scala总结
一、简介
java中main方法: public static void main(String[] args){...}
- scala中没有static关键字
- class: 里面的所有的属性与方法都是非static的
- object: 里面的所有的属性和方法都是类似java static修饰的。
object WordCount {
val name:String = "zhangsan"
/**
* scala中没有public修饰符,默认就是public效果
* def: defined的缩写,def标识方法
* main: 方法名
* Array[String]: Array代表是数组,[]是泛型使用,[]里面的类型代表当前Array中转载的元素类型
* Unit: 相当于java 的void
*
* scala中如果一行只写一个语句,那么;可以省略
* 如果一行写多个语句,;用来分割这多个语句
*/
def main(args: Array[String]): Unit = {
//java语法
System.out.println("wordcount")
//scala
println("wordcount")
println(WordCount.name)
}
}第 1 章 Scala变量和数据类型
1.java注释:
- 单行注释: //
多行注释: /.../
文档注释: /*../
scala的注释与java完全一样
*/
2.定义变量
/**
* java中变量定义: 类型 变量名 = 值
*
*
*
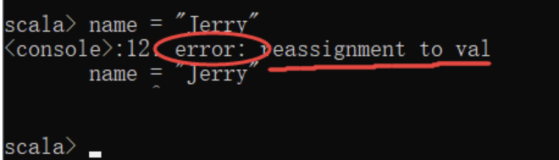
* scala中变量定义语法: val/var 变量名:变量类型 = 值
* val与var的区别:
* val定义的变量不可以被重新赋值
* var定义的变量可以被重新赋值
* scala在定义变量的时候,变量类型是可以省略,省略之后scala会自动推断数据类型
*
* scala定义变量的时候必须初始化
* @param args
*/
def main(args: Array[String]): Unit = {
val name:String = "zhangsan"
//val定义的变量不可以被重新赋值
//name = "lisi"
var age:Int = 100
age = 200
println(name)
println(age)
val address = "shenzhen"
println(address)
}
}3.控制台输入
/**
* scala中读取控制台输入的数据: StdIn
*
* 读取文件内容: Source.fromFile(path,"utf-8")
*/
def main(args: Array[String]): Unit = {
val str = StdIn.readLine("请输入一句话")
println(str)
println(Source.fromFile("d:/data.txt", "utf-8").getLines().toBuffer)
}4.数据类型
/**
* java数据类型:
* 1、基本数据类型
* byte、short、char、int、long、float、double、boolean
* 2、引用数据类型
* String、class、集合、数组
*
* scala数据类型:
* Any: 是所有类的父类
* AnyVal: 值类型
* Byte、Short、Char、Int、Long、Float、Double、Boolean
* Unit: 相当于java的void, 有一个实例()
* StringOps: 对java String的扩展
* AnyRef: 引用类型
* String、scala class、java class、scala集合、java集合,..
* Null: 是所有引用类型的子类, 有一个实例null[null一般是给引用类型赋初始值使用,在定义变量的时候如果使用null赋初始值,此时变量的类型必须定义]
*
* Nothing: 所有类型的子类,但是不是给程序员使用,是scala内部使用
*
* @param args
*/
def main(args: Array[String]): Unit = {
/**
* String str = null
* str = "zhangsan"
*
* class Person
*
* class Student extends Person
*
* Student s = new Student
*
* s = new Person
*/
var s:String = null
s = "zhangsan"
println(s)
//val a:Int = null
//println(a)
}5.获取字符串
/**
* java中如何得到一个字符串:
* 1、通过""包裹
* 2、new String(..)
* 3、通过一些方法
* 4、字符串拼接【+】
* scala中得到一个字符串:
* 1、通过""包裹
* 2、字符串拼接[插值表达式] s"${变量名/表达式}"
* 3、new String(..)
* 4、通过""" """包裹[能够保留字符串的输入的格式]
* 5、通过一些方法
* @param args
*/
def main(args: Array[String]): Unit = {
//1、通过""包裹
val name = "ZHANGSAN"
val address = "shenzhen"
val str = name + address
//2、字符串拼接
val str2= s"${name}-${address}"
println(str2)
val str3 = s"1+1=${1+1}"
println(str3)
val str5 = new String("hello")
println(str5)
//3、通过三引号包裹
val sql =
"""
|create table student(
| id string,
| name string,
| age string)COLUMN_ENCODED_BYTES=0
""".stripMargin
println(sql)
//三引号与插值表达式结合使用
val tableName = "student"
val sql2 =
s"""
|create table ${tableName}(
| id string,
| name string,
| age string)COLUMN_ENCODED_BYTES=0
""".stripMargin
println(sql2)
println(str2.substring(2))
val str6 = "hello %s".format("lisi")
println("http://www.xx.com/aa/bb?ip=%s".format("192.168.1.102"))
println("http://www.xx.com/aa/bb?ip=%d".format(10))
println(str6)
}6 .类型的转换
/**
* 数字和数字的转换
* 1、低精度向高精度转换: Int->Long
* java中: 自动转换
* scala中: 自动转换
* 2、高精度转低精度: Long->Int
* java中: 强转
* scala: toXXX方法
* 数字和字符串的转换
* 1、数字转字符串
* java: 字符串拼接
* scala: 字符串拼接\toString
* 2、字符串转数字
* java: Integer.ValueOf(字符串),..
* scala: toXXX方法
*/
def main(args: Array[String]): Unit = {
//低精度向高精度转换
val a:Int = 10
val b:Long = a
//高精度转低精度
val c:Long = 100
val d:Int = c.toInt
println(d)
//数字转字符串
val s:String = c.toString
val s1:String = s"${c}"
println(s)
println(s1)
//字符串转数字
val s2 = "10"
val e:Int = s2.toInt
println(e)
//字符串中.不一定是小数点
val s3 = "10.0"
//val f:Int = s3.toInt
//println(f)
val g:Double = s3.toDouble
println(g)
}第 2 章 Scala中运算符和流程控制
1.运算符
/**
* java中运算符:
* 1、算数运算符: +、-、*、/、% ++ --
* 2、比较运算符: > < >= <= != ==
* 3、逻辑运算符: && || !
* 4、赋值运算符: = += -= *= /=
* 5、位运算符: < > & | >>
* 6、三元运算符: 逻辑表达式? 表达式1: 表达式2
*
* scala中没有三元运算符,如果想要实现三元运算符可以通过if-else做
* scala没有++、--运算符。
* scala中运算符:
* 1、算数运算符: +、-、*、/、%
* 2、比较运算符: > < >= <= != ==
* 3、逻辑运算符: && || !
* 4、赋值运算符: = += -= *= /=
* 5、位运算符: < > & | >>
*
* scala中运算符都是方法。
*/
def main(args: Array[String]): Unit = {
val a = 10
val c = a + 20
val d = a.+(20)
println(d)
}2.块表达式
/**
* 块表达式: 由{ }包裹的一块代码称之为块表达式
* 块表达式有返回值,返回值是{ }中最后一个表达式的结果值
* 后续大家看到{ }就可以认为是块表达式[ for循环、while循环的大括号不能看做块表达式]
*
*/
def main(args: Array[String]): Unit = {
val b = {
println("hello....")
val c = 10+10
//return "xx"
}
println(b)
println("----------------------")
10
//return "xx"
}3.条件表达式
/**
* java中条件表达式的用法:
* 1、单分支: if
* 2、双分支: if-else
* 3、多分支: if-else if -..-else
*
* scala中条件表达式的用法:
* 1、单分支: if
* 2、双分支: if-else
* 3、多分支: if-else if -..-else
* scala的条件表达式有返回值,返回值是符合条件的分支的{ }的最后一个表达式的结果值
*/
def main(args: Array[String]): Unit = {
val a =10
//单分支
if(a%2==0){
println("a是偶数")
}
//双分支
if(a%3==0){
println("a是3的倍数")
}else{
println("a不是3的倍数")
}
//多分支
if(a%3==0){
println("a是3的倍数")
}else if(a%4==0){
println("a是4的倍数")
}else{
println("其他...")
}
//if表达式有返回值
val b = if(a%2==0){
println("..............")
a*a
}
println(b)
val c = if(a%10==0){
if(a%5==0){
println("5.。。。。。。。。")
a*a
}else{
println("+++++++++++++")
a+10
}
}
println(c)
}
4.for循环
/**
* java的for循环:
* 1、基本for: for(int i=0;i<=100;i++)
* 2、增强for: for(类型 变量: 集合/数组)
*
* scala中重要的两个方法:
* to:
* 用法: startIndex.to(endIndex)
* 结果: 会生成一个左右闭合的集合
* until:
* 用法: startIndex.until(endIndex)
* 结果: 会生成一个左闭右开的集合
* scala中方法调用有两种方式:
* 1、对象.方法名(参数值,..)
* 2、对象 方法名 (参数值,..) [如果方法只有一个参数,此时()可以省略]
* scala for循环语法: for(变量 <- 数组/集合/表达式) { 循环体 }
* for循环的守卫: for(变量 <- 数组/集合/表达式 if(布尔表达式)) { 循环体 }
* 步长: for(变量 <- start to end by step) { 循环体 }
* 嵌套for循环: for(变量 <- 数组/集合/表达式;变量 <- 数组/集合/表达式;...) { 循环体 }
* 变量嵌入: for(变量 <- 数组/集合/表达式; 变量2 = 值 ;变量 <- 1 to 变量2;...)
* for默认是没有返回值的,如果想要for有返回值需要用yield表达式: for(变量 <- 数组/集合/表达式) yield { 循环体 }
*
* @param args
*/
def main(args: Array[String]): Unit = {
//基本用法
for( i <- 1 to 10){
println(s"i=${i}")
}
println("+"*100)
//步长
for( j<- (1 to 10).by(2) ){
println(s"j=${j}")
}
println("-"*100)
for( j<- 1 to 10 by 2 ){
println(s"j=${j}")
}
println("*"*100)
for(k<- 1 to 10){
if(k%2==0){
println(s"k=${k}")
}
}
println("*"*100)
//守卫
for(k<- 1 to 10 if(k%2==0)) {
println(s"k=${k}")
}
/**
* for(k<- 1 to 10){
* println(s"k=${k}")
* if(k%2==0){
* println(s"k=${k}")
* }
* }
* 此循环不能通过守卫简化,因为if语句之前还有其他的语句
*/
println("*"*100)
for(i<- 1 to 10){
for(j<- i to 10){
println(s"i+j=${i+j}")
}
}
//通过scala嵌套for循环简化上面循环
println("*"*100)
for(i<- 1 to 10; j<- i to 10){
println(s"i+j=${i+j}")
}
/* for(i<- 1 to 10){
println(s"i=${i}")
for(j<- i to 10){
println(s"i+j=${i+j}")
}
}
不能使用scala嵌套for循环简化
*/
for(i<- 1 to 10 ){
if(i%2==0){
for(j<- i to 10){
println(s"i+j=${i+j}")
}
}
}
for(i<- 1 to 10 if (i%2==0); j<- i to 10 ){
println(s"i+j=${i+j}")
}
println("*"*100)
for(i<- 1 to 10){
val k = i * i
for(j<- 1 to k){
println(s"i+j=${i+j}")
}
}
println("*"*100)
//变量嵌入简化
for(i<- 1 to 10; k= i*i;j<- 1 to k){
println(s"i+j=${i+j}")
}
//yield表达式
val result = for(i<- 1 to 10) yield {
i * i
}
println(result.toBuffer)
println("------------------")
1 to 10 foreach(println(_))
}
5.while和do-while
/**
- scala中while、do-while的用法与java一样
- while与do-while的区别:
- while 先判断在执行
- do-while 先执行在判断
- @param args
*/
def main(args: Array[String]): Unit = {
var i = 11
while ( i<=10 ){
println(s"i=${i}")
i=i+1
}
println("*"*30)
var j =11
do{
println(s"j=${j}")
j = j+1
}while(j<=10)
}
6.循环控制break
/**
* java中使用break与continue控制循环
* break: 结束整个循环
* continue: 结束本次循环立即开始下一次循环
*
* scala中没有break与continue
* 实现break:
* 1、导入包:
* 2、使用breakable以及break方法
* @param args
*/
def main(args: Array[String]): Unit = {
//break
var i=0
/*while (i<=10){
if(i==5){
throw new Exception("......")
