关于GC的扩展知识
本章主要是对上一篇文章讲的垃圾回收机制的扩展,垃圾回收其实本身是有很多可以优化的点的,本章就进行对这些优化点进行介绍。
1.GC Roots遍历提升效率
以往做法
当垃圾回收器线程进行GC时,
第一步需要找到GC Roots;
第二步通过GC Roots进行遍历堆中引用GC Roots的对象形成引用链;
第三步,将不在引用链中的对象标记进行标记(需要回收的对象),或者标记引用链中的对象(需要复制,整理的对象),具体标记哪种对象根据堆中的分代内存不同和采用的垃圾回收算法来确定。
可优化地方以及优化原理
上述过程第二步中遍历堆中引用GC Roots的对象,这部分随着堆内存的越来越大需要的时间也会逐步增长。如果能够提前知道堆中哪部分内存是引用,来判断是否引用GC Roots这样效率是不是会更高一些。
没错,因为之前讲过从Exact VM开始就已经采用了准确式内存管理即知道哪部分内存是引用;而且在即时编译的过程中我也会知道栈中或者寄存器里哪部分内存是引用。这个时候我用一个数据结构来存储这些信息,在第二步中就不需要遍历整个堆了,只需要遍历没有标识引用内存的地方(也就是刚才数据结构中没有存储的信息)。
在HotSpot中使用OopMap这个数据结构来存储这信息,也就是可以显著提高GC Roots遍历的效率,但是在什么位置放这些信息呢?
2.提升了GC Roots遍历效率却不知道怎么安插?
前面提到过通过一个OopMap数据结构能够提升遍历效率,但是OopMap中的数据在不同的地方内容是不一样的(比如每个方法里面我的局部变量表里面的内容可能是不一样的),所以我为每个指令附近都放一个OopMap。
等等,这样未免也太浪费内存了吧~。
没错,所以我们得先办法把它放到合适的地方!嗯没错,我想想:这个数据结构的出现是为了优化GC第二步的效率出现的,也就是说只有GC时在放这些数据就行了~。思路找到了,但是什么时候发生GC呢?发生GC这个时间我不能确定,但是我可以确定的是它遍历堆中内存的时候必须要进行STW【否则如果在标记的过程中堆中引用发生变化就会导致标记结果出错】(2.1中讲解),我指定只有代码中执行执行到某个地方才可以进行STW这样我就可以间接的实现我的目的。
也就是说当GC发生时,只有执行到某个地方才会进行STW,然后我在这个地方附近放上这么一个OopMap的数据结构,然后加快第二步的效率。
这个某个地方其实名字叫做“safePoint”,顾名思义安全点,只有代码执行到安全点附近才可以进行STW垃圾收集,而只要将OopMap安插到安全点附近就行。
2.1为什么需要STW?
