正文:
本篇内容将通过五个部分来介绍云原生离线实时一体化数仓建设与实践。
一、离线实时一体化数仓建设难点
二、离线实时一体化数仓技术演化
三、阿里巴巴离线实时一体化数仓建设实践
四、离线实时一体化数仓参考架构
五、未来实时数仓核心趋势展望

一、离线实时一体化数仓建设难点
随着时代的发展,数据分析由通过实时大屏洞察业务变化,逐步转向数据决策和数据在线转化。实时数据的精细化运营,让每个人对数据需求,出现了指数级增长。另一方面,数据在线推荐,风控系统也严重依赖于实时数据,数据分析的力度和强度有着显著地提升。
面对蓬勃发展的数据需求,我们的数据架构也变得越来越复杂。无论是订单数据,还是行为数据,它们都通过消息中间件采集,然后经过多条加工链路。一份数据经过离线,实时,在线之后,会产生多份数据集。这套架构让运维成本,开发成本变得很高。
整个架构高成本的背后是因为有多套组件和多套存储。而多套存储带来了多份数据孤岛,导致数据的一致性无法保障。每个系统都有自己的运维方式,开发方式和使用方式。从而增加了运维成本和学习成本。
当我们回顾计算机行业的发展。在60年代,每个程序员在开发系统时,都需要自己通过离散文件,网络文件或层级文件存储状态。在80年代,大家可以通过描述的方式分析数据。到了大数据时代,数据的存储方式多种多样,同样一份数据在各个引擎里有不同的选型。虽然不同的技术在可扩展性,并行能力,吞吐能力上有所不同。但至今为止,我们分析问题的方式并发生没有本质变化。所以我相信随着数据技术的进步,数据存储还会有一个融合的过程。
我认为数仓平台的时效性有两个概念,即实时和准时。其中,只有机器做决策的场景需要实时。比如端到端数据产生和延迟,大屏风控,计算延迟,事件驱动等等。而人类做决策的时间,一般以分钟/小时/天/月为准,极度新鲜的数据并不影响人类决策的本质。只有改变决策结果的系统,才是优秀的实时系统。比如海量数据的灵活分析,自助分析等等。
大家有的时候为了数据的时效性,往往会忽视数据的质量。如果一个数仓平台只追求时效性,我们只能看到一个结果值。不但很难发现数据的质量问题,二修正成本也很高。所以一个优秀的实时数仓平台,其数据一定要可检查,可修正。
数仓平台实时化的第三个需求就是降低成本。这里主要分为开发成本,运维成本和人力成本。其中,最核心的是开发成本。我们不但要让业务与技术解耦,实现数据资产复用,业务自助开发。还要简化链路,减少依赖和传递。在运维方面,组件不但要具备很好的弹性能力,还要有托管服务,从而降低运维成本。在人力成本方面,我们要降低技术门槛和学习成本。
综上所述,一个优秀的实时数仓需要具备四个能力。第一,支持实时写入、实时事件计算、实时分析,并且满足实时和准时的需求、第二,将实时和离线融合。减少数据冗余和移动,具有简化数据,修正数据的能力。第三,实现业务与技术解耦。支持自助式分析和敏捷分析。第四,拥抱标准,拥抱生态,拥抱云原生。降低运维成本、迁移成本,SQL优先。
二、离线实时一体化数仓技术演化
接下来,我们看看离线实时一体化数仓的发展。如上图所示,阿里巴巴的第一代实时数仓,主要面向特定业务,做烟囱式开发。我们用典型的Lambda架构,实行采集,加工,服务的三步走策略。根据特定业务,进行烟囱化的建设。以任务为单位支撑应用场景,当数据预处理之后,存储到OLAP和KV引擎。但随着业务场景越来越复杂,运维开发成本越来越高。烟囱式的开发方式,已经不能适应业务变化。
于是我们有了第二代实时数仓,面向指标复用,进行数仓开发。我们引入了OLAP引擎,将小数据量明细存储在MPP数据库,支持OLAP Query。然后在DWD层,按照主题将数据源整合,构建可复用的DWS层,减少建设的烟囱化。与此同时,不同的任务和引擎中,仍沉淀了烟囱化的业务逻辑。由于不同业务的SLA不同,KV引擎和OLAP根据SLA,拆分了多个实例,导致数据运维成本和开发成本增加。与此同时,KV Schema Free的元数据管理也尤为困难。