}else{
println(s"i=${i}")
i=i+1
}
}*/
//scala封装的break实现
breakable({
while (i<=10){
if(i==5) break()
println(s"i=${i}")
i=i+1
}
})
//continue
var j=0
/* while (j<=10){
try{
if(j==5){
j=j+1
throw new Exception("...")
}
println(s"j=${j}")
j=j+1
}catch {
case e:Exception =>
}
}*/
//使用scala的封装实现continue
while (j<=10){
breakable({
j=j+1
if(j==5) break()
println(s"j=${j}")
})
}
}
第 3 章 Scala中方法和函数
1.Scala中方法定义
/**
* 方法语法: def 方法名( 变量名:类型,... ) : 返回值类型 = { 方法体 }
*
* scala方法可以定义在方法中
*
* 方法如果定义在类中是可以重载的
*
* 方法如果定义在方法中是不可以重载的
*/
def main(args: Array[String]): Unit = {
val result = add(2,3)
println(result)
//scala方法可以定义在方法中
def add2( x:Int,y:Int ) = { x* y }
//def add2( x:Int ) = { x* 10 }
println(add2(4, 5))
}
//方法如果定义在类中是可以重载的
def add( x:Int , y:Int ) = {
x + y
}
def add( x:Int ) = {
x * 10
}
1.2.Scala方法简化
/**
* scala方法的简化原则:
* 1、如果方法体中只有一行语句,{ }可以省略
* 2、如果方法不需要返回值,那么=可以省略
* 3、如果使用方法体{}中最后一个表达式的结果值作为方法的返回值,那么此时返回值类型可以省略
* 如果方法体中有return关键字必须定义返回值类型
* 4、如果方法不需要参数,那么定义方法的()可以省略
* 如果定义方法的时候没有(),那么在调用方法的时候也不能带上()
* 如果定义方法的时候有(),那么在调用方法的时候()可以省略也可以不省略
* 在简化的时候,=与{ }不能同时省略
*/
def main(args: Array[String]): Unit = {
println(add2(2, 3))
printHello2("lisi")
//如果定义方法的时候没有(),那么在调用方法的时候也不能带上()
printName2
printName()
printName
}
//基本定义方法的语法
def add(x:Int,y:Int):Int = {
x+y
}
//如果方法体中只有一行语句,{}可以省略
def add2(x:Int,y:Int):Int = x+y
//基本语法
def printHello(name:String):Unit = {
println(s"hello ${name}")
}
//如果方法不需要返回值,那么=可以省略
def printHello2(name:String) {
println(s"hello ${name}")
}
//基本语法
def m1(x:Int,y:Int):Int = {
x+y
}
//如果使用方法体{ }中最后一个表达式的结果值作为方法的返回值,那么此时返回值类型可以省略
def m2(x:Int,y:Int) = {
x+y
}
//如果方法体中有return关键字必须定义返回值类型
def m3(x:String) = {
/* if(x==null) return null;
return "hello";*/
if(x==null) {
null
}else{
"hello"
}
}
//基本语法
def printName():Unit = {
println(".............")
}
//如果方法不需要参数,那么定义方法的是()可以省略
def printName2:Unit = {
println("............")
}
/**
* 在简化的时候,=与{}不能同时省略
*/
def printName3 = println("............")
1.3.Scala方法参数
/**
* java方法参数:
* 1、public 返回值类型 方法名(类型 参数名,..) { 方法体 }
* 2、可变参数: public 返回值类型 方法名(类型... 参数名) { 方法体 }
* scala方法的参数
* 1、正常形式: def 方法名(参数名:类型,..):返回值类型 = {方法体}
* 2、默认值: def 方法名(参数名:类型=默认值,..):返回值类型 = {方法体}
* 如果默认值单独使用,在定义方法的时候需要将默认值定义在参数列表最后面
* 3、带名参数:
* 指调用方法的时候将指定值传递给哪个参数: 方法名(参数名=值)
* 4、可变参数: def 方法名(参数名:参数类型,..,参数名:参数类型*)
* 可变参数必须定义在参数列表的最后面
* 可变参数不能与默认值参数、带名参数一起使用
* 可变参数不能直接传递集合,但是可以通过 集合名称:_* 的方式将集合的所有元素传递给可变参数
*
* @param args
*/
def main(args: Array[String]): Unit = {
println(add(2, 3))
println(add2())
// 如果默认值单独使用,在定义方法的时候需要将默认值定义在参数列表最后面
println(add3(10))
//带名参数: 指调用方法的时候将指定值传递给哪个参数
println(add4(y=10))
println(add5(10,20,3,4,5,6,7,8))
val paths = getPaths(7,"/user/warehouse/hive/user_info")
readPaths(paths:_*)
}
def add(x:Int,y:Int) = x+y
//默认值: def 方法名(参数名:类型=默认值,..):返回值类型 = {方法体}
def add2(x:Int=10,y:Int=20) = x+y
// 如果默认值单独使用,在定义方法的时候需要将默认值定义在参数列表最后面
def add3(y:Int,x:Int=10) = x+y
def add4(x:Int=10,y:Int) = x+y
def add5(x:Int,y:Int,z:Int*) = {
x+y+z.sum
}
/**
* /user/warehouse/hive/user_info/20201017
* /user/warehouse/hive/user_info/20201016
* /user/warehouse/hive/user_info/20201015
* /user/warehouse/hive/user_info/20201014
* /user/warehouse/hive/user_info/20201013
* /user/warehouse/hive/user_info/20201012
* /user/warehouse/hive/user_info/20201011
* /user/warehouse/hive/user_info/20201010
*
* 需求: 统计前7天的用户注册数
*/
def readPaths(path:String*): Unit ={
//模拟读取数据
println(path.toBuffer)
}
def getPaths(n:Int,pathPrefix:String) = {
//获取当前日期
val currentDate = LocalDateTime.now()
for(i<- 1 to n) yield {
//日期加减法
val time = currentDate.plusDays(-i)
//拼接路径
val str = time.format(DateTimeFormatter.ofPattern("yyyyMMdd"))
s"${pathPrefix}/${str}"
}
}
2.Scala中函数的定义
/**
* 函数的语法: val 函数名 = (参数名:参数类型,....) => { 函数体 }
* 函数的返回值就是函数体的块表达式的结果值
* 函数不可以重载,因为函数名其实就是变量名,同一作用域不能存在同名参数
*
* 函数的简化:
* 1、如果函数体中只有一行语句,{}可以省略
*
* 函数在调用的时候必须带上()
*/
def main(args: Array[String]): Unit = {
println(add(2, 3))
//方法就是函数,函数也是对象
println(add(2,3))
println(add2(2,3))
println(add3(2,3))
println(add4)
}
val add = (x:Int,y:Int) => {
x-y
}
val add4 = () => 10 * 10
val add3 = (x:Int,y:Int) => x+y
//函数不可以重载,因为函数名其实就是变量名,同一作用域不能存在同名参数
/* val add = (x:Int) => {
x-10
}*/
val add2 = new Function2[Int,Int,Int] {
override def apply(v1: Int, v2: Int): Int = v1-v2
}
3.Scala中方法和函数的区别
/**
* 方法和函数的区别:
* 1、方法如果定义在类里面,可以重载,函数因为是对象,所以不能重载
* 2、方法是保存在方法区,函数是对象保存在堆里面
* 联系:
* 1、如果方法定义在方法里面,它其实就是函数
* 2、方法可以手动转成函数: 方法名 _
*/
def main(args: Array[String]): Unit = {
val f = m1 _
println(f(2,3))
}
/**
* 方法重载
*/
def add(x:Int,y:Int):Int = x+y
def add(x:Int) = x * x
val func = (x:Int,y:Int) => x+y
//val func = (x:Int) => x*x
def m1(x:Int,y:Int) = x+y
4.高阶函数
/**
* 高阶函数: 以函数作为参数或者返回值的方法/函数称之为高阶函数
*
*
*/
def main(args: Array[String]): Unit = {
val func = (x:Int,y:Int) => x+y
println(add(10, 20, func))
//方法就是函数
//println(add(3,5,m1 _))
println(add(3,5,m1))
}
/**
* 高阶函数
* @param x
* @param y
* @param func 函数对象,封装的操作
* @return
*/
def add(x:Int,y:Int,func: (Int,Int)=>Int ) = {
func(x,y)
}
def m1(x:Int,y:Int) = x*y
4.1高阶函数的简化
/**
* 高阶函数的简化:
* 1、将函数作为值进行传递
* 2、函数的参数类型可以省略
* 3、如果函数的参数在函数体中只使用了一次,那么可以用_代替
* 1、如果在函数体中参数的使用顺序与参数的定义顺序不一致,不能用_代替
* 2、如果函数的参数只有一个,并且在函数体中没有做任何操作直接将函数的参数返回,此时也不能用_代替
* 4、如果函数只有一个参数,函数参数列表的()可以省略
*
*/
def main(args: Array[String]): Unit = {
val func = (x:Int,y:Int)=>x*y
println(add(3, 5, func))
//1、将函数作为值进行传递
println(add(3,5, (x:Int,y:Int)=>x*y ))
//2、函数的参数类型可以省略
println(add(3,5, (x,y)=>x*y ))
//3、如果函数的参数在函数体中只使用了一次,那么可以用_代替
// 前提:
// 1、如果在函数体中参数的使用顺序与参数的定义顺序不一致,不能用_代替
// 2、如果函数的参数只有一个,并且在函数体中没有做任何操作直接将函数的参数返回,此时也不能用_代替
// 3、如果函数体中有嵌套,并且函数的参数处于嵌套中以表达式的方法存在,,此时也不能用_代替
println(add(3,5, _+_ ))
// 1、如果在函数体中参数的使用顺序与参数的定义顺序不一致,不能用_代替
println(add(3,5, (x,y)=>y-x )) //不能用_简化
//println(add(3,5,_-_))
val func2 = (x:Int) => x
println(m1(5, func2))
println(m1(5, (x:Int) => x))
println(m1(5, (x) => x))
//不能用_简化
val result = m1(5, _)
//println(m1(5, _))
//
//println(result(func2))
//4、如果函数只有一个参数,函数参数列表的()可以省略
println(m1(5, x => x))
val func10 = (x:Int) => (x+10)*2
println(add3(10, x => (x+10)*2))
println(add3(20,x=>(x)+10))
println(add3(20,(_)+10))
}
def add(x:Int,y:Int,func: (Int,Int)=>Int ) = func(x,y)
def m1(x:Int, func: Int => Int) = func(x)
def add3(x:Int,func: Int=>Int) = func(x)
4.2高阶函数例子
/**
* 1、定义一个高阶函数,按照指定的规则对集合里面的每个元素进行操作
* 比如: val arr = Array[String]("spark","hello","java","python")
* 对集合中每个元素进行操作,得到集合每个元素的长度
* val result = Array[Int](5,5,4,6)
*/
def main(args: Array[String]): Unit = {
val arr = Array[String]("spark","hello","java","python")
val func = (x:String) => x.charAt(2).toInt
val result = map(arr,func)
println(result.toBuffer)
}
def map(arr:Array[String],func: String => Int)={
for(element<- arr) yield {
func(element)
}
}
4.3定义高阶函数对元素进行聚合
/**
* 2、定义一个高阶函数,按照指定的规则对集合中的所有元素进行聚合
* val arr =Array[Int](10,2,4,6,1,8,10)
* 求得集合中的所有元素的和
* val result = xx
*/
def main(args: Array[String]): Unit = {
val arr =Array[Int](10,2,4,6,1,8,10)
val func = (agg:Int,curr:Int)=> agg * curr
println(reduce(arr, func))
//1、将函数作为参数直接传递
println(reduce(arr, (agg:Int,curr:Int)=> agg * curr))
//2、函数的参数类型可以省略
println(reduce(arr, (agg,curr)=> agg * curr))
//3、函数的参数在函数体中只使用了一次,可以用_代替
println(reduce(arr, _ * _))
}
def reduce( arr:Array[Int],func: (Int,Int)=>Int )={
var tmp:Int = arr(0)
for(i<- 1 until arr.length) {
tmp = func(tmp,arr(i))
}
tmp
}
4.4定义高阶函数求最大元素
/**
* 3、定义一个高阶函数,按照指定的规则获取指定最大元素