上面提到过:
【否则如果在标记的过程中堆中引用发生变化就会导致标记结果出错】
一,三色标记法
接下来用三色标记法进行解释如果没有STW会发生什么情况:
一,先解释三色标记法: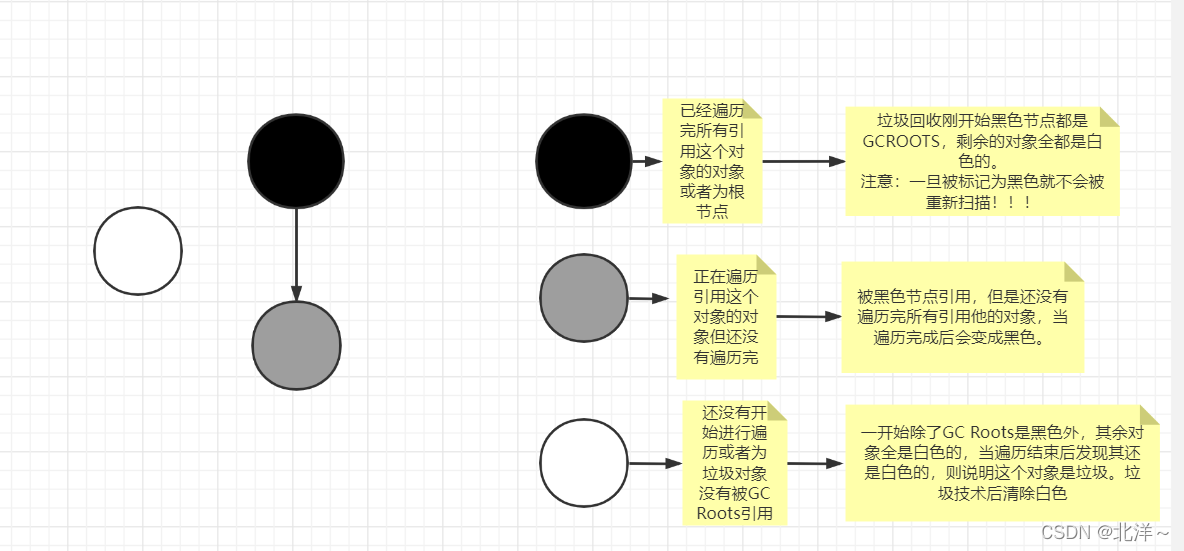
二,没有STW出现的情况
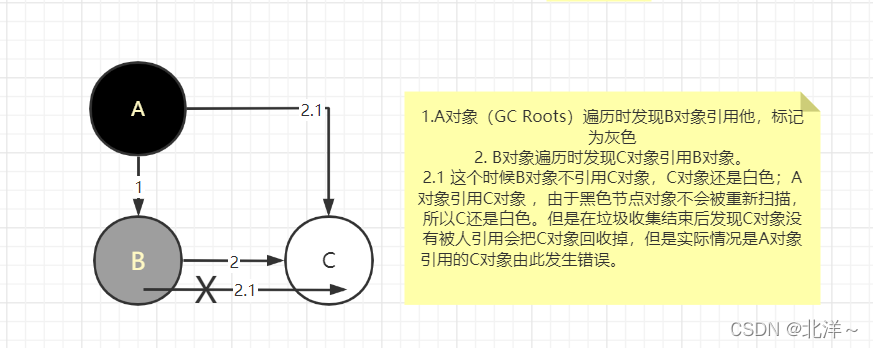
三,解决方案
上面那种异常情况必须同时满足两个条件:
1.灰色对象不引用白色对象
2.黑色读写引用白色对象
因此,只要让其中一个条件不满足即可,因此出现了两种解决方案:
1.增量更新:
这种方案是让第二个条件不满足,即当黑色对象引用白色对象时,将这个黑色对象保存下来,等扫描结束后,再次取出黑色对象进行扫描,可以简单理解为如果黑色对象引用了百世对象就会被标记为灰色。
2.原始快照:
当灰色对象删除白色对象的引用时,将这个灰色对象记录下来,等到扫描结束后,在对这些灰色对象为根进行扫描,简单理解为:不管是否删除与否都会按照第一次刚开始的引用关系图进行扫描。
CMS垃圾回收器采用增量更新来进行并发标记,G1,Shenandoah采用原始快照
3.safePoint我又该放到哪里?
safePoint上面解释过了,但是我该在哪里放置safePoint呢?放的多了会导致GC收集过于频繁增加运行时内存压力,放的少了又会因为堆中不断增加使用的内存而没有及时回收堆里面内存导致垃圾收集器等待时间过长。
这样,我定义一个规则,只有这种==“会让程序长时间运行的指令”==特征我才会进行安插safePoint,但是这个特征“长时间”并没有具体的定义,但是却有“指令序列复用”这样的含义。比如方法调用,循环跳转,异常跳转这些,只有这些指令附近才会安插safePoint。
循环还有一项优化措施,认为循环次数较少的话,执行时间应该也不会太长,所以使用int类型或范围更小的数据类型作为索引值的循环默认是不会被放置安全点的。这种循环被称为可数循环(Counted Loop),相对应地,使用long或者范围更大的数据类型作为索引值的循环就被称为不可数循环(Uncounted Loop),将会被放置安全点。通常情况下这个优化措施是可行的,但循环执行的时间不单单是由其次数决定,如果循环体单次执行就特别慢,那即使是可数循环也可能会耗费很多的时间。
safePoint位置选好了,但是上个问题说过执行到safePoint中需要进行STW,发生GC时,我该如何快速跑到safePoint附近进行STW?还有我这个STW该怎么实现呢?
4.如何实现STW?
