3.pandas读取文件
3.1read_excel()
3.1.1准备数据
import pandas as pd
id = ['xx1', 'xx2', 'xx3', 'xx4', 'xx5']
df = pd.DataFrame({
'name': ['aaa', 'bbb', 'ccc', 'ddd', 'eee'],
'age': [18, 20, 21, 22, 19],
'gender': ['male', 'female', 'male', 'female', 'female'],
'class': ['A', 'B', 'B', 'A', 'A']
}, index=id)
# 保存为excel文件
df.to_excel('data.xlsx')
3.1.2默认方式读取
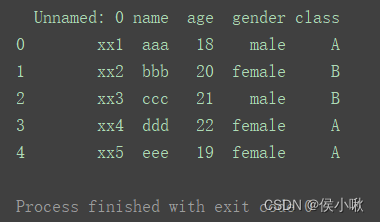
read_excel()读取excel文件得到的DataFrame,
- index值默认为0,1,2,3…
- 列名默认为excel中的第一行数据
df = pd.read_excel('data.xlsx')
print(df)
3.1.3设置index_col参数
df1 = pd.read_excel('data.xlsx', index_col=0)
print(df1)
如图,通过index_col=0,将下标为0的列作为索引进行读取。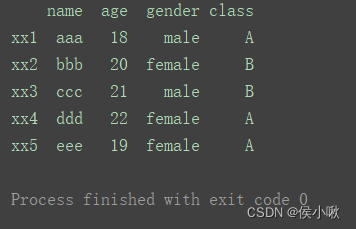
3.1.4设置header参数
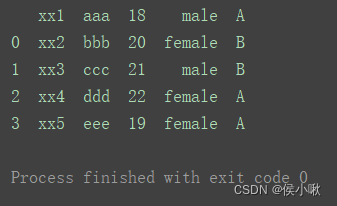
header可以设置列名,默认为0表示首行即列名,
- 如图通过 header=1,将下标为1行作为了列名(第二行)
df2 = pd.read_excel('data.xlsx', header=1) # 设置第1行为列索引
print(df2)
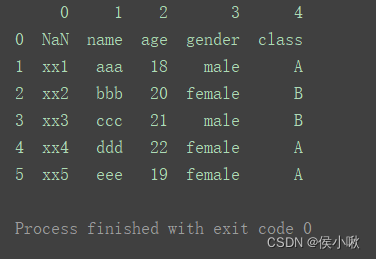
- 当header参数为None时,表示列名为数字0,1,2,3…
df3 = pd.read_excel('data.xlsx', header=None)
print(df3)
3.1.5设置usecols参数
通过usecols参数,传入列位置或标签列表,可以导出指定列