* val arr = Array[String]("zhangsan 20 3000","lisi 30 4000","wangwu 15 3500")
* 获取年龄最大的人的数据
* val result = "lisi 30 4000"
*
*/
def main(args: Array[String]): Unit = {
val arr = Array[String]("zhangsan 20 3000","lisi 30 4000","wangwu 15 3500")
val func = (x:String,y:String) => {
val first = x.split(" ")(2).toInt
val last = y.split(" ")(2).toInt
if(first>last) {
x
}else{
y
}
}
println(maxBy1(arr, func))
println(maxBy2(arr, (x: String) => x.split(" ")(2).toInt))
}
def maxBy1( arr:Array[String], func: (String,String)=> String)={
var tmp = arr(0)
for(i<- 1 until arr.length){
tmp = func(tmp,arr(i))
}
tmp
}
def maxBy2( arr:Array[String],func: String=>Int) = {
var tmp = func(arr(0))
var result = arr(0)
for(element<- arr){
if(tmp<func(element)){
tmp = func(element)
result = element
}
}
result
}
4.6定义高阶函数进行分组
/**
* 4、定义一个高阶函数,按照指定的规则对数据进行分组
* val arr = Array[String]("zhangsan 男 深圳","lisi 女 深圳","王五 男 北京")
* 根据性别进行分组
* val result = Map[String,List[String]](
* "男"-> List("zhangsan 男 深圳","王五 男 北京"),
* "女" -> List("lisi 女 深圳")
* )
*
*/
def main(args: Array[String]): Unit = {
val arr = Array[String]("zhangsan 男 深圳","lisi 女 深圳","王五 男 北京")
val func = (x:String) => x.split(" ")(1)
println(groupBy(arr, func))
println(groupBy(arr,(x:String) => x.split(" ")(1)))
println(groupBy(arr,(x) => x.split(" ")(1)))
println(groupBy(arr,x => x.split(" ")(1)))
println(groupBy(arr,_.split(" ")(1)))
}
def groupBy( arr:Array[String],func: String=>String )={
//1、创建一个分组的存储容器
val result = new util.HashMap[String,util.List[String]]()
//2、遍历集合所有元素
for(element<- arr){
//得到分组的key
val key = func(element)
//3、判断分组的key是否在容器中存在,如果不存在,则直接添加到容器中
if(!result.containsKey(key)){
val list = new util.ArrayList[String]()
list.add(element)
result.put(key,list)
}else{
//4、如果存在,此时应该取出key对应的List,将元素添加到List
val list = result.get(key)
list.add(element)
}
}
//5、返回结果
result
}
4.7定义高阶函数对元素进行过滤
/**
* 5、定义一个高阶函数,按照指定的规则对数据进行过滤,保留符合要求的数据
* val arr =Array[Int](10,2,4,6,1,8)
* 只保留偶数数据
* val result = Array[Int](10,2,4,6,8)
*/
def main(args: Array[String]): Unit = {
val arr =Array[Int](10,2,4,6,1,8)
println(filter(arr, x => x % 2 == 0).toBuffer)
}
def filter( arr: Array[Int], func: Int => Boolean )={
for(element<- arr if( func(element) )) yield {
element
}
}
5.匿名函数
/**
* 匿名函数: 没有函数名的函数
* 匿名函数不能单独使用,只能将匿名函数作为高阶函数的参数进行传递
*/
def main(args: Array[String]): Unit = {
val func = (x:Int,y:Int) => x+y
println(func(20, 10))
//(x:Int,y:Int) => x+y
def add(x:Int,y:Int,func: (Int,Int)=>Int) = {
func(x,y)
}
println(add(10, 20, (x: Int, y: Int) => x + y ))
}
6.柯里化
/**
* 柯里化: 有多个参数列表的方法称之为柯里化
* @param args
*/
def main(args: Array[String]): Unit = {
println(add(10, 20,30))
println(add2(10, 20)(30))
val func = add3(10,20)
println(func(30))
println(add3(10, 20)(30))
println(add4(10,20)(30))
val func2 = add2 _
val func3 = add3 _
}
def add(x:Int,y:Int,z:Int) = x+y+z
//柯里化
def add2(x:Int,y:Int)(z:Int) = x+y+z
/**
* 柯里化演变过程
*/
def add3(x:Int,y:Int) = {
val func = (z:Int) => x+y+z
func
}
def add4(x:Int,y:Int) = {
// Person p = new Person
// return new Person;
//val func = (z:Int) => x+y+z
//func
(z:Int) => x+y+z
}
7.闭包
/**
* 闭包: 函数体中使用了不属于自身的变量的函数
* @param args
*/
def main(args: Array[String]): Unit = {
println(func(100))
}
val b = 10
/**
* 闭包
*/
val func = (x:Int) => {
val c = 10
x + c + b
}
def add(x:Int,y:Int) = {
/* val func = (z:Int)=> {
val func2 = (a:Int)=> a+x+y+z
func2
}
func*/
(z:Int)=> {
(a:Int)=> a+x+y+z
}
}
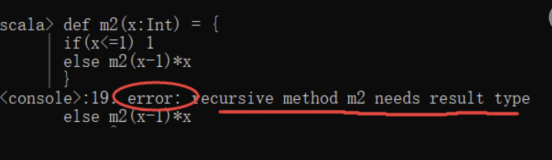
8.递归
/**
* 递归: 自己调用自己称之为递归
* 前提:
* 1、必须要有退出条件
* 2、递归必须定义返回值类型
*/
def main(args: Array[String]): Unit = {
println(m1(5))
}
def m1(n:Int):Int = {
if(n==1){
1
}else{
n * m1(n-1)
}
}
9.惰性求值
/**
* 惰性求值: 变量只有在真正使用的时候才会赋值
* @param args
*/
def main(args: Array[String]): Unit = {
lazy val name = "zhangsan"
val age = 20
println(name)
println(age)
}
10.控制抽象
/**
* 控制抽象: 其实就是一个块表达式,可以将块表达式作为参数[ => 块表达式的结果值类型 ]传递给方法,后续当做函数进行调用
*
* 控制抽象只能用于方法的参数
* 控制抽象在调用的时候不能带上()
* @param args
*/
def main(args: Array[String]): Unit = {
val b = {
println("xxxxxxxxxxxx")
val c = 20
c * c
}
def m1(x:Int) = {
println(x*x)
}
m1({
println("xxxxxxxxxxxx")
val c = 20
c * c
})
def m2(x:Int,func: Int=>Int) = {
func(x)
func(x)
func(x)
}
m2(10,x=>{
println(".....................")
x+10
})
var i = 0
breakable({
while (i<=10){
if(i==5) break()
println(s"i=${i}")
i=i+1
}
})
val func2 = () => println("hello.........")
func2()
m4({
println("+++++++")
false
})
println("*"*100)
var j = 0
myLoop({
j<=10
})({
println(s"j=${j}")
j = j+1
})
}
def m4(f1: => Unit) = {
//在调用控制抽象的时候不能带上()
f1
f1
f1
}
def myLoop(condition: =>Boolean)(body: =>Unit):Unit = {
if(condition) {
body
myLoop(condition)(body)
}
}
第 4 章 类和对象
1.Scala定义类
//如果class中没有任何东西,{}可以省略
class Person
/**
* java class创建语法: 修饰符 class 名称{...}
*
* scala里面没有public关键字,默认就是public
* scala创建class的语法: class 名称 {...}
* scala创建对象: new class名称(..)
*/
def main(args: Array[String]): Unit = {
//如果使用无参的构造器,()可以省略
val person = new Person
println(person)
}
1.1定义类中属性和方法
class Person{
//定义属性: 修饰符 val/var 属性名:类型 = 值
//val定义的属性不可被修改
//var定义的属性可以被修改
//@BeanProperty注解不能用在private修饰的属性上
@BeanProperty
var name = "zhangsan"
@BeanProperty
var age = 20
/* def setName(name:String) = this.name=name
def getName() = this.name
def setAge(age:Int) = this.age = age
def getAge() = this.age*/
//scala中属性有默认的get/set方法,get的方法名其实就是属性名,set的方法名其实就是 属性名=
//在class中var修饰的属性可以使用_初始化,使用_初始化的时候必须指定属性的类型
var address:String = _
//setXXx getXXx
//JSON解析
//定义方法: 修饰符 def 方法名(参数名:参数类型,...):返回值类型 = {方法体}
def printName () = println(s"name=${name}")
//定义函数: 修饰符 val 函数名 = (参数名:参数类型,...) => {函数体}
val func = (x:Int,y:Int) => x+y
}
def main(args: Array[String]): Unit = {
val person = new Person
println(person.name)
println(person.age)
println(person.address)
person.age=(100)
println(person.age)
person.printName()
println(person.func(10, 20))
println("*"*100)
val json = """{"name":"lisi","age":100}"""
//json转对象
val person2 = JSON.parseObject(json,classOf[Person])
println(person2.name)
println(person2.age)
}
1.2 scala中构造方法
def this(name:String) {
//第一行必须调用其他的辅助构造器或者主构造器
this(name=name,address="beijing")
//this("lisi",100)
}
def this(age:Int) {
this("zhaoliu")
}
def this(name:String,age:Int) {
this(name=name,address="beijing")
}
}
/**
* java中构造方法的定义: 修饰符 类名(参数类型 参数名,..) {..}
*
* scala中构造方法分为两种:
* 1、主构造器: 定义类名后面{}之前,通过()表示
* 主构造器中属性的定义: [修饰符] [val/var] 属性名:类型 = 默认值
* 柱构造器中val/var以及不写val/var的区别:
* val定义的属性不能更改
* var定义的数可以更改
* 使用val/var修饰的非private的属性既可以在class内部使用也可以在class外部使用
* 不用val/var修饰的属性只能在class内部使用
* 2、辅助构造器
* 辅助构造器定义在class里面
* 语法: def this(参数名:参数类型,...){
* //第一行必须调用其他的辅助构造器或者主构造器
* this(..)
* }
*
*/
def main(args: Array[String]): Unit = {
val person = new Person("lisi",100,"shenzhen")
println(person.name)
println(person.age)
println(person.getName)
val person2 = new Person("lisi")
println(person2.getName)
val person3 = new Person(100)
println(person3.getName)
}
1.3 封装
class Person{
@BeanProperty
val name:String = "zhangsan"
//def getName() = this.name
}
/**
* 封装: 属性私有,提供公有的set/get方法
*
* scala中属性一般不私有,通过@BeanProperty注解提供公有的set/get方法
* @BeanProperty对于val修饰的属性只提供get方法
* 对于var修饰的属性提供set与get方法
*/
def main(args: Array[String]): Unit = {
// println($06_Package.AAAAAAA)
val person = new Person
println(person.getName)
}
1.4继承
/*final */class Animal{
/*private */
@BeanProperty val name:String = "zhangsan"
@BeanProperty var age:Int = _
def printHello() = println("...........")