首先解释为什么叫做STW,全称“Stop the Word”,因为通过GC Roots遍历堆中内存的过程其内存里面的引用关系不能发生变化,所以需要暂停所有的用户线程操作来保障Gc Roots形成的引用链是正确的即待会标记过程不会出错。
让所有线程都暂停,这个“看起来复杂其实并不简单”的操作其实有两种方式处理:
一,抢先式中断:
垃圾收集器收集时,系统将所有用户线程都中断。当发现不在safePoint附近的线程时先让他恢复运行直至跑到safePoint附近。这种方式现在几乎没有虚拟机采用这种方式来响应GC。
二,主动式中断:
我不直接对我的用户线程操作,当发生GC时,我给用户线程设立个标志位,用户线程执行的时候不断轮询这个标志位,如果轮询到了那么我将自己中断我自己的运行,由于这种方式是轮询到就立马进行挂起所以将轮询的地方和safePoint的地方重合。
优化
“不断轮询标志位”这句话听起来就很耗时哈哈,那么再虚拟机中是怎么优化的呢?还有轮询之后的操作我自己挂起我自己这个又是怎么实现的?
等等,我不放到下一个问题里面讲了,直接一遍过:
轮询标志位这个操作其实就是一条汇编指令,(对于汇编和JAVA是什么关系,之前也有讲到过,辛苦翻阅前面文章~)
这条汇编指令的意思就是当我轮询到需要中断线程的标志位的时候:我会将其中一个内存页设置为不可读,这会导致产生一个自陷异常信号,异常处理器中接受到后进行主动中断操作。
5.一个"小Bug":线程如果不执行呢?
上面说到过现在虚拟机采用的几乎都是主动式中断来中断线程,而其实现又是通过线程执行过程中不断轮询标志位产生自陷异常信号在异常处理表中进行中断线程,
大家有没有发现有个小bug:如果我轮询的操作一直得不到执行呢?这个时候我又该如何让虚拟机进入垃圾回收状态。