- 传入一个位置
df1 = pd.read_excel('data.xlsx', usecols=[1]) # 通过指定列索引号导入第1列
print(df1)

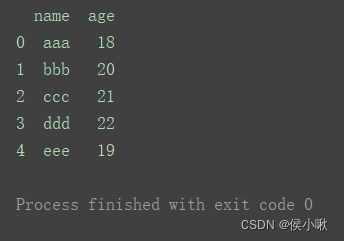
- 传入多个位置
df2 = pd.read_excel('data.xlsx', usecols=[1, 3])
print(df2)
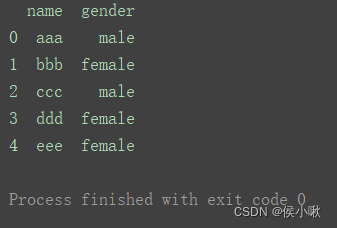
- 传入多个标签
df3 = pd.read_excel('data.xlsx', usecols=['name', 'age'])
print(df3)
3.1.6设置sheet_name参数以指定工作簿
可以通过read_excel()的sheet_name参数传入工作簿名称。
如:
import pandas as pd
df = pd.read_excel('data_name.xlsx', sheet_name='sheetA')
df1 = df.head() # 输出前5条数据
3.1.7解决数据输出时列名不对齐的问题
使用命令
pd.set_option(‘display.unicode.east_asian_width’, True)
import pandas as pd
pd.set_option('display.unicode.east_asian_width', True)
df = pd.read_excel('data.xlsx')
3.2read_csv()
3.2.1设置encoding参数
设置encoding参数可以指定编码方式,默认为None。
出现乱码的时候可以使用。
import pandas as pd
df = pd.read_csv('data.csv', encoding='gbk') # 导入csv文件,并指定编码格式
print(df.head())
3.2.2设置sep参数指定分隔符
sep默认为",",表示分隔符默认为逗号。
根据数据的具体情形,设置不同的分隔符,下例中读取了分隔符为\t的txt文本文件。
import pandas as pd
df1 = pd.read_csv('1月.txt', sep='\t', encoding='gbk')