}
class Dog extends Animal{
override val name = "lisi"
override def printHello(): Unit = {
println("888888888888888888888888")
super.printHello()
}
}
/**
* scala中通过extends关键字来实现继承关系
*哪些情况不能被继承:
* 1、private修饰的属性/方法/函数不能被继承
* 2、final修饰的class不能被继承
*子类可以通过override关键字来重写父类的方法/val修饰的属性
*
* var修饰的属性不能通过override来重写
* 子类中可以通过super关键字来调用父类的方法
*
* java中的多态只是方法的多态,属性不多态
* scala中方法和属性都是多态的
*/
def main(args: Array[String]): Unit = {
val dog = new Dog
println(dog.name)
println(dog.age)
dog.printHello()
val animal:Animal = new Dog
animal.printHello()
println(animal.getName)
println(CCCCCCCCCC)
}
1.5scala中包的作用
{
private[chapter06] val AAAAAAA="lisi"
/**
* 包的作用:
* 1、区分同名
* 2、便于管理
* java中对于包的申明方式:
* 1、通过package 包名在.java源文件的第一行
* java中对于包的使用:
* 1、import 包名.*
* 2、import 包名.类名
*java中import导入包必须在声明包后面,class前面
*
* scala中对于包的申明方式:
* 1、通过package 包名在.java源文件的第一行
* 2、通过package 包名{}[通过该方式声明的包在项目结构下看不到但是在target目录下可以看到]
* scala中对于包的使用:
* 1、导入包下所有类: import 包名._
* 2、导入包下某个类: import 包名.类名
* 3、导入包下多个类: import 包名.{类名1,类名2,..}
* 4、导入包下某个类,并起别名: import 包名.{类名=>别名}
* 5、导入包下除开某个类的其他类: import 包名.{类名=>_,_}
* scala可以在任何地方导入包。
* 如果是在父作用域中导入的包,子作用域可以使用
* 子作用域导入的包,父作用域不可以使用
* scala中访问修饰符可以搭配package使用: private[包名] val 属性名:类型 = 值 【代表该属性只能在该包下使用】
*
* 包对象:
* 语法: package object 包名{...}
* 包对象中非private修饰的属性/方法/函数可以在包下任何地方使用
*/
def main(args: Array[String]): Unit = {
import scala.util.control.Breaks._
val scalaMap = new mutable.HashMap[String,String]()
}
}
package bb{
class Student
}
1.6 抽象类
abstract class Animal{
//抽象属性
val name:String
//具体属性
var age:Int = 10
//抽象方法
def m1(x:Int,y:Int)
//具体方法
def add(x:Int,y:Int) = x*y
}
class Dog extends Animal {
//具体方法
override def m1(x: Int, y: Int): Unit = x+y
//重写抽象属性
override val name: String = "lisi"
}
/**
* 抽象类:
* 1、语法: abstract class 类名{....}
* 2、scala的抽象类中可以定义抽象方法,也可以定义具体方法
* scala中抽象类中可以定义抽象属性,也可以定义具体属性
* 抽象方法: 没有方法体的方法称之为抽象方法,定义抽象方法的时候如果不定义返回值类型,返回值默认就是Unit
* 抽象属性: 没有赋予初始值的属性【定义抽象属性的时候,属性的类型必须定义】
*
*/
def main(args: Array[String]): Unit = {
val dog = new Dog
println(dog.m1(10, 20))
println(dog.name)
println(dog.age)
//匿名子类
val p = new Animal {
override val name: String = "zhangsan"
override def m1(x: Int, y: Int): Unit = println(s"${x} ${y}")
}
println(p.name)
p.m1(10,20)
}
1.7 伴生类和伴生对象
object $08_SingleObject {
class Person(val age:Int){
private val name = "艾尔"
def this() = {
this(10)
}
def xx = Person.printHello()
}
object Person{
val age = 100
private def printHello() = {
val person = new Person(20)
println(person.name)
}
def apply(age:Int) = new Person(age)
def apply() = new Person
}
//val name = "xxx"
/**
* 单例对象的语法: object xx{...}
*
* object中所有的方法/属性/函数都是类似java static修饰的。可以通过 object名称.属性/方法/函数 的方法调用
*
* 伴生类和伴生对象
* 1、class与object的名称要一致
* 2、class与object要在同一个.scala文件中
*
* 伴生类和伴生对象可以互相访问对方private修饰的属性/方法/函数
*
* apply方法: 主要用来简化伴生类的对象创建
* 后续可以通过 object名称.apply(..) / object名称(..) 创建伴生类的对象
* @param args
*/
def main(args: Array[String]): Unit = {
val obj1 = $08_SingleObject
val obj2 = $08_SingleObject
println(obj1)
println(obj2)
//println($08_SingleObject.name)
val person = new Person(20)
person.xx
val person4 = Person.apply(10)
person4.xx
val person5 = Person(10)
person5.xx
val arr = Array[Int](10,20,30,40)
val p = Person()
}
}
2. 特质
trait Logger{
//抽象属性
val name:String
//具体属性
val age:Int = 20
//抽象方法
def add(x:Int,y:Int):Int
//具体方法
def m1(x:Int) = x * x
}
trait Logger2
class A
class WarnLogger extends A with Logger with Logger2 {
override val name: String = "zhangsan"
override def add(x: Int, y: Int): Int = x+y
}
/**
* 语法: trait 特质名{....}
* 在trait中既可以定义抽象方法也可以定义具体方法
* 既可以定义抽象字段也可以定义具体字段
*
* 子类如果需要继承父类,extends关键字用来继承父类,trait的实现通过with关键字来做
* 子类如果不需要继承父类,extends关键字用来继承第一个trait,后续其他的trait通过with关键字实现
*
*/
def main(args: Array[String]): Unit = {
//匿名子类
val logger = new Logger {
override val name: String = "lisi"
override def add(x: Int, y: Int): Int = x * y
}
println(logger.add(10, 20))
val warn = new WarnLogger
println(warn.add(100,200))
}
2.1对象混入
trait Logger{
def add(x:Int,y:Int) = x+y
}
class Warnlogger
/**
* 对象混入: 只让某个对象拥有特质的属性和方法
* 语法: new class名称 with 特质名
* @param args
*/
def main(args: Array[String]): Unit = {
val warnlogger = new Warnlogger with Logger
println(warnlogger.add(10, 20))
val a = new Warnlogger
//a.add()
}
2 .2 trait方法
trait ParentLogger{
def log(msg:String) = println(s"ParentLogger:${msg}")
}
trait Logger1 extends ParentLogger{
override def log(msg:String) = {
println(s"Logger1:${msg}")
}
}
trait Logger2 extends ParentLogger{
override def log(msg:String) = {
println(s"Logger2:${msg}")
}
}
trait Logger3 extends ParentLogger{
override def log(msg:String) = {
println(s"Logger3:${msg}")
}
}
class A extends Logger1 with Logger2 with Logger3{
override def log(msg: String): Unit ={
println(s"A:${msg}")
super[Logger2].log(msg)
}
}
/**
* scala可以多实现,如果实现的多个trait中有同名方法,子类实现这多个trait之后相当于有多个同名方法
* 解决方案:
* 1、在子类中重写父trait的同名方法
* 2、创建一个新trait,在新trait中创建一个同名方法,子类的父trait全部继承该新trait。
* 如果父trait中有通过super关键字调用同名方法,此时调用顺序是按照继承顺序从右向左开始调用
* @param args
*/
def main(args: Array[String]): Unit = {
val a = new A
a.log("xxxx")
}
2.3 对象的序列化
class Logger
trait ReadAndWrite{
_:Serializable =>
/**
* 从磁盘读取对象
*/
def read() = {
val ois = new ObjectInputStream(new FileInputStream("d:/obj.txt"))
val obj = ois.readObject()
ois.close()
obj
}
/**
* 将当前对象写入磁盘
*/
def write() = {
val oos = new ObjectOutputStream(new FileOutputStream("d:/obj.txt"))
oos.writeObject(this)
oos.close()
}
}
class Person(val name:String,val age:Int) extends ReadAndWrite with Serializable
/**
* 定义一个trait,trait中自带read、write两个方法能够实现将当前对象读取/写入到磁盘
*
* 自身类型: 子类在实现trait的时候提示必须要先继承/实现某个类型
*/
def main(args: Array[String]): Unit = {
val person = new Person("lisi",20)
person.write()
val p = new Person("zhangsan",30)
val obj = p.read()
println(obj.asInstanceOf[Person].name)
}
3. Scala类型检查
class Animal{
def xx() = println("Animal")
}
class Dog extends Animal{
val name= "xx"
override def xx() = println("Dog")
}
class Pig extends Animal{
val age= 20
override def xx() = println("Dog")
}
def getAnimal() = {
val r = Random.nextInt(10)
if(r%5==0)
new Dog
else if(r%2==0)
new Pig
else
new Animal
}
/**
* java类型判断: 对象 instanceof 类型
* java中类型的强转: (类型)对象
*
* scala类型判断: 对象.isInstanceOf[类型]
* scala中类型强转: 对象.asInstanceOf[类型]
*
* java中获取对象的class形式: 对象.getClass()
* java中获取类的class形式: 类名.class
*
* scala中获取对象的class形式: 对象.getClass()
* scala中获取类的class形式: classOf[类名]
*
*
*/
def main(args: Array[String]): Unit = {
val animal = getAnimal()
println(animal.getClass)
if(animal.isInstanceOf[Animal]){
val pig = animal.asInstanceOf[Pig]
println(pig.age)
}else{
val dog = animal.asInstanceOf[Dog]
println(dog.name)
}
}
4. 枚举类
object Test20 extends App {
println("xxxxxxxxxxx");
}
object $14_App {
// 枚举类
object Color extends Enumeration {
val RED = Value(1, "red")
val YELLOW = Value(2, "yellow")
val BLUE = Value(3, "blue")
}
def main(args: Array[String]): Unit = {
println(Color.RED)
}
}
5. 类起别名
/**
* 新类型: 给类起别名
* type myarr = Array[String]
*/
def main(args: Array[String]): Unit = {
type s = String
type myarr = Array[String]
val name:s = "name"
val arr:myarr = Array[String]("....")
}
第 5 章 数组和集合
5.1 数组
5.1.1不可变数组
/**
* 1、不可变数组的创建方式:
* 1、Array[元素类型](初始元素,..)
* 2、new Array[元素的类型](数组的长度)
*
* 2、插入数据
* 3、删除数据
* 4、获取数据
* 5、修改数据
*
* 一个+与两个+的区别:
* 一个+ 是添加单个元素
* 两个+ 是添加一个集合的所有元素
* 冒号在前与冒号在后的区别:
* 冒号在前 是将元素添加在集合的最末尾
* 冒号在后 是将元素添加在集合的最前面
* 不带冒号 是将元素添加在集合的最末尾
*/
def main(args: Array[String]): Unit = {
//Array[元素类型](初始元素,..)
val arr = Array[Int](10,2,4,6,1)
println(arr.toBuffer)
//new Array[元素的类型](数组的长度)
val arr2 = new Array[Int](10)
println(arr2.toBuffer)
//添加数据
val arr3 = arr.+:(20)
println(arr3.toBuffer)
println(arr.toBuffer)
val arr4 = arr.:+(30)
println(arr4.toBuffer)
//添加一个集合所有元素
val arr5 = arr.++(Array(100,200,300))
println(arr5.toBuffer)
val arr6 = arr.++:(Array(400,500,600))
println(arr6.toBuffer)
//获取元素
val element = arr6(2)
println(element)
//修改元素
arr6(2)=1000
//将不可变数组转可变数组
println(arr6.toBuffer)
for(i<- arr){
println(i)
}
}
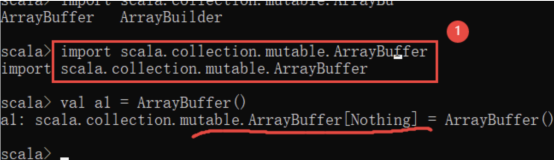
5.1.2 可变数组
/**
* 1、可变数组的创建:
* 1、ArrayBuffer[元素类型](初始元素,...)
* 2、new ArrayBuffer[元素类型]()
* 2、添加元素
* 3、删除元素
* 4、修改元素
* 5、获取元素
* 集合方法的区别:
* 一个+/-与两个+/-的区别:
* 一个+/-是添加单个元素
* 两个+/-是添加一个集合的所有元素
* 冒号在前与冒号在后以及不带冒号的区别:
* 冒号在前是将元素添加在集合的末尾
* 冒号在后是将元素添加在集合的最前面
* 不带冒号是将元素添加在集合的末尾
* 带=与不带=的区别:
* 带=是修改集合本身
* 不带=是生成新集合,原有集合没有改变
* +与-的区别:
* +是指添加元素
* -是指删除元素
*/
def main(args: Array[String]): Unit = {
//1、ArrayBuffer[元素类型](初始元素,...)
val arr = ArrayBuffer[Int](2,5,7,1,3)
println(arr)
//2、new ArrayBuffer[元素类型]()
val arr2 = new ArrayBuffer[Int]()
println(arr2)
//添加元素
val arr3 = arr.+:(10)
println(arr3)
println(arr)
arr.+=(20)
println(arr)
arr.+=:(30)
println(arr)
val arr4 = arr.++(Array(100,200))
println(arr4)
val arr5 = arr.++:(Array(300,400))
println(arr5)
arr.++=(Array(1000,3000))
println(arr)
arr.++=:(Array(400))
println(arr)
arr.+=:(500)
arr.+=:(400)
println("*"*100)
println(arr)
//删除元素
val arr6 = arr.-(400)
println(arr6)
arr.-=(1000)
println(arr)
val arr7 = arr.--(Array(400,500,30))
println(arr7)
arr.--=(Array(2,5,7,50))
println(arr)
//获取元素
println(arr(2))
//修改元素
arr(2)=50
println(arr)
//可变数组转不可变数组
println(arr.toArray)
//多维数组
val array = Array.ofDim[Int](3,4)
println(array.length)
println(array(0).length)
}
5.1.2 List
/**
* 1、创建方式:
* 1、List[元素类型](初始元素,...)