其实不一定都需要进行中断线程来保证,回想下STW是为什么:因为如果这个时候用户线程还在执行的话内存中的引用关系可能会发生变化,所以才需要进行STW。如果一个线程没有得到CPU时间片执行(java中的线程对应于操作系统的线程,对应关系也可以找笔者之前的关于SignCatcher对线程的理解进行查阅),但是我可以确保其中一部分代码区域是不会改变内存引用关系的,这样也可以不用管这些线程。
引入Safe Region(安全区域)解决
“安全区域:这部分代码不会使内存中的引用关系发生变化”,因此只要进入了安全区域,虚拟机就不会管这些线程。当线程离开安全区域后,如果这个时候引用链还没有形成(也就是通过GC Roots遍历堆内存)那么是不能离开的,一直等待直至引用链形成(或者完成了垃圾回收器需要暂停用户线程的阶段)收到信号为止。
6. GC Roots会随着运行时间变长而增加吗?
基础知识介绍
根据堆中的不同区域(分代设计)和回收内存空间来判定分为不同的GC名称:
局部回收:Minor GC,MajorGC,…
整个内存回收:Full GC
如果存在“跨代引用”(最典型的比如老年代对象引用年轻代对象),比如发生Minor GC时,只遍历普通的GC Roots对象其实结果并不准确(某些对象虽然本身不属于GC Roots但是随着经历的GC次数变多成为老年代对象),如果这个时候将这个引用的年轻代对象标记为垃圾清除后,老年代中的对象就会有问题,所以引用链形成的过程中还需要遍历整个老年代来保证结果准确。
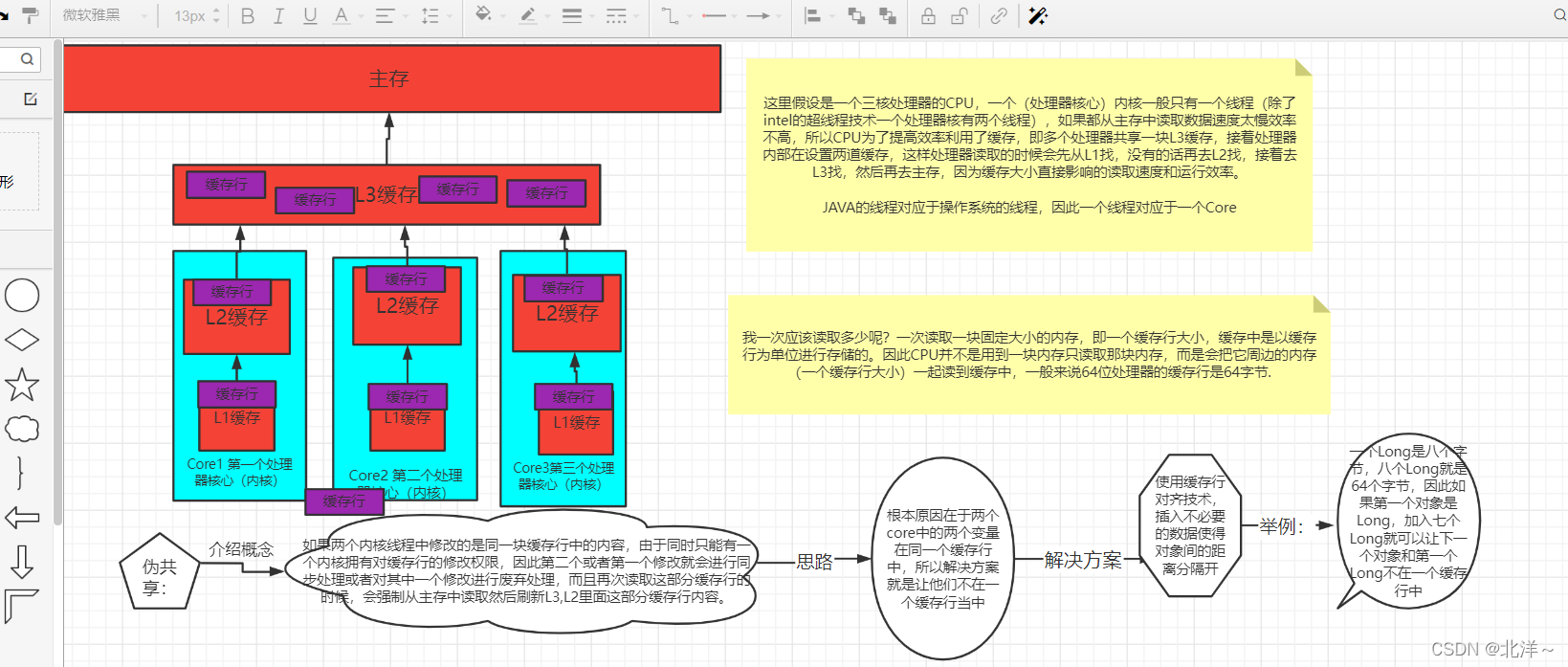
CPU的缓存行技术及伪共享解决方案
!
记忆集
跨域可以理解为跨内存访问或者访问其他分代里面的内存