为了解决上述问题,我们研发了第三代实时数仓,即面向统一数据服务的一站式开发。在第三代实时数仓中,我们将公共明细层和汇总层,应用明细层和汇总层,集中存储,统一管理。其次,我们将OLAP、KeyValue统一为SQL接口。然后,简化实时链路和加工链路,让数据可修正,减少外部系统的依赖。通过一站式开发,我们不但实现了数据的秒级响应,让全链路状态可见,而且整个架构的组件更少,依赖更少。有效降低了运维成本和人工成本。
三、阿里巴巴离线实时一体化数仓建设实践
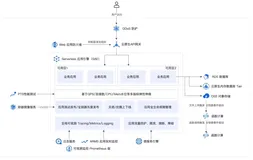
接下来,我们讲一讲阿里巴巴离线实时一体化数仓建设的实践。2020年阿里巴巴双十一大屏,峰值处理消息40亿条/秒,全天处理150万亿条,GMV 3秒以内,全天延迟1~2秒。这些数据主要来自两个渠道。第一,结构化的订单数据。第二,用户点击时,产生的点击流数据。数据收集汇总之后,一部分数据进入实时加工链路,进入Flink。另一部分数据以归档的方式,进入离线数仓。离线系统以MaxCompute为主,在线系统以Hologres为主。
因为MaxComput是一项大数据计算服务。它能提供灵活快速、完全托管、高性能、低成本、安全的PB级数据仓库解决方案。所以当数据集成之后,数据进入Date Works平台,通过MaxComput,对数据进行深度分析,报表分析。MaxComput不但简单易用,拥有极致的弹性能力,而且拥有企业级的安全能力,充分保障企业的数据安全。
上图是阿里云的重要组件DateWorks。DateWorks由很多组件组成,其中包括数据治理,数据开发,数据调度,元数据管理等模块。DateWorks集成了阿里云不同的引擎,提供了优秀的元数据管理能力和企业及治理能力。
我通常将存储分为三类。第一类Transaction在线的事务系统。适合模型简单的分析场景,以TP模型解决AP的问题。第二类Analytics系统,这个系统的往往采用分布式,列存,索引。通各种压缩技巧,把海量数据分析做到极致。第三类是Serving系统,这类系统能毫秒级的响应,每秒支持上万的qps,以只读为主,更新简单。
HSAP以数仓模型解决了数据服务的问题。HSAP主要应用在数据报告,数据看版,在线应用。能够统一数据存储,统一进行数据服务。除此之外,HSAP支持离线数据的批量导入,实时数据的实时更新。
上图是一站式实时数仓的演进。无论是交互式分析,联邦查询,还是在线的高性能点查都可以减少数据的传递和依赖。数据离线加工的部分,我们继续使用MaxCompute。数据实时加工的部分使用Flink。避免数据割裂,赋能数据服务,简化运维管理。
阿里云的Hologres为分析服务一体化,设计的实时数仓。在云原生方面,与MaxCompute底层打通,透明加速,实时离线一体。在流批一体的存储方面,高吞吐数据写入,支持更新,写入即可见。在性能方面,随着CPU的多核化,我们对向量化、全异步等执行引擎优化,充分利用计算资源。
我们在阿里客户体验系统CCO的实时数仓改造中,对交易、咨询、退款等数据整合,解决了风险运营、智能排班、售前转询、现场调度等需求。做到了架构简化可靠,无数据孤岛,支持联邦查询,全流程秒级延迟。不但减少了数据同步,避免了数据延迟和数据库抖动。而且满足了双11流量10倍的增长需求。
上图反映的是,阿里客户体验系统CCO过去三年,实时加工任务的发展。连续三年,成本100%的增长,导致运维压力大,成本消耗大。经过研究CCO的技术架构,我们发现实时任务有烟囱化的遗留问题。首先,KV引擎与OLAP引擎不通,没有统一的存储。其次,公共层任务链路过长,不同实例间的数据同步,作业发生了膨胀,导致维护成本越来越高。