* 2、元素 :: 元素 :: .. :: list/Nil
* :: 最后面必须要是一个List或者是Nil
* Nil就是相当于是List的子类
*
* ::与:::的区别:
* ::是添加单个元素
* ::: 是添加一个集合的所有元素
*/
def main(args: Array[String]): Unit = {
//1、List[元素类型](初始元素,...)
val list = List[Int](10,20,30)
println(list)
//元素 :: 元素 :: .. :: list/Nil
val list2 = 10 :: 20 :: 30 :: Nil
println(list2)
var list3:List[Int] = Nil
list3 = list2
//2、添加元素
val list4 = list2.:+(50)
println(list4)
val list6 = list2.+:(60)
println(list6)
val list7 = list2.++(Array(100,200,300))
println(list7)
val list8 = list2.++:(Array(400,500,600))
println(list8)
val list9 = 100 :: list8
println(list9)
val list10 = list9 ::: list
println(list10)
//获取元素
println(list10(2))
//修改元素
//list10(2) = 1000
val list11 = list10.updated(2,1000)
println(list11)
//List转数组
println(list11.toBuffer)
}
5.1.3可变List
/**
* 1、创建方式: ListBuffer[元素类型](初始元素,....)
*/
def main(args: Array[String]): Unit = {
//创建方式: ListBuffer[元素类型](初始元素,....)
val list = ListBuffer[Int](10,20,30)
println(list)
//添加元素
val list2 = list.+:(40)
println(list2)
val list3 = list.:+(50)
println(list3)
list.+=(60)
println(list)
list.+=:(70)
println(list)
val list5 = list.++(Array(80,90,100))
println(list5)
val list6 = list.++:(Array(200,300))
println(list6)
list.++=(Array(100,200))
println(list)
list.++=:(Array(1000,2000))
println(list)
list.append(500,600,700)
println(list)
//删除元素
val list8 = list.-(1000)
println(list8)
list.-=(2000)
println(list)
val list9 = list.--(Array(10,20,30))
println(list9)
list.--=(Array(500,600,700))
println(list)
list.remove(0)
println(list)
//获取元素
println(list(0))
//修改
list(0)=1000
println(list)
list.update(1,200)
println(list)
val list10 = list.updated(3,500)
println(list10)
}
不可变set
/**
* set的特点: 无序、不重复
* 创建方式: Set[元素类型](初始元素,...)
*/
def main(args: Array[String]): Unit = {
val set = Set[Int](1,5,5,2,10,3)
println(set)
//添加元素
val set2 = set.+(20)
println(set2)
val set3 = set.++(Array(100,500,200))
val set4 = set.++:(Array(100,500,200))
println(set3)
println(set4)
//删除元素
val set5 = set4.-(500)
println(set5)
val set6 = set4.--(Array(2,10,100))
println(set6)
//获取元素
//修改元素
for(i<- set4){
println(i)
}
}
可变set
def main(args: Array[String]): Unit = {
//创建方式: mutable.Set[元素类型](初始元素,...)
val set = mutable.Set[Int](10,2,6,1,3)
println(set)
//添加元素
val set2 = set.+(10)
set.+=(20)
println(set2)
println(set)
val set3 = set.++(Array(100,200))
val set4 = set.++:(Array(100,200))
set.++=(Array(300,400))
println(set3)
println(set4)
println(set)
set.add(1000)
println(set)
//删除元素
val set5 = set.-(300)
set.-=(400)
println(set5)
println(set)
val set6 = set.--(Array(300,2,20))
set.--=(Array(10,2,1,6))
println(set6)
println(set)
set.remove(1000)
println(set)
//set.update()
}
元组
object $07_Tuple {
class Person(val name:String,val age:Int,val address:String)
class School(val name:String,val clazz:Clazz)
class Clazz(val name:String,val student:Student)
class Student(val name:String,val age:Int)
/**
* 创建方式:
* 1、通过()方式创建: (初始元素,..)
* 2、如果是创建二元元组,还可以 K->V 的方式创建
* 元组一旦创建,长度以及元素都不可改变
* 元组最多只能存放22个元素
* 元组的值的获取: 元组的变量._角标 【角标从1开始】
*/
def main(args: Array[String]): Unit = {
//1、通过()方式创建: (初始元素,..)
val t1 = ("zhangsan",20,"beijing")
//2、如果是创建二元元组,还可以 K->V 的方式创建
val t2 = "zhangsan" -> 20
println(t1._1)
val school = new School("宝安中学",new Clazz("xx",new Student("lisi",20)))
val school2 = ("宝安中学",("xx",("lisi",20)))
println(school2._2._2._1)
}
def m1(name:String,age:Int,address:String) = {
(name,age,address)
}
}
不可变Map
/**
* 创建方式:
* 1、Map[K的类型,V的类型]( (K,V),(K,V),... )
* 2、Map[K的类型,V的类型] ( K -> V ,...)
* Map中不能有重复key
* Option: 提醒外部当前可能返回数据为空需要进行处理
* Some: 表示非空,数据封装在Some中,后续可以通过get方法获取数据
* None: 表示为空
*/
def main(args: Array[String]): Unit = {
val map = Map[String,Int]( ("zhangsan",20),("lisi",30),("zhangsan",40) )
val map2 = Map[String,Int]( "zhangsan"->20,"lisi"->30)
println(map)
println(map2)
//添加元素
val map3 = map.+("wangwu"->30)
val map4 = map.++( Map(("aa",1),("bb",2)) )
println(map3)
println(map4)
val map5 = map.++:(Map(("aa",1),("bb",2)))
println(map5)
println(map5.getClass)
//更新
val map6 = map5.updated("cc",100)
println(map6)
//获取key对应的value数据
//println(map6("dd"))
//println(map6.get("dd").get)
println(map6.getOrElse("dd", 1000))
//获取map所有的key
for(key<- map6.keys){
println(key)
}
//获取所有的value
for(value<- map6.values){
println(value)
}
}
可变Map
/**
* 创建方式:
* 1、mutable.Map[K的类型,V的类型]( (K,V),(K,V),.. )
* 2、mutable.Map[K的类型,V的类型]( K->V,.. )
* @param args
*/
def main(args: Array[String]): Unit = {
val map = mutable.Map[String,Int]( ("zhangsan",20),("lisi",30) )
val map2 = mutable.Map[String,Int]( "zhangan"->30,"lisi"->20)
println(map)
println(map2)
//添加元素
val map3 = map.+( "wangwu"->25 )
map.+=( "aa"->10)
println(map3)
println(map)
val map4 = map.++(Map[String,Int]("cc"->1,"dd"->2))
val map5 = map.++:(Map[String,Int]("ee"->10,"ff"->20,"aa"->30))
println(map4)
println(map5)
map.++=(Map[String,Int]("pp"->100,"ww"->200))
println(map)
map.put("tt",1000)
println(map)
//删除元素
val map6 = map.-("aa")
println(map6)
map.-=("ww")
println(map)
val map7 = map.--(List("lisi","tt"))
println(map7)
map.--=(List("zhangsan","pp"))
println(map)
map.remove("lisi")
println(map)
//获取元素
println(map.getOrElse("ddd",-1))
//获取所有key
for(key<- map.keys){
println(key)
}
//获取所有的vlaue
for(value<- map.values){
println(value)
}
//修改元素
map("aa")=1000
println(map)
map.update("tt",100)
println(map)
val map10 = map.updated("tt",1)
println(map10)
println(map)
}
获取集合属性
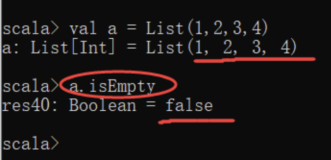
def main(args: Array[String]): Unit = {
val list = List[Int](10,20,30)
//获取集合的长度
println(list.size)
println(list.length)
//是否包含某个元素
println(list.contains(100))
//判断集合是否为空
println(list.isEmpty)
//判断集合是否不为空
println(list.nonEmpty)
//生成字符串
println(list)
println(list.mkString("#"))
}
集合方法
def main(args: Array[String]): Unit = {
//去重 *****
val list = List[Int](10,10,20,30,2,1,1,50)
val list2 = list.distinct
println(list2)
//删除前多少个元素,保留剩余的元素
val list3 = list.drop(2)
println(list3)
//删除后多少个元素,保留剩余元素
val list4 = list.dropRight(3)
println(list4)
//获取第一个元素 ****
val head = list.head
println(head)
//获取最后一个元素 *****
val last = list.last
println(last)
//获取除开最后一个元素的所有元素
val list5 = list.init
println(list5)
println("*"*100)
//除开第一个元素的所有元素
val list11 = list.tail
println(list11)
//反转
val list7 = list.reverse
println(list7)
//获取子集合
val list8 = list.slice(2,5)
println(list8)
//窗口 ******
//size: 窗口的大小
//step: 窗口滑动的长度
val list9 = list.sliding(3,2)
println(list9.toBuffer)
//获取前多少个元素 *****
val list12 = list.take(3)
println(list12)
//获取后多少个元素
val list13 = list.takeRight(3)
println(list13)
//val list = List[Int](10,10,20,30,2,1,1,50)
val list14 = List[Int](10,1,4,5,20)
//交集[两个集合共同的元素]
val list15 = list.intersect(list14)
println(list15)
//差集[ 除开交集之外的元素 A 差 B => 结果是A中除开交集之外的所有元素 ]
val list16 = list.diff(list14)
println(list16)
//并集【两个集合的所有元素,不去重】
val list17 = list.union(list14)
println(list17)
//拉链
val list18 = List[String]("aa","bb","cc","dd")
val list19 = List[Int](1,2,3)
val list20 = list18.zip(list19)
println(list20)
//反拉链
val list21 = list20.unzip
println(list21)
}
集合初级方法
def main(args: Array[String]): Unit = {
val list = List[Int](2,7,1,9,10,5,3)
//最大值
val max = list.max
//最小值
val min = list.min
println(max)
println(min)
//根据什么获取最大值
val list2 = List[String]("zhangsan 20 3000","lisi 15 5000","wangwu 30 1000")
//maxBy中的函数是针对集合的每个元素
val maxBy = list2.maxBy(x=>x.split(" ")(1).toInt)
println(maxBy)
//根据什么获取最小值
val list3 = List[(String,Int)]( ("ZHANGSAN",1000),("LISI",2500),("WANGWU",3000),("WANGWU",2500) )
//minBy中的函数是针对集合的每个元素
println(list3.minBy(_._2))
//求和
println(list.sum)
//List[String]("spark","hello").sum
//排序
//直接按照元素本身排序[升序]
val list4 = list.sorted
println(list4)
//降序
val list5 = list4.reverse
println(list5)
println(list3.sorted)
//指定按照哪个字段排序[升序] *****
println(list3.sortBy(_._2))
//根据指定的规则排序
println(list.sortWith((x, y) => x < y))
println(list.sortWith((x, y) => y < x))
}
集合高级方法
def main(args: Array[String]): Unit = {
val list = List[String]("spark","hello","java","python")
//map(func: 集合元素类型 => B ): 主要用来转换数据[转换值、转换类型]
// map中的函数是针对集合的每个元素进行操作
// map的应用场景: 一对一 【val B = A.map(..) B集合的元素的个数=A集合元素个数】
val list2 = list.map(x=>x.length)
println(list2)
val list3 = List[Int](10,20,30,40)
val list4 = list3.map(x=>x*x)
println(list4)
//foreach(func: 集合元素类型 => U ):Unit
// foreach中的函数也是针对集合的每个元素
// foreach与map的区别: map有返回值,foreach没有返回值
val list5 = List[(String,Int,String)]( ("lisi",20,"深圳"),("zhangsan",15,"北京") )
list5.foreach(println(_))
val func = (x:(String,Int,String)) => println(x)
list5.foreach(println)
//flatten-压平
//flatten只能用于集合中嵌套集合的场景
//flatten的应用场景: 一对多
val list6 = List[List[String]](
List[String]("aa","bb"),
List[String]("cc","dd"),
List[String]("ee","ff")
)
val list7 = list6.flatten
println(list7)
val list8 = List[List[List[String]]](
List(List[String]("aa","bb"),List[String]("cc","dd")),
List(List[String]("ee","ff"),List[String]("oo","xx"))
)
val list9 = list8.flatten
println(list9)
val list10 = List[String]("spark","hello")
println(list10.flatten)
//flatMap(func: 集合元素类型=> 集合 ) = map+flatten
// flatMap中的函数也是针对集合中的每个元素
// flatMap应用场景: 一对多
val list11 = List[String]("hadoop spark","hello java python")
val list12 = list11.map(x=>x.split(" "))
val list13 = list12.flatten
println(list13)
println(list11.flatMap(_.split(" ")))
//List(hadoop,spark,hello.java,python)
//filter( func: 集合元素类型 => Boolean ) - 过滤
// filter中的函数针对集合的每个元素,filter保留的是函数返回值为true的数据
val list14 = List[Int](10,2,4,5,7,9)
println(list14.filter(_ % 2 == 0))
//groupBy(func: 集合元素类型=> K ) --分组
//groupBy是根据指定的字段进行分组,里面的函数针对是集合每个元素
//groupBy的结果是Map[分组的key,List[原有集合元素类型]]
val list15 = List[(String,String)](
("ZHANGSAN","SHENZHEN"),
("LISI","BEIJING"),
("WANGWU","SHENZHEN"),
("ZHAOLIU","SHENZHEN")
)
//list15.groupBy(x=> x._2)
val list16 = list15.groupBy(_._2)
println(list16)
//reduce(func: (集合元素类型,集合元素类型) => 集合元素类型 ) --聚合
//reduce中的函数是两两聚合,然后将上一次的聚合结果与下一个元素再次聚合
//reduce最终结果是单个数据,数据的类型就是原有集合的元素类型
val list17 = List[Int](10,2,4,5,7,9)
val result = list17.reduce( (agg,curr)=>{
println(s"agg=${agg} curr=${curr}")
agg * curr
})
//reduce的执行过程:
// agg上一次的聚合结果 curr:本次要聚合元素
// 第一次执行的时候,agg的值就是集合第一个元素[10], curr集合第二个元素[2] (agg,curr)=> agg * curr = 20
// 第二次执行的时候,agg上一次的聚合结果[20], curr集合第三个元素[4] (agg,curr)=> agg * curr = 80
// ......
