
1 Hbase简介
1.1 初识Hbase
Hbase全拼为Hadoop database即分布式存储数据库,是一个可以进行随机访问的存储和检索数据的平台,用于存储结构化和半结构化的数据,如果数据量不是非常庞大的情况下,Hbase甚至可以存储非结构化的数据。Hbase作为Apache基金会Hadoop项目的一部分,使用Java语言实现,将HDFS作为底层文件存储系统,在此基础上运行MapReduce分布式批量处理数据,为Hadoop提供海量的数据管理服务。
Hbase是典型的NoSQL数据库,通常被描述为稀疏的、分布式的、持久化的,由行键、列键和时间戳进行索引的多维有序映射数据库,主要用来储存结构化和半结构化的数据。Hbase是Google的Bigtable的开源实现。
1.2 Hbase的特性
🌈容量巨大
🌈列存储
🌈稀疏性
传统的关型数据库中,每一行的数据类型都是事先定义好的,会占用固定的内存空间,在此情况下NULL值也会占用一定的存储空间。而在Hbase中的数据都是以字符串形式存储,数据为空的情况下列并不占用存储空间,因为会有部分数据有真实值,部分数据为NULL,故称为稀疏性。
🌈扩展性强
Hbase构建在HDFS之上,理所当然的支持分布式表,也继承了HDFS的可扩展性。Hbase是横向扩展的,所谓的横向扩展是指在扩展时不需要提过服务器本身的性能,只需要添加不同的服务器节点到现有的集群即可。Hbase根据Region的大小进行分区,分别存在集群中的不同节点,当添加新节点时,集群自动重新调整,在新的节点启动Hbase服务器,实现动态扩展。Hbase的扩展是热扩展,即在不停掉现有服务的情况下进行服务节点的增加和删除。
🌈高可靠性
Hbase同时继承了HDFS的高可靠性,HDFS的多副本机制可以让它在出现故障时自动恢复,同时Hbase内部也提供了预写日志(Write-Ahead-Log,WAL)和Replication机制。
2 HDFS专项模块
HDFS即Hadoop Distributed File System(Hadoop分布式文件系统),HDFS是参考Google公司的GFS实现的,不管是HDFS还是GFS计算机节点都会很容易出现硬件故障,HDFS的数据分块储存在不同节点,当某个节点出现故障时,HDFS相关组件会快速检测出节点故障并提供容错机制完成数据的自动恢复。
2.1 HDFS的基本架构
三个组件:NameNode、DataNode、SecondaryNameNode
一个架构:主从架构(Master/Slave模式)
HDFS集群一般由一个NameNode(运行在Master节点)、一个SecondaryNameNode(运行在Master节点)和许多个DataNode(运行在Salve节点)组成。在HDFS中数据是被分块进行储存,一个文件可以被分为许多个块,每个块被存储在不同的DataNode上。

2.1.1 HDFS各组件的功能:
🌈NameNode
将文件的元数据信息存储在edits和fsimage文件中(元数据信息记录了文件系统中的文件名和目录名,以及它们之间的层级关系,同时也记录了每个文件目录的所有者以及权限,甚至还记录了每个文件是由哪些块组成)
接收客户端的请求并提供元数据(当客户端请求读取文件时,会先从NameNode获取文件的元数据信息,然后再往元数据中对应的DataNode读取数据块)
通过心跳机制检测DataNode的状态,当出现节点故障时,重新分配失败的任务。
🌈SecondaryNameNode
定期合并edits和fsimage文件
edits文件(编辑日志)用来记录文件的增、删、改操作信息。
fsimage文件(镜像文件)用来维护HDFS的文件和文件夹的元数据信息。
