on_accept_reply 处理 acceptor 返回 accept 流程的响应,这里根据 Paxos 中描述,通过多数派原则,判断该提案是否被最终通过,如果通过,则进入 chosen 流程,广播确定的值。
response_set_.insert(msg.node_id);
if (message_t::accept_accept == msg.type) {
// Accept.
promise_or_accept_set_.insert(msg.node_id);
} else {
// Reject.
reject_set_.insert(msg.node_id);
has_rejected_ = true;
record_other_proposal_id(msg);
}
if (base_.is_quorum(working_instance_id_, promise_or_accept_set_)) {
// Accept success.
chosen(chosen_msg);
chosen_value = value_;
} else if (base_.is_quorum(working_instance_id_, reject_set_) ||
base_.is_all_voter(working_instance_id_, response_set_)) {
// Accept fail.
state_ = proposer_idle;
last_error_ = error_accept_rejected;
notify_idle = true;
}Acceptor 角色 Cacceptor
acceptor.h 负责实现 Paxos 算法中 acceptor 的行为,处理 proposer 的请求,同时进行持久化、推高 log instance id 等。同时 Cacceptor 还有个重要使命,就是在初始化时候,加载已有的状态,保证 promise 的状态以及 accept 的值。
on_prepare 对应收到 prepare 请求后的处理,针对提案投票号,决定返回消息,及 promise 状态持久化。
if (msg.ballot >= state_.promised) {
// Promise.
response.type = message_t::prepare_promise;
if (state_.accepted) {
response.ballot = state_.accepted;
response.value = state_.value;
}
state_.promised = msg.ballot;
auto lag = false;
if (!persist(lag)) {
if (lag)
return Cbase<T>::routine_error_lag;
return Cbase<T>::routine_write_fail;
}
} else {
// Reject.
response.type = message_t::prepare_reject;
response.ballot = state_.promised;
}on_accept 对应处理收到的 accept 请求的处理,根据自身状态和提案号,决定是更新当前状态还是返回拒绝,最终将合适的 accept 状态和 value 持久化。
if (msg.ballot >= state_.promised) {
// Accept.
response.type = message_t::accept_accept;
state_.promised = msg.ballot;
state_.accepted = msg.ballot;
state_.value = std::move(msg.value); // Move value to local variable.
auto lag = false;
if (!persist(lag)) {
if (lag)
return Cbase<T>::routine_error_lag;
return Cbase<T>::routine_write_fail;
}
} else {
// Reject.
response.type = message_t::accept_reject;
response.ballot = state_.promised;
}on_chosen 是处理 proposer 广播的对应值确定的消息,经过判别后,会推高当前 log instance id,让当前节点进入下一个 value 的判断(multi-paxos 的逻辑)。
if (base_.next_instance(working_instance_id_, state_.value)) {
chosen_instance_id = working_instance_id_;
chosen_value = state_.value;
} else
return Cbase<T>::routine_error_lag;Paxos 算法进阶
Multi-Paxos
至此,我们实现了论文中两个基本角色的基础功能,同时也非常明显的,这两个角色并没什么用,只能确定一个固定的值,这时就需要引入 multi-paxos 算法了。既然确定一个值没有用,那么,确定一系列值,就可以结合状态机实现更加复杂的功能了。这个就是之前提到的 log instance id 了,这个是个从0开始的u64。
typedef uint64_t instance_id_t; // [0, inf)这时很简单就能实现一个多值的序列,每个值都使用 Paxos 的算法进行确认。如下所示,instance_id_t 从0开始,依次递增,proposer 通过 prepare & accept 流程依次确定值。value 是一系列操作,我们就能通过状态机实现多节点间的强一致同步了。
| instance_id_t | 0 | 1 | 2 | 3 | ... | inf |
|---|---|---|---|---|---|---|
| value_t | a=1 | b=2 | b=a+1 | a=b+1 | ... | |
| Paxos | prepare accept |
prepare accept |
prepare accept |
prepare accept |
... |
这里不难发现,每个值的确定,都至少需要2次通信RT(on_chosen 的消息可以被 pipeline,并不占用延迟)+2次磁盘IO,这个代价是相当大的。但 Paxos 文中也提出了 multi-paxos 思路。
Key to the efficiency of this approach is that, in the Paxos consensus algorithm, the value to be proposed is not chosen until phase 2. Recall that, after completing phase 1 of the proposer’s algorithm, either the value to be proposed is determined or else the proposer is free to propose any value.
