
十、图解: master的选举、容错以及数据的恢复。#
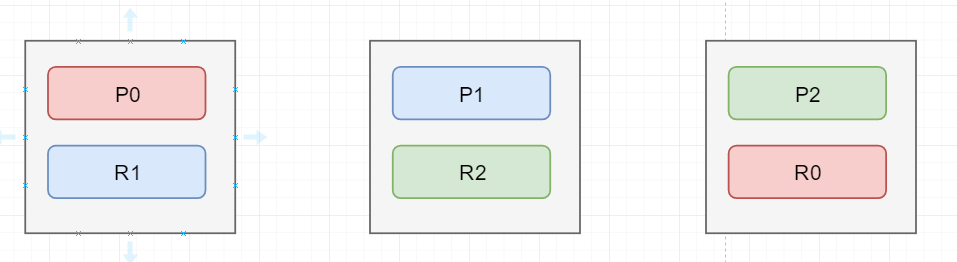
如上图为初始状态图
假如图上的第一个节点是master节点,并且它挂掉了。那它挂掉后,整个cluster的status会变成red,表示存在数据丢失了集群不可用。然后集群会按照下面的步骤恢复:
第一步:完成master的选举,自动在剩下的节点中选出一个节点当成master节点。
第二步:选出master节点后,这个新的master节点会将P0在第三个节点中存在一个replica shard提升为primary shard,此时cluster 的 status = yellow,表示集群中的数据是可以被访问的但是存在部分replica shard不可用。
第三步:重新启动因为故障宕机的node,并且将右边两个节点中的数据拷贝到第一个节点中,进行数据的恢复。
十一、ES如何解决并发冲突#
ES内部的多线程异步并发修改时,通过_version版本号进行并发控制,每次创建一个document,它的_version内部版本号都是1,以后对这个doc的修改,删除都会使这个版本号增1。
ES的内部需在Primary shard 和 replica shard之间同步数据,这就意味着多个修改请求其实是乱序的不一定按照先后顺序执行。
相关语法:
PUT /index/type/2?version=1{ "name":"XXX" }
上面的命令中URL中的存在?version=1,此时,如果存在其他客户端将id=2的这条记录修改过,导致id=2的版本号不等于1了,那么这条PUT语句将会失败并有相应的错误提示。这样也就规避了并发修改异常。
拓展:
ES也允许你使用自己的维护的版本号来进行并发控制,用法如下:
PUT /index/type/2?version=1&version_type=external
对比两者的不同:
- 使用es提供的_version进行版本控制的话,需要你的PUT命令中提供的version == es的维护的version。
- 添加参数
version_type=external之后,假设当前ES中维护的doc版本号是1, 那么只有当用户提供的版本号大于1时,PUT才会成功。
十二、路由原理#
什么是数据路由?
一个index被分成了多个shard,文档被随机的存在某一个分片 上。客户端一个请求随机打向index中的一个分片,但是请求的doc可能不存在于这个分片上,于是接受请求的shard会将请求路由到真正存储数据的shard上,这个过程叫做数据路由。
其中接受到客户端请求的节点称为coordinate node(协调节点),比如现在是客户端想修改服务端的一条消息,shard A接受到请求了,那么A就是 coordnate node协调节点。数据存储在B primary shard 上,那么协调节点就会将请求路由到B primary shard中,B处理完成后再向 B replica shard同步数据,数据同步完成后,B primary shard响应 coordinate node, 最后协调节点响应客户端结果。
假如说你每个primary shard有多个存活的replica shard,默认情况下coordinate node会将请求使用round-robin的方式分散到replica shard和这个primary shard上(因为它们的数据是一样的)
就像下图这样:
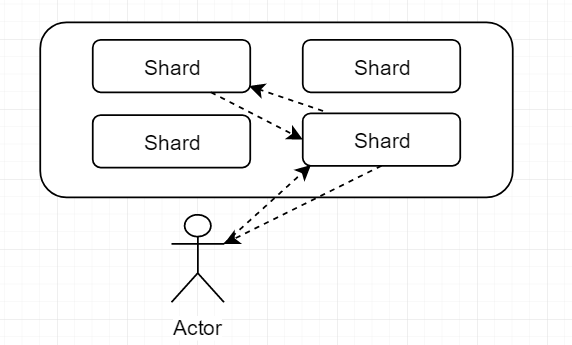
路由算法,揭开primary_shard数量不可变的面纱
shard = hash(routing) % number_of_primary_shards
公式不复杂,可以将上面的routing当成doc的id。无论是用户执行的还是自动生成的,反正肯定是唯一的。既然是唯一的,那每次hash得到的结果也是一样的, 这样一个唯一的值对主分片的数进行取余数,得到的结果就会在 0~最大分片数 之间。
你看看上面的路由公式中后半部分使用的是 number_of_primary_shards ,这也是为什么ES规定,primary shard的数量不能改变,但是replica shard 可以改变的原因。
除了上面说的路由方式,你还可以像下面这样定制路由规则:比如PUT /index/type/id?routing=user_id ,可以保证这类doc一定被路由到指定的shard上,而且后续进行应用级负载均衡时会批量提升读取的性能。
像下面这种用法,可以保证你的doc一定被路由到一个shard上,
# 添加一个doc,并制定routing PUT my_index/_doc/1?routing=user1&refresh=true { "title": "This is a document" } # 通过id+routing获取你想要的doc GET my_index/_doc/1?routing=user1
十三、写一致性及原理#
我们在发送任何一个增删改查时,都可以带上一个 consistency 参数,指明我们想要的写一致性是什么,如下
PUT /index/type/id?consistency=quorum
有哪些可选参数呢?
- one:当我们进行写操作时,只要存在一个primary_shard=active 就能写入成功。
- all:cluster中全部shard都为active时,可以写入成功。
- quorum(法定的):也是ES的默认值, 要求大部分的replica_shard存活时系统才可用。
quorum数量的计算公式: int((primary+number_of_replicas)/2)+1
算一算,假如我们的集群中存在三个node,replica=1,那么cluster中就存在3+3*1=6个shard。
int((3+1)/2)+1 = 3
看计算的结果,只有当quorum=3 即replica_shard=3时,集群才是可用的。
但是当我们的单机部署时,由于ES不允许同一个server的primary_shard和replica_shard共存,也就是说我们的replica数目为0,为什么ES依然可以用呢?这是因为ES提供了一种特殊的处理场景,也就是当number_of_replicas>1时,上述检查集群是否可用的机制才会生效。
quorum不全时 集群进入wait()状态。 默认1分钟。在等待期间,期望活跃的shard的数量可以增加,到最后都没有满足这个数量的话就会timeout。
我们在写入时也可以使用timeout参数, 比如: PUT /index/type/id?timeout=30通过自己设置超时时间来缩短超时时间默认的超时时间。

