MR <--- 读取 HBase的数据 MR ---> 写入 HBase(使用场景:数据迁移) HBase -> MR -> HBase 读取和写入(使用场景:索引表的建立)
1.MR与HBase集成所需要的jar包
bin/hbase mapredcp
2.运行环境
export HADOOP_HOME=/opt/modules/hadoop export HBASE_HOME=/opt/modules/hbase HADOOP_CLASSPATH=`${HBASE_HOME}/bin/hbase classpath` \ ${HADOOP_HOME}/bin/hadoop jar ${HBASE_HOME}/lib/hbase-server-1.2.0-cdh5.9.3.jar
3.编写MR程序
执行流程:将stu写入到stuMR表中
stu -> mr -> stuMR
package com.kfk.hbase; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.conf.Configured; import org.apache.hadoop.hbase.Cell; import org.apache.hadoop.hbase.CellUtil; import org.apache.hadoop.hbase.HBaseConfiguration; import org.apache.hadoop.hbase.client.Put; import org.apache.hadoop.hbase.client.Result; import org.apache.hadoop.hbase.client.Scan; import org.apache.hadoop.hbase.io.ImmutableBytesWritable; import org.apache.hadoop.hbase.mapreduce.TableMapReduceUtil; import org.apache.hadoop.hbase.mapreduce.TableMapper; import org.apache.hadoop.hbase.mapreduce.TableReducer; import org.apache.hadoop.hbase.util.Bytes; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.util.Tool; import org.apache.hadoop.util.ToolRunner; import java.io.IOException; /** * @author : 蔡政洁 * @email :caizhengjie888@icloud.com * @date : 2020/11/10 * @time : 7:07 下午 * * 需求分析,从数据表stu读取info到新表stuMR */ public class HBaseMR extends Configured implements Tool { /** * map * 一.Mapper class extends TableMapper<KEYOUT输出的Key的类型, VALUEOUT输出的Value的类型> * 原版的Mapper程序是有输入的KV类型,和输出的KV类型四个参数,源码:extends Mapper<ImmutableBytesWritable, * Result, KEYOUT, VALUEOUT> * Put类型为hbase中定义的类型,便于作为Reducer的输入类型,根据reducer输入类型可知 */ public static class MyMapper extends TableMapper<Text, Put> { private Text mapOutputKey = new Text(); public void map(ImmutableBytesWritable rowkey, Result value, Context context) throws InterruptedException, IOException { // set outputRowKey mapOutputKey.set(Bytes.toString(rowkey.get())); // 通过rowKey创建put对象 Put put = new Put(rowkey.get()); // 迭代以获取cell数据 for (Cell cell:value.rawCells()){ // 实际业务中不一定会是全表输出,可以选择性输出 if ("info".equals(Bytes.toString(CellUtil.cloneFamily(cell)))){ if ("username".equals(Bytes.toString(CellUtil.cloneQualifier(cell)))){ put.add(cell); } else if ("age".equals(Bytes.toString(CellUtil.cloneQualifier(cell)))){ put.add(cell); } } } context.write(mapOutputKey,put); } } /** * reduce * 二.Reducer calss extends TableReducer<KEYIN, VALUEIN, KEYOUT> * 输出key 类型为ImmutableBytesWritable 实现writeableComparable的字节数组 * 输出 value 类型为 Mutation 是 delete put increment append 的父类 */ public static class MyReducer extends TableReducer<Text, Put, ImmutableBytesWritable> { public void reduce(Text key, Iterable<Put> values, Context context) throws IOException, InterruptedException { // 从得到的put中得到数据 for (Put put:values){ // 往外写数据 context.write(null,put); } } } /** * run * @param args * @return * @throws IOException * @throws ClassNotFoundException * @throws InterruptedException */ public int run(String[] args) throws IOException, ClassNotFoundException, InterruptedException { // 1) get conf Configuration configuration = this.getConf(); // 2) create job Job job = Job.getInstance(configuration,this.getClass().getSimpleName()); job.setJarByClass(this.getClass()); Scan scan = new Scan(); scan.setCaching(500); scan.setCacheBlocks(false); // set