简而言之,就是:
- value可以不仅仅是一个值,而是一个序列的值(把这些序列看成一个整套,理解为一个大值,花了多次网络进行传输),在复用 proposer id 的情况下,可以多次走 phase 2 accept 流程,实现序列值的提交
- 该优化没有打破paxos的假设及要求,因此 leader 并不是 multi-paxos 的必须项
- 该连续流程随时能被更高的 proposer id 打断(理解为新值的抢占,中断之前的传输,同样没有打破之前值的约束,只是被剪短了)
这时候,一个理想情况是,一个节点抢占并被认可了一个 proposer id 之后,用 accept 进行连续提交。每个值的确定精简为1次通信RT+1次磁盘IO,也就是多节点数据同步的最优代价。
| instance_id_t | 0 | 1 | 2 | 3 | ... | inf |
|---|---|---|---|---|---|---|
| value_t | a=1 | b=2 | b=a+1 | a=b+1 | ... | |
| Paxos | prepare accept |
accept | accept | accept | ... |
同时,我们在实现的基础上可以引入一些机制,加快某些不必要的流程,进行性能的优化。
- proposer.h 中使用 can_skip_prepare 和 has_rejected 判断是否跳过可以 prepare 流程以及在被拒后(任何其他节点的 proposer 抢占更高 proposer id)退回到2阶段流程
- 虽然多个节点之间抢占写入并不会带来正确性问题,但多次抢占导致没有任何节点能长期进行连续 accept 优化,这里引入了 leader_manager.h,在 accept 后,无脑拒绝任何其他节点的 prepare 一段时间,让 accept 成功的节点能持续独占 acceptor 一段时间,可以在高冲突的场景下,在时间窗口中完成连续 accept 提交。
learner 角色
learner 用于快速学习已确定的 log instance
To learn that a value has been chosen, a learner must find out that a proposal has been accepted by a majority of acceptors. The obvious algorithm is to have each acceptor, whenever it accepts a proposal, respond to all learners, sending them the proposal. This allows learners to find out about a chosen value as soon as possible, but it requires each acceptor to respond to each learner—a number of responses equal to the product of the number of acceptors and the number of learners.
论文中的方法是询问所有 acceptor,确定多数派的value,这里我们通过 proposer 的 on_chosen 广播 proposer id,让所有其他节点知道哪个值已经被确定,快速推升 log instance id,也有助于节点知道哪些值可以被传递到状态机进行回放。learner.h 通过 ping 包的形式,了解各个对等节点的被确定的 log instance id,选择合适的节点进行快速学习,实际工程中会根据落后程度和 log 被裁剪的情况,选择通过 log 还是 snapshot 的方式进行学习。
网络、成员、日志、状态机插件化
根据 Paxos Made Live 中的描述,实现正确的 Paxos 的难度不仅在于实现标准 Paxos 算法,更在于其消息传输和存储可靠的假设(非拜占庭错误),quorum准确判断(成员变更)等。解决这个问题的方式是,使用接口将这部分同核心算法分离开来,交给更专业的人或库去解决,而我们仅专精于当前的算法、优化和调度(让库成为无状态的)。同时这种分离的做法,可以让 Paxos 工作在已有的存储、网络系统之上,避免额外引入的存储或网络带来冗余、影响性能。
因此所有非 Paxos 算法的假设和实现,都通过接口的方式接入到核心算法中。包括存储、通信、成员管理和状态机和快照。当然为了测试,代码中提供了最简单的基于队列的通信,可以模拟随机延迟、乱序、丢包等非拜占庭错误,内存存储。后面附录会附上 RocksDB 实现的存储、支持变更的成员管理+成员状态机+快照实现以及基于 asio 的 TCP&UDP 混合的通信系统。
单 Paxos Group 角色融合 Cinstance
proposer acceptor learner 三角色齐全了,下面就需要一个管理对象把他们融合到一起,形成一个 Paxos Group 了,这里我们使用的是 instance.h 这个类 Cinstance,通过模板的方式实现0损耗的接口,规避虚函数的调用代价,将三个角色以及处理 log instance 推进、通信、存储和状态机的 Cbase 完全连接起来。为了外部调用方便,Cinstance 也提供了带流控的阻塞接口,给定各种超时参数,向 Paxos Group 中提交一个值,在成功或超时后返回。为了让角色直接充分解耦,所有涉及到角色状态流转的接口都暴露出来,以回调的方式在 Cinstance 中处理,也能直观地在一个代码上下文中处理这些交互信息,尽可能减少逻辑bug。
void synced_value_done(const instance_id_t &instance_id, const value_t &value);