上面遍历整个老年代这个过程听起来就很耗时哈哈,事实也确实如此。那么我们可以引入这么一个概念:
如果你引用了其他内存里面的对象那么我把你存放到其他内存里面的一个数据结构里面,之后其他内存回收的时候只需要把之前添加到数据结构里面的对象加入到GC Roots中即可。
我们优化一下:
每个不同的分代中都存着一个数组,这个数组中对堆内存进行一个映射,
我数组中的每一小块对应的元素是分代中固定大小的内存(比如我第一个数组下标表示我引用的是0到100,第二个数组下标表示引用的是100-200以此类推)。当我第一个数组下标对应内存跨域引用了其他分代中的内存,我将把第一个数组下标对应的内存的元素值标识为1代表脏(Dirty),没有则为0。当垃圾回收时,我就知道哪部分内存是跨代引用并将他们加入到GC Roots进行扫描(将数组中元素为1对应的内存对象加入GC Roots中)。
根据我映射的内存大小精度又可以进行细分:
1.字长精度:只记录一个机器字长(处理器的寻址位数)该字包含跨代指针
2.对象精度:记录一个对象(对象字段中含有跨代指针)
3.卡精度:记录一块内存区域(该区域有对象包含跨代指针)
最常用的精度
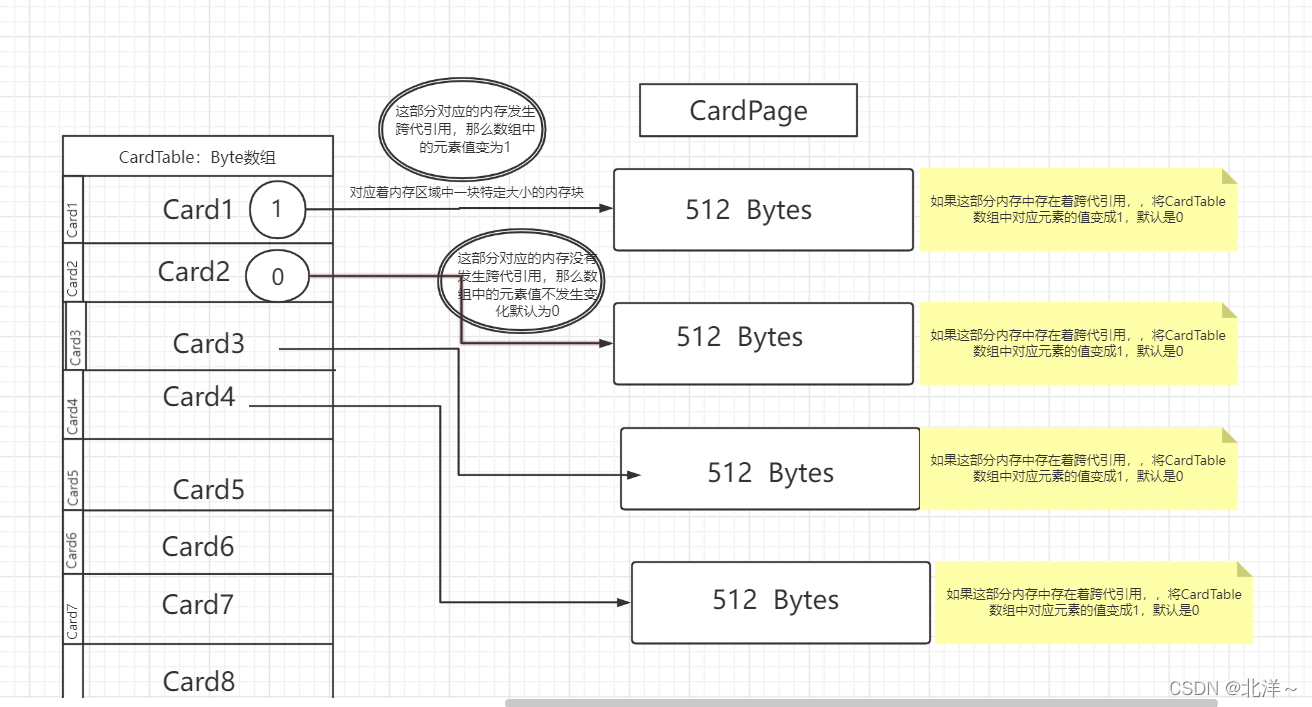
采用“卡精度”的记忆集是通过“卡表”这个数据结构来实现的。
使用精度为卡,这个记忆集的实现方式也被称为卡表,卡表中其实是字节数组结构,每个数组中的元素都对应一部分指定大小内存块,这部分内存被称作卡页,当卡页中的内存块中引用了其他的内存块中的一个或多个对象,就会将卡页中的元素值变为一。变为一的就是脏数据,收集时讲这部分内存加入到gc roots中。
也就是这样的:
可能出现的问题
一,何时进行更新卡表?