println(result)
//reduceRight(func: (集合元素类型,集合元素类型) => 集合元素类型 )
//reduceRight中的函数是两两聚合,然后将上一次的聚合结果与下一个元素再次聚合
//reduceRight最终结果是单个数据,数据的类型就是原有集合的元素类型
println("*"*100)
val result2 = list17.reduceRight((curr,agg)=>{
println(s"agg=${agg} curr=${curr}")
agg-curr
})
//reduceRight的执行过程:
// agg上一次的聚合结果 curr:本次要聚合元素
// 第一次执行的时候,agg的值就是集合第最后一个元素[9], curr集合倒数第二个元素[7] (agg,curr)=> agg - curr = 2
// 第二次执行的时候,agg上一次的聚合结果[2], curr集合倒数第三个元素[5] (agg,curr)=> agg * curr = -1
// ......
println(result2)
println("+"*100)
//fold(agg第一次执行的初始值)(func: (集合元素类型,集合元素类型)=>集合元素类型)
//fold与reduce唯一的不同就是多了agg的初始值
list17.fold(100)( (agg,curr)=>{
println(s"agg=${agg} curr=${curr}")
agg-curr
})
println("-"*100)
//foldRight(agg第一次执行的初始值)(func: (集合元素类型,集合元素类型)=>集合元素类型)
list17.foldRight(200)( (curr,agg)=>{
println(s"agg=${agg} curr=${curr}")
agg - curr
})
}
案例一word count
object $14_WordCount {
def main(args: Array[String]): Unit = {
val datas = List("Hello Scala Hbase kafka", "Hello Scala Hbase", "Hello Scala", "Hello")
//1、切割句子获取单词,压平
//datas.flatMap(x=>x.split(" "))
val words = datas.flatMap(_.split(" "))
//List(Hello,Scala,Hbase,kafka,Hello,Scala,Hbase,Hello,Scala,Hello)
//2、按照单词进行分组
val grouped = words.groupBy(x=>x)
/**
* Map[
* Hello -> List[Hello,Hello,Hello,Hello],
* Scala-> List[Scala,Scala,Scala],
* Hbase-> List[Hbase,Hbase],
* kafka->List[kafka]
* ]
*/
//3、统计单词的个数
val result = grouped.map(x=>{
//x = Hello -> List[Hello,Hello,Hello,Hello]
val num = x._2.length
(x._1,num)
})
//4、结果展示
result.foreach(println)
//最终结果: [(Hello,4),(Scala,3),(Hbase,2),(Kafka,1)]
// datas.flatMap(_.split(" ")).groupBy(x=>x).map(x=>(x._1,x._2.size)).foreach(println)
}
}
案例二word count
object $15_WordCountHight {
def main(args: Array[String]): Unit = {
val datas = List(("Hello Scala Spark World", 4), ("Hello Scala Spark", 3), ("Hello Scala", 2), ("Hello", 1))
//1、切割句子获得单词,赋予初始次数,压平
val words = datas.flatMap(x=>{
//x = ("Hello Scala Spark World", 4)
val arr = x._1.split(" ")
//Array(Hello,Scala,Spark,World)
val result = arr.map(y=>(y,x._2))
//Array( (Hello,4),(Scala,4),(Spark,4),(World,4) )
result
})
//List( (Hello,4),(Scala,4),(Spark,4),(World,4),(Hello,3),(Scala,3),(Spark,3),(Hello,2),(Scala,2),(Hello,1) )
//2、按照单词分组
val grouped = words.groupBy(_._1)
/**
* Map[
* Hello -> List( (Hello,4),(Hello,3),(Hello,2),(Hello,1) ),
* Scala -> List( (Scala,4),(Scala,3),(Scala,2)),
* Spark-> List( (Spark,4),(Spark,3)),
* World -> List( (World,4))
* ]
*/
//3、统计单词的总个数
val result = grouped.map(x=>{
//x = Hello -> List( (Hello,4),(Hello,3),(Hello,2),(Hello,1) )
//val num = x._2.map(_._2).sum
// (x._1,num)
val result = x._2.reduce((agg,curr)=>(agg._1,agg._2+curr._2 ))
result
})
//List[Hello->10,Scala->9,Spark->7,World->4]
//4、结果展示
result.foreach(println)
}
}
案例三
object $16_Home {
/**
* 1、求出哪些省份没有农产品市场
* 2、获取菜的种类最多的三个省份
* 3、获取每个省份菜的种类最多的三个农贸市场
*/
def main(args: Array[String]): Unit = {
val products = Source.fromFile("datas/product.txt","utf-8").getLines().toList
val allprovince = Source.fromFile("datas/allprovince.txt").getLines().toList
//m1(allprovince,products)
//m2(products)
m3(products)
}
/**
* 获取每个省份菜的种类最多的三个农贸市场
*/
def m3(products:List[String]) = {
//1、过滤非法数据
products.filter(_.split("\t").size==6)
//2、列裁剪- 选择 菜名、省份、农产品市场
.map(line=>{
val arr = line.split("\t")
(arr(4),arr(3),arr(0))
})
//3、去重
.distinct
//4、按照省份、农产品市场分组
.groupBy(x=> (x._1,x._2) )
/**
* Map(
* (湖南省,长沙市马王堆批发市场) -> List( (湖南省,长沙市马王堆批发市场,大白菜),(湖南省,长沙市马王堆批发市场,青椒),... )
* (湖南省,长沙市aa) -> List( (湖南省,长沙市aa,大白菜),(湖南省,长沙市aa,青椒),... )
* ....
* )
*/
//5、统计每个省份、每个农产品市场的菜的种类数
.map(x=>{
//x = (湖南省,长沙市马王堆批发市场) -> List( (湖南省,长沙市马王堆批发市场,大白菜),(湖南省,长沙市马王堆批发市场,青椒),... )
(x._1._1,x._1._2,x._2.size)
})
/**
* List(
* (湖南省,长沙市马王堆批发市场,10)
* (湖南省,长沙市aa,20)
* (湖北省,武汉市bb,30)
* ....
* )
*/
//6、按照省份分组
.groupBy(_._1)
/**
* Map(
* 湖南省 -> List( (湖南省,长沙市马王堆批发市场,10),(湖南省,长沙市aa,20),..)
* 湖北省 -> List( (湖北省,武汉市bb,30),... )
* ....
* )
*/
//7、对每个省份农产品种类数进行排序,取前三
.map(x=>{
//x = 湖南省 -> List( (湖南省,长沙市马王堆批发市场,10),(湖南省,长沙市aa,20),..)
(x._1,x._2.toList.sortBy(_._3).reverse.take(3))
})
//8、结果展示
.foreach(println)
}
/**
* 获取菜的种类最多的三个省份
*/
def m2(products:List[String]) = {
//1、过滤非法数据
products.filter(_.split("\t").length==6)
//2、列裁剪-选择菜名-省份
.map(line=>{
val arr = line.split("\t")
(arr(4),arr(0))
})
//List( ( 湖南省,大白菜),( 湖南省,大白菜),( 湖南省,青椒),...)
//3、去重【每个省份有多个农产品市场可能有多个同名的菜】
.distinct
//List( ( 湖南省,大白菜),( 湖南省,青椒),...)
//4、按照省份分组
.groupBy(_._1)
/**
* Map[
* 湖南省 -> List( ( 湖南省,大白菜),( 湖南省,青椒),...)
* 湖北省 -> List( ( 湖北省,大白菜),( 湖北省,青椒),...)
* ]
*/
//5、统计每个省份的菜的种类数量
.map(x=>{
//x = 湖南省 -> List( ( 湖南省,大白菜),( 湖南省,青椒),...)
(x._1,x._2.size)
})
//List( 湖南省->10,湖北省->5,..)
//6、排序
.toList
.sortBy(_._2)
//List(湖北省->5,湖南省->10,广东省->20,..)
//7、取前三
.reverse
.take(3)
//8、结果展示
.foreach(println)
}
/**
* 1、求出哪些省份没有农产品市场
*/
def m1(allprovince:List[String],products:List[String]) ={
//三要素: 过滤、去重、列裁剪
//1、过滤
val filterProduct = products.filter(line=>line.split("\t").length==6)
//2、获取农产品市场数据的省份
val productProvinces = filterProduct.map(line=> {
line.split("\t")(4)
})
//3、去重
val distincProvince = productProvinces.distinct
//4、将农产品数据省份与全国所有省份对比,得到哪些省份没有农产品市场【求差集】
val result = allprovince.diff(distincProvince)
//5、结果展示
result.foreach(println)
}
}
不可变队列
/**
* 队列的特点: 先进先出
* 创建方式: Queue[集合元素类型](初始元素,...)
* @param args
*/
def main(args: Array[String]): Unit = {
val queue = Queue[Int](10,2,4,1,6)
println(queue)
//添加元素
val queue2 = queue.+:(100)
val queue3 = queue.:+(200)
println(queue2)
println(queue3)
val queue4 = queue.++(List(9,8,7))
val queue5 = queue.++:(List(5,6,7))
println(queue4)
println(queue5)
val queue6 = queue.enqueue(1000)
println(queue6)
//删除元素
val dequeue: (Int, Queue[Int]) = queue.dequeue
println(dequeue)
val option = queue.dequeueOption
println(option)
//修改
val queue7 = queue.updated(1,20)
println(queue7)
}
可变队列
object $18_MutableQueue {
def main(args: Array[String]): Unit = {
//创建方式
val queue = mutable.Queue[Int](10,20,3,5,1)
println(queue)
//添加元素
val queue2 = queue.+:(30)
val queue3 = queue.:+(40)
queue.+=(50)
queue.+=:(60)
println(queue2)
println(queue3)
println(queue)
val queue4 = queue.++(List(1,2,3))
val queue5 = queue.++:(List(4,5,6))
println(queue4)
println(queue5)
queue.++=(List(7,8,9))
println(queue)
queue.enqueue(10,20,30,40)
println(queue)
//删除元素
println(queue.dequeue())
println(queue)
//修改
queue.update(0,20)
println(queue)
}
}
开启多线程
object $19_ParCollection {
def main(args: Array[String]): Unit = {
val list = List[Int](14,1,6,9,10,20,7,8)
list.foreach(x=>println(Thread.currentThread().getName))
println("8"*100)
list.par.foreach(x=>println(Thread.currentThread().getName))
}
}
模式匹配
object $01_MatchDefind {
/**
* 语法: 变量 match {
*
* case 值1 => {
* .....