void synced_reset_instance(const instance_id_t &from, const instance_id_t &to);
Cbase::routine_status_e self_prepare(const message_t &msg);
Cbase::routine_status_e self_chosen(const message_t &msg);
void on_proposer_idle();
void on_proposer_final(const instance_id_t &instance_id, value_t &&value);
void value_chosen(const instance_id_t &instance_id, value_t &&value);
void value_learnt(const instance_id_t &instance_id, value_t &&value);
void learn_done();
Cbase::routine_status_e take_snapshots(const instance_id_t &peer_instance_id, std::vector<Csnapshot::shared_ptr> &snapshots);
Cbase::routine_status_e load_snapshots(const std::vector<Csnapshot::shared_ptr> &snapshots);多线程化
这里的实现主要是工程上的实现,这里只提下基本思路,具体实现可以参考代码。
- Paxos 算法成功地将几个角色完全分解开来,除了 log instance 推进需要严格顺序进行,其他角色都可以在任意 log instance id 上进行,角色内部状态机通过锁控制
- 通过在持久化和推进 log instance id 的时候,短暂持有全局锁,尽可能减少串行化点,同时通过原子变量快速判断当前角色是否落后
- 完全事件推动模型(包括超时和状态变更)
- 超时及任务队列timer_work_queue.h
- 可重置超时机制resetable_timeout_notify.h
log+状态机+snapshot(日志压缩)
序列化的值已经就绪了,实现完整的带状态的应用就差状态机了,RAFT 里面已经有了完整叙述,这里我们同样把设计为日志+状态机的实现,为了 learner 快速学习,同样提供了快照的接口。进一步的,因为有了快照,我们就不需要保留完整的日志了,通过快照就能快速重放到对应的 log instance id,实现快速学习。同样日志、状态机、快照都采用接口方式实现,参考 state_machine.h 部分代码,接口中预留了很多辅助类操作接口,便于实现无阻塞的快照获取和应用。

class Csnapshot {
public:
// Get global state machine id which identify myself, and this should be **unique**.
virtual state_machine_id_t get_id() const = 0;
// The snapshot represent the state machine which run to this id(not included).
virtual const instance_id_t &get_next_instance_id() const = 0;
};
class CstateMachine {
public:
// Get global state machine id which identify myself, and this should be **unique**.
virtual state_machine_id_t get_id() const = 0;
// This will be invoked sequentially by instance id,
// and this callback should have ability to handle duplicate id caused by replay.
// Should throw exception if get unexpected instance id.
// If instance's chosen value is not for this SM, empty value will given.
virtual void consume_sequentially(const instance_id_t &instance_id, const utility::Cslice &value) = 0;
// Supply buffer which can move.
virtual void consume_sequentially(const instance_id_t &instance_id, utility::Cbuffer &&value) {
consume_sequentially(instance_id, value.slice());
}
// Return instance id which will execute on next round.
// Can smaller than actual value only in concurrent with consuming, but **never** larger than real value.
virtual instance_id_t get_next_execute_id() = 0;
// Return smallest instance id which not been persisted.