为了解决以上问题,我们用了Hologres技术机构,与Flink和DataWorks数据地图集成。实现了高性能写入,让元数据集成DataWorks数据地图。构建了高可靠的场景HA,实现了行列混存和资源隔离。
通过DataHub+Flink+Hologres+MaxCompute的技术架构,CCO的整体硬件资源成本下降30%,实时写入支持行存千万/秒,列存几十万/秒写入要求。在2020双11当天,查询latency平均142ms,99.99%的查询在200ms以内。除此之外,还能够支撑200+实时数据大屏搭建,为近300+小二提供稳定的数据查询服务。
四、离线实时一体化数仓参考架构
云原生的实时数仓主要分为加工层的和存储层。加工层以Flink加工为主。存储层有Hologres系统。数据的处理方式只要有三种。第一,即席查询方式;第二,准实时方式;第三,增量方式。通过这三种方式,满足了绝大多数场景的处理需求。
实时数仓的数据分析,主要应用在可视化大屏、Web应用API、BI报表系统、实时数据接口服务等等。首先,将业务系统的结构化数据,采集到实时数据缓存平台。初步分类之后,增量数据进DataHub;明细全量数据进Hologres。然后进行数据集成,Flink加工增量数据,实时更新明细数据。
然后离线任务加工结果表,由MaxCompute导入,在CDM/ADS层表为实际物理表,任务由DataWorks统一调度。最后,前端实时请求,数据实时性依赖,全部由DataWorks调度周期配置。
增量数据的实时统计,只要通过增量流,增量流join静态维,增量流join增量流,这3种场景,就能统计出数据。然后通过Flink计算、datahub进行数据存储。而ADS层的应用数据存储在Hologres。逻辑简单,实时性强。
该怎么选择MaxCompute和Hologres?这两个技术的技术原理是完全不同。MaxCompute有典型的做数据加工场景,计算过程是异步的,资源按需分配。扩展性几乎不受限制,接口标准是MC SQL。Hologres的所有任务都是同步的,复杂查询尽量避免跨多节点数据shuffle,基于Pangu,利用SSD做缓存加速,成本相对高。接口标准是PostgreSQL。
数仓开发应逐步实现减少层次,不断复用的目标。减少数据层次,敏捷适应需求变化,弱化ADS、面向DWS、DWD的应用开发。MaxCompute与Hologres底层互通,互读互写,无需外部同步工具,数据传递效率比其他软件高10倍以上。
数据开发不是一蹴而就,一定要分阶段进行。大家一定要在不同阶段,使用不同的加工方式。第一阶段,一定以获取数据为主。短平快地支撑,理解业务和数据。
第二阶段,要满足在线快速业务上线。丰富公共层明细数据,确定产品框架。
到第三阶段的成熟层时,才开始规划不同的组织架构。整个系统趋于稳定,需求成体系。与业务密切合作常态化。公共汇总层开始沉淀。
五、未来实时数仓核心趋势展望
我觉得在未来,实时数仓的核心趋势是一站式的数据平台,敏捷化的数据开发,在线化的数据服务。
一站式的实时数仓,一个系统能同时解决,OLAP分析与线上服务两个问题。一定要满足业务敏捷响应,数据自助分析,避免数据孤岛,赋能数据服务,简化运维管理。
数据服务仅是内部系统,而且要成为外部的在线系统。不但能支撑数据决策,而且要提效在线转化。最终实现数据平台的高可用,高并发。数据的低延时/低抖动,安全可靠。
最后,数据开发敏捷化。在未来,希望通过技术创新,通过空云原生的弹性能力,减少人类的瓶颈。以公共层对外提供服务,将查询灵活度从数仓工程师转移到业务分析师,让卓越计算力解决人力瓶颈。
阿里云大数据是为业务敏捷而生的简单、易用、全托管的云原生大数据服务。激活数据生产力,分析产生业务价值。详情访问:https://www.aliyun.com/product/bigdata/apsarabigdata