input and set mapper TableMapReduceUtil.initTableMapperJob( "stu", // input table scan, // Scan instance to control CF and attribute selection MyMapper.class, // mapper class Text.class, // mapper output key Put.class, // mapper output value job); // set reducer and output TableMapReduceUtil.initTableReducerJob( "stuMR", // output table MyReducer.class, // reducer class job); // 4) commit,执行job boolean isSuccess = job.waitForCompletion(true); // 如果正常执行返回0,否则返回1 return (isSuccess) ? 0 : 1; } public static void main(String[] args) { Configuration configuration = HBaseConfiguration.create(); try { // 调用run方法 int status = ToolRunner.run(configuration,new HBaseMR(),args); // 退出程序 System.exit(status); } catch (IOException e) { e.printStackTrace(); } catch (ClassNotFoundException e) { e.printStackTrace(); } catch (InterruptedException e) { e.printStackTrace(); } catch (Exception e) { e.printStackTrace(); } } }
在本地运行的时候需要将core-site.xml文件的HDFS部分屏蔽掉
<configuration> <!-- <property>--> <!-- <name>fs.defaultFS</name>--> <!-- <value>hdfs://bigdata-pro-m01:9000</value>--> <!-- </property>--> <property> <name>hadoop.http.staticuser.user</name> <value>caizhengjie</value> </property> </configuration>
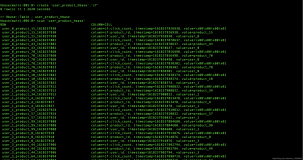
原数据:
hbase(main):003:0> scan 'stu' ROW COLUMN+CELL 001 column=info:addres, timestamp=1604928754019, value=guangzhou 001 column=info:age, timestamp=1604928702206, value=20 001 column=info:username, timestamp=1604928590845, value=alex 002 column=info:age, timestamp=1604955412618, value=30 002 column=info:username, timestamp=1604955441414, value=ben 003 column=info:addres, timestamp=1604997979803, value=beijing 003 column=info:age, timestamp=1604997979803, value=32 003 column=info:username, timestamp=1604997979803, value=jack 3 row(s) in 0.0360 seconds
运行结果:
hbase(main):002:0> scan 'stuMR' ROW COLUMN+CELL 001 column=info:age, timestamp=1604928702206, value=20 001 column=info:username, timestamp=1604928590845, value=alex 002 column=info:age, timestamp=1604955412618, value=30 002 column=info:username, timestamp=1604955441414, value=ben 003 column=info:age, timestamp=1604997979803, value=32 003 column=info:username, timestamp=1604997979803, value=jack 3 row(s) in 0.1780 seconds
4.打包发布运行命令:
export HADOOP_HOME=/opt/modules/hadoop export HBASE_HOME=/opt/modules/hbase HADOOP_CLASSPATH=`${HBASE_HOME}/bin/hbase classpath` \ ${HADOOP_HOME}/bin/hadoop jar /opt/jars/hbasemr.jar
由于我本地maven加载的是hbase-1.2.0版本,集群用的是hbase-1.2.0-cdh5.9.3版本,所以在运行jar包的时候会出现版本冲突:
Exception in thread "main" java.lang.NoSuchMethodError: org.apache.hadoop.hbase.client.Scan.setCaching(I)Lorg/apache/hadoop/hbase/client/Scan; at com.kfk.hbase.HBaseMR.run(HBaseMR.java:105) at org.apache.hadoop.util.ToolRunner.run(ToolRunner.java:70) at com.kfk.hbase.HBaseMR.main(HBaseMR.java:136) at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62) at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) at java.lang.reflect.Method.invoke(Method.java:498) at org.apache.hadoop.util.RunJar.run(RunJar.java:221) at org.apache.hadoop.util.RunJar.main(RunJar.java:136)
我的解决方案是将hbase-client-1.2.0.jar移到hbase/lib目录下,将hbase-client-1.2.0-cdh5.9.3.jar改名,或者maven直接加载hbase的cdh版本,和集群的一致。