* }
* case 值2 => {
* ...
* }
* .....
* }
*
* 模式匹配可以有返回值,返回值是符合条件的分支的{}的最后一个表达式的结果值
*
*/
def main(args: Array[String]): Unit = {
val word = StdIn.readLine("请输入一个单词:")
val result = word match {
case "hadoop" =>
println("输入的单词是hadoop")
10
case "spark" =>
println("输入的单词是spark")
20
case "flume" =>
println("输入的单词是flume")
30
//相当于switch的default
/* case x => {
println(s"其他单词${x}")
}*/
//如果变量不需要在=>右边使用可以用_代替
case _ => {
println(s"其他单词")
-1
}
}
println(result)
}
}
守卫
object $02_MatchIf {
/**
* 守卫语法:
* 变量 match {
* case 值 if(布尔表达式) => ...
* case 值 if(布尔表达式) => ...
* }
*/
def main(args: Array[String]): Unit = {
val line = StdIn.readLine("请输入一句话:")
line match {
case x if(x.contains("hadoop")) => println(s"输入的句子中包含hadoop")
case x if(x.contains("spark")) => println(s"输入的句子中包含spark")
case x if(x.contains("flume")) => println(s"输入的句子中包含flume")
case x => println("其他句子")
}
}
}
匹配值
object $03_MatchValue {
def main(args: Array[String]): Unit = {
val arr = Array("spark",1,2.0,false,30)
val index = Random.nextInt(arr.length)
val value:Any = arr(index)
println(value)
value match {
case 1 => println("........1")
case 2.0 => println("........2.0")
case "spark" => println("........spark")
case false => println("..........false")
case _ => println("其他")
}
}
}
匹配类型
/**
* 匹配语法: 变量 match{
* case 变量名:类型 => ...
* case 变量名:类型 => ..
* case _:类型 => .. //如果变量名不需要在=>右边使用可以用_代替
* ...
* }
*/
def main(args: Array[String]): Unit = {
val list:List[Any] = List(1,2.0,false,10,"spark")
val index = Random.nextInt(list.length)
val value = list(index)
println(value)
val result = value match {
case _:String => "输入的是字符串"
case x:Int => s"输入的是整数${x}"
case _:Double => "输入的是浮点型"
case _:Boolean => "输入的是布尔"
case _ => "其他"
}
println(result)
}
匹配数组
object $05_MatchArray {
def main(args: Array[String]): Unit = {
//val arr:Array[Any] = Array(4,1,10,2,7)
val arr:Array[Any] = Array("spark",1,2.0)
arr match {
//匹配数组只有一个元素
case Array(x) => println(s"数组只有一个元素${x}")
//匹配数组只有三个元素,匹配元素的类型
case Array(x:String,y:Int,z:Double) => println("匹配数组有三个元素,并且元素类型分别为String,Int,Double")
//匹配数组有三个元素
case Array(x,y,z) => println(s"数组有三个元素${x},${y},${z}")
//匹配数组至少有一个元素
case Array(_,_*) => println("数组至少有一个元素")
}
// int[] arr = new int[] {}
// object[] arr = new object[] {}
// String[] arr = new String[] {}
arr match {
//case x:Array[Int] => println("arr是Int数组")
case x:Array[Any] => println("arr是Any数组")
//case x:Array[String] => println("arr是String数组")
}
}
}
list匹配
object $06_MatchList {
def main(args: Array[String]): Unit = {
val list = List[Int](1,2,7,9,10)
//val list = List[Any]("spark",1,2.0)
//第一种匹配方式
list match {
//匹配List只有一个元素
case List(x) => println("List只有一个元素")
//匹配List有三个元素,以及匹配元素的类型
//case List(x:String,y:Int,z:Double) => println("list中有三个元素,并且元素类型为string,int,double")
//匹配List有三个元素
case List(x,_,z) => println("List有三个元素")
//匹配List至少有一个元素
case List(x,_*) => println("List至少有一个元素")
}
println("*"*100)
list match {
//匹配List只有一个元素
case x :: Nil => println("List只有一个元素")
//匹配List有三个元素,以及匹配元素的类型
//case (x:String) :: (y:Int) :: (z:Double) :: Nil => println("list中有三个元素,并且元素类型为string,int,double")
//匹配List有三个元素
case x :: _ :: z :: Nil => println("List有三个元素")
//匹配List至少有一个元素
case x :: y :: aaa => println(s"List至少有一个元素,${x} ${aaa}")
}
println("*"*100)
//泛型的特点: 泛型擦除,泛型只是编译器使用,用来规定集合里面的数据类型是啥,真正在编译的时候jvm虚拟机会将泛型擦掉
list match {
case x:List[String] => println("string list")
case x:List[Any] => println("any list")
case x:List[Int] => println("int list")
case _ => println("其他list")
}
}
}
匹配元组
object $07_MatchTuple {
def main(args: Array[String]): Unit = {
val t1 = ("zhangsan",20,"shenzhen")
//元组在匹配的时候,元组的元素的个数必须与匹配条件的元组的元素个数一致
val name = "zhangsan"
t1 match{
case (x:String,y:Int,z:String) => println(".........")
case (x,y,z) => println(s"${x} ${y} ")
// case (x,y) => println(s"${x} ${y} ${z}")
}
val schools = List[(String,(String,(String,Int)))](
("宝安中学",("大数据1班",("zhangsan",20))),
("宝安中学",("大数据1班",("lisi",20))),
("宝安中学",("大数据1班",("wangwu",20))),
("宝安中学",("大数据1班",("zhaoliu",20)))
)
//schools.map(x=> x._2._2._1 ).foreach(println)
schools.map(x=> {
x match {
case (schoolName,(className,(stuName,age))) => stuName
}
} ).foreach(println)
}
}
匹配样例类
object $08_MatchCaseClass {
//样例类
case class Person(name:String,var age:Int)
/* class Student(val name:String ,var age:Int)
object Student{
def apply(name:String,age:Int) = new Person(name,age)
}*/
case class School(name:String,clazz:Clazz)
case class Clazz(name:String,stu:Student)
case class Student(name:String,age:Int)
abstract class Sex
case object Man extends Sex
case object Woman extends Sex
def xx(sex:Sex): Unit ={
}
class Animal(val name:String,val age:Int)
object Animal{
def unapply(arg: Animal): Option[(String, Int)] = {
if(arg==null){
None
}else{
Some((arg.name,arg.age))
}
}
}
/**
* 样例类: case class 类名(val/var 属性名:属性类型,....)
* val修饰的属性不可变
* var修饰的属性可变
* val/var可以省略不写,如果省略默认就是val修饰的
* 样例创建对象: 类名(属性值,..)
*
* 样例对象: case object object名称
*样例对象一般作为枚举使用。
* @param args
*/
def main(args: Array[String]): Unit = {
//对象创建
val person = Person("zhangsan",20)
println(person)
println(person.name)
println(person.age)
//val student = Student("lisi",30)
//println(student.name)
val schools = List[School](
School("宝安中学",Clazz("大数据1班",Student("zhangsan",20))),
School("宝安中学",Clazz("大数据1班",Student("lisi",20))),
School("宝安中学",Clazz("大数据1班",Student("wangwu",20))),
School("宝安中学",Clazz("大数据1班",Student("zhaoliu",20)))
)
schools.map(x=>x.clazz.stu.name).foreach(println)
xx(Man)
person match {
case Person(x,y) => println(s"${x} ${y}")
}
val wangcai = new Animal("wangcai",5)
wangcai match {
case Animal(x,y) => println(s"${x} ${y}")
}
}
}
匹配参数
object $09_MatchParamDefind {
def main(args: Array[String]): Unit = {
val t1 = ("zhangsan",20,"shenzhen")
println(t1._1)
val (name,age,address) = ("zhangsan",20,"shenzhen")
println(name)
val x :: Nil = List(10)
println(x)
val Array(a,y,z) = Array(10,20,30)
println(a,y,z)
val name1:String = "zhangsan"
println(name)
val list = List[(String,Int)](("zhangsan",20),("lisi",30))
for((name,age)<- list){
println(name)
}
}
}
偏函数
/**
* 偏函数: 没有match关键字的模式匹配称之为偏函数
* 语法: val 函数名:PartialFunction[IN,OUT] = {
* case 条件1 =>...
* case 条件2 => ..
* ...
* }
* IN: 代表函数的参数类型
* OUT: 函数的返回值类型
* @param args
*/
def main(args: Array[String]): Unit = {
val func:PartialFunction[String,Int] = {
case "hadoop" =>
println("hadoop......")
10
case "spark" =>
println("spark..........")
20
case _ =>
println("其他.......")
-1
}
println(func("hadoop"))
val schools = List[(String,(String,(String,Int)))](
("宝安中学",("大数据1班",("zhangsan",20))),
("宝安中学",("大数据1班",("lisi",20))),
("宝安中学",("大数据1班",("wangwu",20))),
("宝安中学",("大数据1班",("zhaoliu",20)))
)
//schools.map(_._2._2._1).foreach(println(_))
/*schools.map(x=>{
x match {
case (schoolName,(className,(stuName,age))) =>stuName
}
}).foreach(println(_))*/
val getStuName:PartialFunction[(String,(String,(String,Int))),String] = {
case (schoolName,(className,(stuName,age))) => stuName
}
//schools.map(getStuName).foreach(println(_))
//偏函数使用的正确姿势
schools.map{
case (schoolName,(className,(stuName,age))) => stuName
}.foreach(println(_))
}
异常
object $01_Exception {
/**
* java中关于的异常的处理:
* 1、捕获异常: try{} catch{} finally{}
* try{
* ...
* }catch(Exception e){
* ..
* }finally{ --用于释放资源
* ..
* }
* 2、抛出异常: throw new ..Exception [必须在方法上throws Exception]
* scala中关于异常处理:
* 1、捕获异常:
* 1、try{} catch{} finally{} 【一般用于获取外部资源的时候使用】
* 2、Try(代码).getOrElse(代码执行失败返回的默认值)
* Success: 代表Try中包裹的代码执行成功,后续可以通过get方法取出代码的执行结果
* Filture: 代表Try中包裹的代码执行失败
* 2、抛出异常: throw new ..Exception [scala抛出异常不需要在方法后面通过throws Exception声明]
* @param args
*/
def main(args: Array[String]): Unit = {
//println(m1(10, 0))
println(m2(10,0))
val list = List[String](
"1 zhangsan 20 shenzhen",
"2 lisi beijing",
"3 lisi tianjin",
"4 zhaoliu 55 shenzhen"
)
//需求: 求年龄总和
list.map(line=>{
val age = Try(line.split(" ")(2).toInt).getOrElse(-1)
age
}).filter(_!= -1).foreach(println(_))
}
def m1(x:Int,y:Int) = {
if(y==0) throw new Exception("y=0")
x/y
}
def m2(x:Int,y:Int) = {
try{
x/y
}catch {
case e:Exception => println("y=0")
}
}
def jdbc() = {
var connection:Connection = null
var statement:PreparedStatement = null
try{
//1、获取连接
connection = DriverManager.getConnection("jdbc:mysql://hadoop102:3306/test")
//2、创建statement对象
statement = connection.prepareStatement("insert into person values(?,?,?)")