// Can smaller than actual value only in concurrent with consuming, but **never** larger than real value.
virtual instance_id_t get_next_persist_id() = 0;
// The get_next_instance_id of snapshot returned should >= get_next_persist_id().
virtual int take_snapshot(Csnapshot::shared_ptr &snapshot) = 0;
// next_persist_id should larger or equal to snapshot after successfully load.
virtual int load_snapshot(const Csnapshot::shared_ptr &snapshot) = 0;
};其次为了实现更高级的功能,算法提供了2套 value chosen 回调接口,一个是在 log instance id 推进的临界区内的回调 synced_value_done,另一个是异步的回调 value_chosen,分别适用于和 log instance id 强相关的状态控制(例如成员管理,后面会提到),以及普通的状态机。异步的回调是在临界区之外的,占用事件驱动线程,但不会影响 Paxos 算法总体吞吐量,同时也有个同步队列 CstateMachineBase 保证日志应用的顺序性。
成员变更
至此我们实现了大部分对分布式一致性库的需求,但还有个常见的重要需求:在实用化的分布式一致性库中实现动态成员管理。实现这个功能主要有以下几种方式:
- 停机,手动变更配置文件
- RAFT 的实现 joint consensus
joint consensus (two-phase approach)
- Log entries are replicated to all servers in both configurations.
- Any server from either configuration may serve as leader.
- Agreement (for elections and entry commitment) requires separate majorities from both the old and new configurations.
- 一步成员变更,将成员管理问题转换为 Paxos 处理的一致性问题(本库使用的方法)
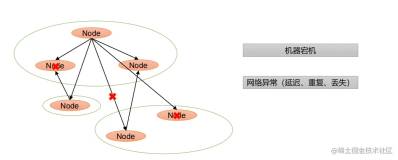
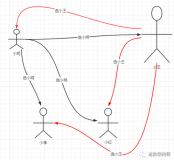
之所以 RAFT 不采用一步变更,是因为一步变更会在中间状态中出现不交叉的多组 quorum,如下面样例中的场景,需要将C节点替换为D节点,在 log instance id 3上,由于延迟等原因,A和C节点还没有进行成员变更,还认为成员是ABC,AC作为 quorum 进而 accept 了一个 value,而对于知道最新成员为ABC的BD两个节点,仍可以作为 quorum 去 accept 另外一个值,这就导致了 Paxos 算法失效。

这个问题的本质在于,在进行共识算法时,成员不是原子的变化的,而是在各个节点间存在中间状态的。将成员变更操作引入log中,并通过状态机在各个节点重放,通过多版本成员控制对不同 log instance id 的情况使用正确的成员组,即可解决这个问题。此时成员变更被整合到 Paxos 算法中,并成为一个原子的变更出现。

不难发现,在通信和成员管理接口中也传递了 group id(多 Paxos Group)和 log instance id 的参数(通信接口在 message 中获取),便于在实现的时候兼容动态成员变更的管理。
class Ccommunication {
public:
virtual int send(const node_id_t &target_id, const message_t &message) = 0;
enum broadcast_range_e {
broadcast_voter = 0,
broadcast_follower,
broadcast_all,
};
enum broadcast_type_e {
broadcast_self_first = 0,
broadcast_self_last,
broadcast_no_self,
};
virtual int broadcast(const message_t &message, broadcast_range_e range, broadcast_type_e type) = 0;
};
class CpeerManager {
public:
virtual bool is_voter(const group_id_t &group_id, const instance_id_t &instance_id,
const node_id_t &node_id) = 0;
virtual bool is_all_peer(const group_id_t &group_id, const instance_id_t &instance_id,
const std::set<node_id_t> &node_set) = 0;
virtual bool is_all_voter(const group_id_t &group_id, const instance_id_t &instance_id,
const std::set<node_id_t> &node_set) = 0;
virtual bool is_quorum(const group_id_t &group_id, const instance_id_t &instance_id,
const std::set<node_id_t> &node_set) = 0;
};总结
至此一个完整的、模块化的 Paxos 库已经实现了,可以完成大部分我们期望的能力,也具备极大的扩展能力。当然在实现这个库的时候,也存在取舍,本库仅实现了一个 Paxos Group,只能串行依次确定一个值,这是为了具备快速抢主的能力,舍弃了 pipeline 的能力(pipeline快速抢占的空洞对状态机实现很不友好)。当然为了实现 pipeline 可以通过多 GROUP 实现,效率也不会有太大差别。更多的优化比如存储的日志和状态机的混合持久化、消息的 GROUPING(BATCHING) 等都可以在提供的接口上随意发挥。
这里提供几个扩展代码样例作为参考,包括
- 基于 RocksDB 的存储 rocks_storage.h
- 基于 ASIO 的 TCP & UDP 通信 asio_network.h
- 基于 状态机+MVCC 的动态成员管理 dynamic_peer_manager.h