df1 = df1.head()
3.3read_html()小案例
3.3.1pd.read_html()方法
使用pandas的read_html()方法,只需要传入url,可以获取到相应的网页源码中的表格数据,返回的数据格式为一个列表。
3.3.2DataFrame的append()方法
此外可以对DataFrame对象使用append方法将满足一定格式(形似一个表格)的列表数据添加到其中,ignore_index=True可以忽略掉该list对象中数据的索引列,而将索引设为默认的0,1,2…,避免了多个list对象的索引重复的问题。以该案例为例:
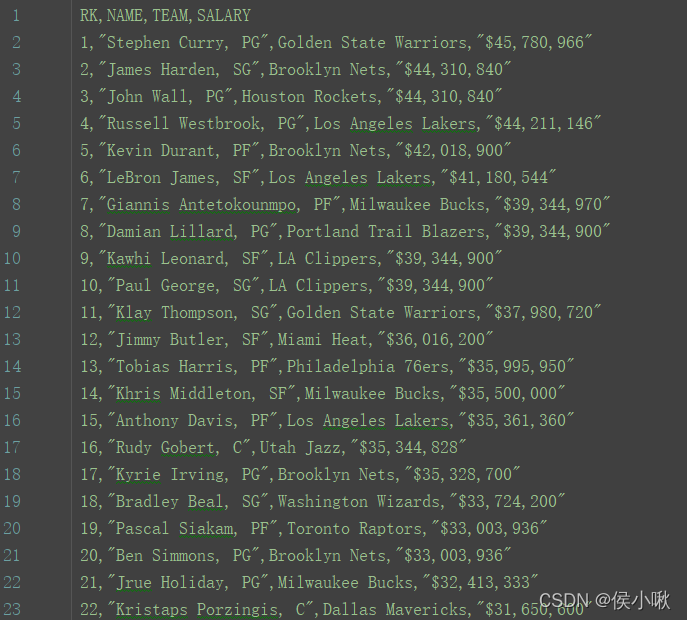
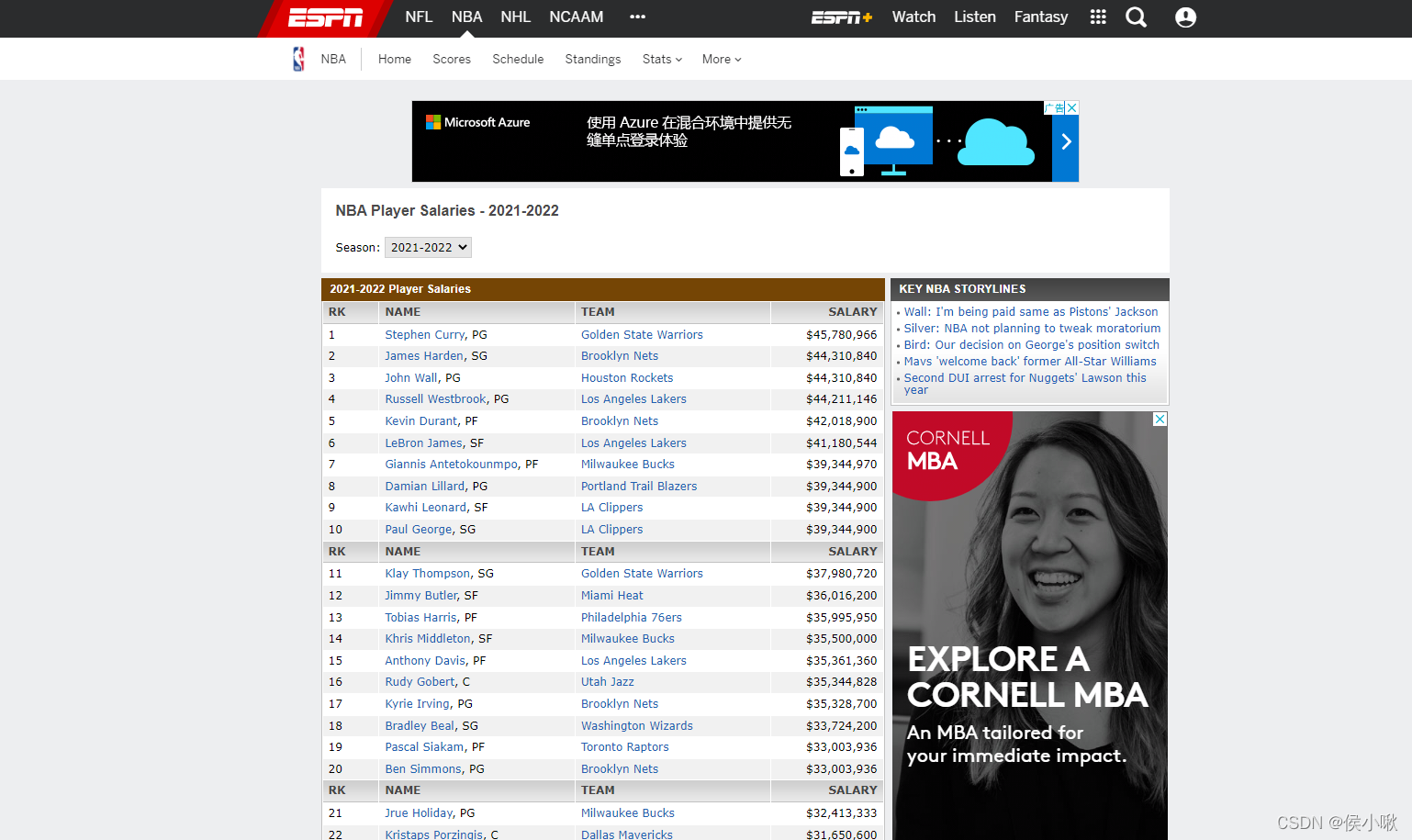
以网站http://www.espn.com/nba/salaries/_/seasontype/4等为例,获取此网站及其他11页的表格数据,并保存为csv文件。
3.3.3pd.to_csv()方法
- header 表头,传入形式为一个列表,默认为数据第一行
- index=False 忽略索引
import pandas as pd
df = pd.DataFrame()
url_list = ['http://www.espn.com/nba/salaries/_/seasontype/4']
for i in range(2, 13):
url = 'http://www.espn.com/nba/salaries/_/page/%s/seasontype/4' % i
url_list.append(url)
# 遍历网页中的table读取网页表格数据
for url in url_list:
df = df.append(pd.read_html(url), ignore_index=True)
# 通过观察,df中第三个数据都是以$开头的,除了重复出现的标题数据。以以$开头为筛选条件,去除冗余数据。
df = df[[x.startswith('$') for x in df[3]]]
df.to_csv('NBA.csv', header=['RK', 'NAME', 'TEAM', 'SALARY'], index=False)