每次系统启动时,NameNode会读取fsimage文件的信息并保存到内从中。在HDFS运行期间,新的操作日志不会立即与fsimage文件进行合并,也不会存到NameNode内存中,而是先写到edits文件中,当edits文件达到一定的阈值或者间隔一定时间(默认为3600s或者达到64MB)后会触发SecondaryNameNode工作,这个时间点被称为checkpoint。具体的合并步骤如下:
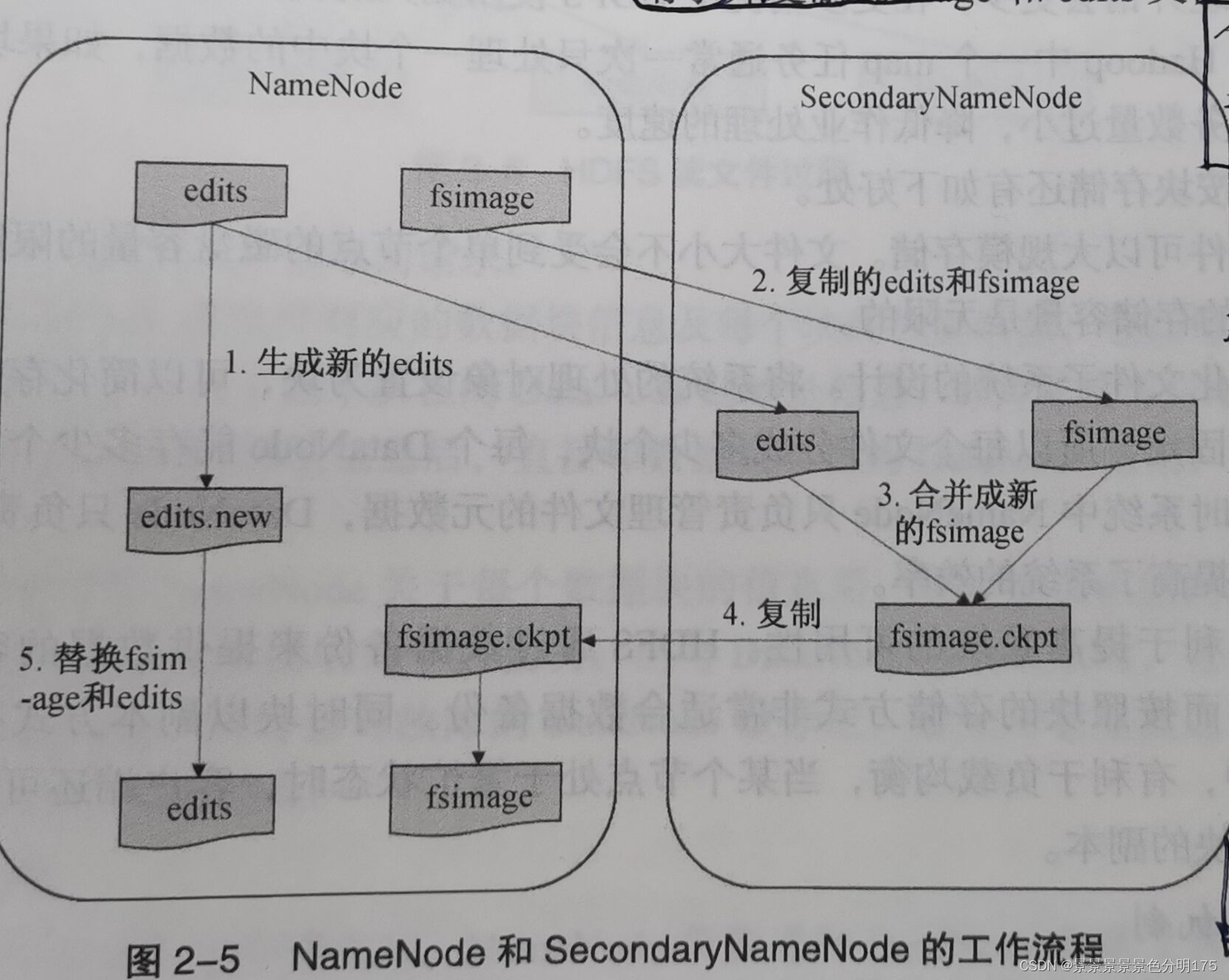
(停用和新记录)在合并之前SecondaryNameNode通知NameNode停用当前editlog文件,并将新的操作日志写入到新的editlog.new文件。
(请求并复制)SecondaryNameNode从NameNode请求并复制fsimage和edits文件。
(合并)SecondaryNameNode把fsimage和edits文件合并,并重命名为fsimage.ckpt。
(两次替换)NameNode从SecondaryNameNode获取fsimage.ckpt文件,并替换掉fsimage文件,同时用edits.new文件替换旧的edits文件。
(更新)更新checkpoint的时间。自此,fsimage文件中保存的是上一个checkpoint的元数据信息,而edits文件保存的是从上一个checkpoint开始的操作日志。
🌈DataNode
存储数据块
为客户端提供数据块的读写服务
相应NameNode的相关指令(数据块的增、删、改等操作)
定时发送心跳信息给NameNode
2.2 HFDFS多种机制
2.2.1 分块机制
在HDFS中数据是被分块进行储存,一个文件可以被分为许多个块,每个块被存储在不同的DataNode上。HDFS数据块大小默认为64MB,而一般磁盘块的大小为512B。
2.2.2 副本机制
HDFS中数据块的副本数默认为3个,当然也可以设置更多的副本集。在默认副本集为3的情况下,0.17版本之前,会把第一个副本放在一个机架的一个DataNode上,第二个副本放在这个机架的另一个DataNode上,而第三个副本会放在不同的机架上;0.17版本之后,会把第一个副本放在一个机架的一个DataNode上,第二个副本放在另一个机架的DataNode上,而第三个副本会放在第二个副本的同机架的不同DataNode上。(机架的概念参照上图2-4)
2.2.3 容错机制
NameNode出错:从SecondaryNameNode备份的fsimage文件进行恢复。
DataNode出错:当出现节点故障时,重新分配失败的任务。
数据出错:数据写入的同时保存总和校验码,读取数据时进行校验。
2.2.4 读写机制
🌈读文件
(发送请求)客户端向NameNode发送读文件请求
(得到地址)NameNode返回文件的元数据(文件对应的数据块信息及各数据块位置及其副本位置)信息
(读取数据)客户端按照元数据信息与DataNode进行通信,并读取数据块。
🌈写文件
(暂写数据)先将数据写入本地的临时文件
(发送请求)等临时文件大小达到系统设置的块大小时,开始向NameNode发送写文件请求
(获取地址)NameNode检查集群中每个DataNode的状态信息,获取空闲节点并检查客户端的权限符合后再创建文件,然后返回数据块及其对应DataNode的地址列表给客户端,列表中包括副本的存放地址。
(写数据并发送确认信息)客户端将临时文件的数据块写入列表的第一个DataNode,同时第一个DataNode以副本的形式传送至第二个DataNode,第二个DataNode以副本的形式传送至第三个DataNode。每一个DataNode在接收到数据后都会向前一个节点发送确认信息,数据传输完成后,第一个DataNode会向客户端发送确认信息。
(错误处理)客户端收到确认信息表示数据块已经永久化的存储在所有的DataNode中,此时客户端会向NameNode发送确认信息。一旦上一步的任何一个DataNode存储失败未发送确认信息,客户端就会告知NameNode,将数据备份到新的DataNode中。