先看我这张图哈哈,字不好看,但是大致意思是差不多的。
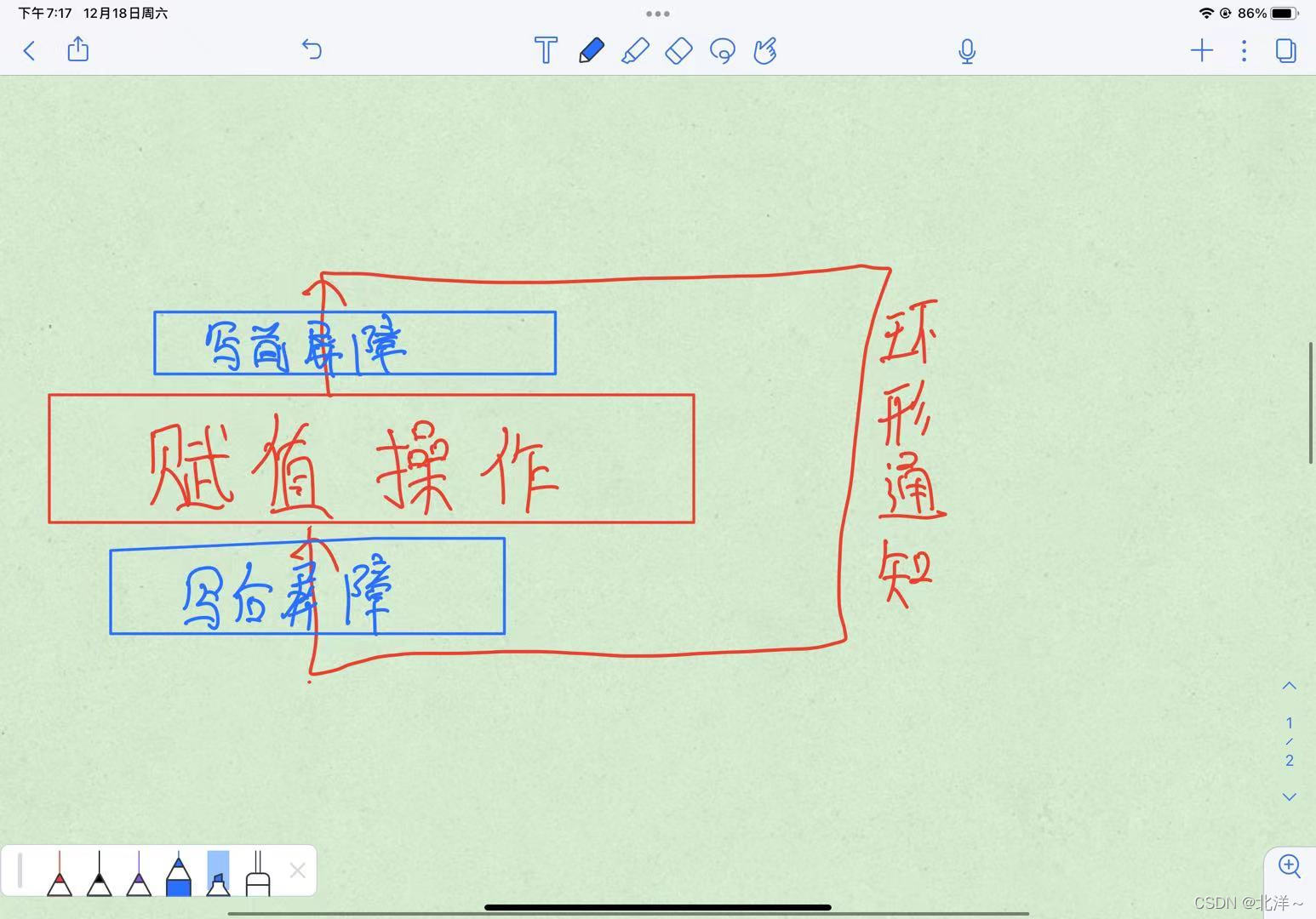
我在写后屏障中进行更新卡表就可以保证我的卡表记录是正确的。
二,“伪共享引起的问题”
上面刚刚讲过CPU的缓存行技术,简单来说就是如果两个线程中两个独立的变量在同一块缓存行中,那么不管是哪个线程修改,另外一个线程都需要重新从主存中读取,而设置缓存行就是为了加快读取效率,所以这样势必会降低效率。
想想刚刚我们记忆集处理方式,如果卡页对应的内存中发生跨代引用,那么就会对卡表进行更新;上面说的“伪共享”也会在这里出现而且影响性能,比如:一个缓存行六十四个字节;一个卡表中的一个元素是一个字节,每个元素对应的一个卡页存储的是512字节,也就是一个卡表中64个元素在一个缓存行,而这64个元素对应的总卡页内存为32KB(64 X 512字节),如果两个线程中的变量分配到了这部分内存中,之后变量发生跨代引用更新卡表元素时就会导致另一个线程的缓存行失效而从主存中去拿。所以应该减少更新卡表这个操作,如果已经更新过脏数据了就不需要进行更新卡表了。