//3、封装参数
statement.setString(1,"zhangsan")
statement.setString(3,"shenzhen")
statement.setInt(2,20)
//4、执行
statement.executeUpdate()
}catch {
case e:Exception=>
}finally {
//5、关闭
if(statement!=null)
statement.close()
if(connection!=null)
connection.close()
}
}
}
either
object $02_Either {
def main(args: Array[String]): Unit = {
val either = m1(10,0)
either match {
case Left(result) =>
println(s"失败.....${result}")
case Right(result) =>
println(s"成功......${result}")
}
}
def m1(x:Int,y:Int) = {
try{
Right(x/y)
}catch {
case e:Exception => Left((y,e))
}
}
}
案例
object $03_Home {
def main(args: Array[String]): Unit = {
val datas = Source.fromFile("datas/aa","utf-8").getLines().toList
//1、切割(司机、区域、时间[转成时间戳])
datas.map(line=>{
//line="A 龙华区 宝安区 2020-07-15 10:05:10 2020-07-15 10:25:02"
val arr = line.split("\t")
val id = arr.head
val fromAddr = arr(1)
val toAddr = arr(2)
val fromTime = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss").parse(arr(3)).getTime
//LocalDateTime.parse(fromTime,DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss"))
val toTime = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss").parse(arr(4)).getTime
(id,fromAddr,toAddr,fromTime,toTime)
})
//2、按照司机分组
.groupBy(_._1)
/**
* Map(
* A-> List(
* (A,龙华区,宝安区,2020-07-15 10:05:10,2020-07-15 10:25:02),
* (A,龙岗区,宝安区,2020-07-15 11:55:55,2020-07-15 12:12:23),
* (A,龙岗区,龙华区,2020-07-15 11:02:08,2020-07-15 11:17:15),
* (A,宝安区,龙岗区,2020-07-15 10:35:15,2020-07-15 10:40:50),
* (A,龙华区,龙岗区,2020-07-15 11:33:12,2020-07-15 11:45:35),
* (A,宝安区,龙岗区,2020-07-15 12:17:10,2020-07-15 12:33:21)
* )
* B-> List(
* (B,宝安区,福田区,2020-07-15 11:43:22 2020-07-15 11:55:45),
* (B,福田区,宝安区,2020-07-15 12:05:05 2020-07-15 12:22:33),
* (B,龙华区,龙岗区,2020-07-15 10:45:25 2020-07-15 10:50:00),
* (B,宝安区,龙岗区,2020-07-15 12:27:20 2020-07-15 12:43:31),
* (B,福田区,龙华区,2020-07-15 10:15:21 2020-07-15 10:35:12),
* (B,龙岗区,宝安区,2020-07-15 11:12:18 2020-07-15 11:27:25)
* )
* )
*/
.toList
//3、对每个司机的数据按照上车/下车时间排序
.flatMap(x=>{
//x= A-> List(
// (A,龙华区,宝安区,2020-07-15 10:05:10,2020-07-15 10:25:02),
// (A,龙岗区,宝安区,2020-07-15 11:55:55,2020-07-15 12:12:23),
// (A,龙岗区,龙华区,2020-07-15 11:02:08,2020-07-15 11:17:15),
// (A,宝安区,龙岗区,2020-07-15 10:35:15,2020-07-15 10:40:50),
// (A,龙华区,龙岗区,2020-07-15 11:33:12,2020-07-15 11:45:35),
// (A,宝安区,龙岗区,2020-07-15 12:17:10,2020-07-15 12:33:21)
// )
val list = x._2.sortBy(_._4)
// List(
// (A,龙华区,宝安区,2020-07-15 10:05:10,2020-07-15 10:25:02),
// (A,宝安区,龙岗区,2020-07-15 10:35:15,2020-07-15 10:40:50),
// (A,龙岗区,龙华区,2020-07-15 11:02:08,2020-07-15 11:17:15),
// (A,龙华区,龙岗区,2020-07-15 11:33:12,2020-07-15 11:45:35),
// (A,龙岗区,宝安区,2020-07-15 11:55:55,2020-07-15 12:12:23),
// (A,宝安区,龙岗区,2020-07-15 12:17:10,2020-07-15 12:33:21)
//)
val slidingList = list.sliding(2)
/**
* List(
* List((A,龙华区,宝安区,2020-07-15 10:05:10,2020-07-15 10:25:02),(A,宝安区,龙岗区,2020-07-15 10:35:15,2020-07-15 10:40:50)),
* List((A,宝安区,龙岗区,2020-07-15 10:35:15,2020-07-15 10:40:50),(A,龙岗区,龙华区,2020-07-15 11:02:08,2020-07-15 11:17:15)),
* List((A,龙岗区,龙华区,2020-07-15 11:02:08,2020-07-15 11:17:15),(A,龙华区,龙岗区,2020-07-15 11:33:12,2020-07-15 11:45:35)),
* List((A,龙华区,龙岗区,2020-07-15 11:33:12,2020-07-15 11:45:35),(A,龙岗区,宝安区,2020-07-15 11:55:55,2020-07-15 12:12:23)),
* List((A,龙岗区,宝安区,2020-07-15 11:55:55,2020-07-15 12:12:23),(A,宝安区,龙岗区,2020-07-15 12:17:10,2020-07-15 12:33:21)),
*
* )
*/
//4、计算每个司机每次的等客时间
val result = slidingList.map(y=>{
//y = List((A,龙华区,宝安区,2020-07-15 10:05:10,2020-07-15 10:25:02),(A,宝安区,龙岗区,2020-07-15 10:35:15,2020-07-15 10:40:50)),
//等客区域
val region = y.head._3
//等客时间 = 下一次的上车时间 - 上一次下车时间
val duration = y.last._4 - y.head._5
(region,duration)
})
result
})
//List( (宝安区,10),(龙岗区,22),(龙华区,16),(龙岗区,10),(宝安区,5) ,(龙华区,10),(龙岗区,22),(宝安区,16),(福田区,10),(宝安区,5))
//6、按照区域分组
.groupBy(_._1)
/**
* Map(
* 宝安区-> List((宝安区,10),(宝安区,5),(宝安区,16),(宝安区,5))
* ....
* )
*/
//7、计算平均等客时间
.map(x=>{
//x = 宝安区-> List((宝安区,10),(宝安区,5),(宝安区,16),(宝安区,5))
val time = x._2.map(_._2).sum
val count = x._2.size
(x._1,time/count/1000)
})
//8、结果展示
.foreach(println(_))
}
}
隐式转换
import java.io.File
import scala.io.{BufferedSource, Source}
object xx{
implicit def fileToSourceBufferd(file:File):BufferedSource = {
Source.fromFile(file,"utf-8")
}
implicit def doubeToInt1(x:Double):Int = x.toInt
implicit def doubeToInt2(x:Double):Int = x.toInt + 10
}
object $01_ImplicitMethod{
/**
* 隐式方法: 悄悄将一个类型转成另一个类型
* 语法: implicit def 方法名(变量名:待转换类型): 目标类型 = {..}
*隐式转换方法使用时机:
* 1、当前类型与目标类型不一致的时候,会自动调用隐式方法
* 2、当对象使用了不属于自身的属性/方法/函数的时候,会自动调用隐式方法
*隐式转换的解析:
* 当需要使用隐式转换的时候,后首先从当前的作用域中查找是否有符合条件的隐式转换
* 如果说隐式转换不在当前作用域,需要进行导入之后再使用:
* 1、如果隐式转换定义在Object中,导入的时候使用: import 包名.object名称.隐式转换方法名
* 2、如果隐式转换定义在class中,导入的时候使用:
* 1、创建对象
* 2、对象名.隐式转换方法名
* @param args
*/
def main(args: Array[String]): Unit = {
// 1、当前类型与目标类型不一致的时候,会自动调用隐式方法
//val abc = new xx
import xx.doubeToInt1
val a:Int = 2.0
println(a)
val file = new File("d:/pmt.json")
//2、当对象使用了不属于自身的属性/方法/函数的时候,会自动调用隐式方法
import xx.fileToSourceBufferd
file.getLines()
}
}
隐式转换参数
object AA{
implicit val y:Int = 10
implicit val a:Int = 100
}
object $02_ImplicitParam {
/**
* 隐式转换参数的语法:
* 1、通过implicit val 变量名:类型 = 值
* 2、def 方法名(..)(implicit 变量名:类型)
* 如果有多个隐式转换参数/方法都符合要求,需要明确通过import 包名.隐式参数名/方法名的方式指定使用哪个隐式转换参数/方法
* @param args
*/
def main(args: Array[String]): Unit = {
import AA.a
println(m1(20))
}
def m1(x:Int)(implicit y:Int) = x+y
隐式转换类
object $03_ImplicitClass {
class Person(val name:String,val age:Int)
implicit class MaxMin(p:Person){
def max(p1:Person) = {
if(p.age<p1.age) p1
else p
}
}
/**
* scala隐式转换类在2.10版本之后才有
* 语法: implicit class 类名(属性名: 待转换的类型) {
* ...
* }
* @param args
*/
def main(args: Array[String]): Unit = {
val person1 = new Person("zhagnsan",20)
val person2 = new Person("lisi",30)
person1.max(person2)
}
//implicit def personToMaxMin(p:Person ):MaxMin = new MaxMin(p)
}
泛型方法
/**
* 泛型主要用于方法与类
* 泛型方法的定义语法: def 方法名[T,U](x:T):U = {..}
*/
def main(args: Array[String]): Unit = {
println(m1[Int](Array[Int](1, 2, 3)))
}
def m1[T](x:Array[T]):Int = {
x.length
}
泛型类
object $02_GenericClass {
class Person[T,U](var name:T,var age:U) {
def setName(name:T) = this.name=name
def getName():T = this.name
}
/**
* 泛型类的定义语法: class 类名[T,U](val/var 属性名:T,..) {
*
* def 方法名(参数名:U):返回值类型 = {..}
* }
* @param args
*/
def main(args: Array[String]): Unit = {
val person = new Person[String,Int]("zhangsan",20)
person.setName("lisi")
println(person.getName())
}
}
泛型上下限
/**
* 上下限:
* 上限【代表传入的泛型必须是指定类型或者是其子类】: T <: 指定类型
* 下限 【代表传入的类型必须是指定类型或者是其父类】 : T >: 指定类型
* @param args
*/
def main(args: Array[String]): Unit = {
//m1(new BigBigDog)
val big:Any = new BigBigDog
m2(1)
}
class Animal
class Dog extends Animal
class BigDog extends Dog
class BigBigDog extends BigDog
def m1[T<:Dog](x:T) = {
println(x)
}
def m2[U>:BigDog](x:U) = {
println(x)
}
泛型 非变、协变、逆变
object $04_GenericChange {
class Parent
class Sub1 extends Parent
class Sub2 extends Sub1
//class AA[T]
//class AA[+T]
class AA[-T]
/**
* 非变: 泛型有父子关系,但是泛型对象没有任何关系 T
* 协变: 泛型有父子关系,泛型对象继承了泛型的父子关系 +T
* 逆变: 泛型有父子关系,泛型对象颠倒了泛型的父子关系 -T
* @param args
*/
def main(args: Array[String]): Unit = {
var list1 = List[B](new B,new B)
var list2 = List[B1](new B1,new B1)
list1 = list2
println(list1)
//非变
//var aa1 = new AA[Parent]
//var aa2 = new AA[Sub1]
//aa1 = aa2
//协变
//var aa1 = new AA[Parent]
//var aa2 = new AA[Sub1]
//aa1 = aa2
//println(aa1)
//逆变
var aa1 = new AA[Parent]
var aa2 = new AA[Sub1]
aa2 = aa1
println(aa2)
}
class B
class B1 extends B
}
泛型上下文
/**
* 泛型上下文语法: def 方法名[T:类型](参数名:T) = {
* val 变量名 = implicitly[类型[T]]
* ....
* }
* @param args
*/
def main(args: Array[String]): Unit = {
implicit val p = new Person[String]
f[String]("zhangsan")
f[String]("lisi")
}
class Person[U]{
var field:U = _
def printHello = println("hello.....")
def setField(field:U) = this.field = field
}
def f[A](a:A)(implicit person:Person[A])= {
person.setField(a)
person.printHello
}
def f1[A:Person](a:A) = {
val person = implicitly[Person[A]]
person.setField(a)
person.printHello
}
案例分析
需求: 统计每个用户一小时内的最大登录次数
user_id,login_time
a,2020-07-11 10:51:12
a,2020-07-11 11:05:00
a,2020-07-11 11:15:20
a,2020-07-11 11:25:05
a,2020-07-11 11:45:00
a,2020-07-11 11:55:36
a,2020-07-11 11:59:56
a,2020-07-11 12:35:12
a,2020-07-11 12:58:59
b,2020-07-11 14:51:12
b,2020-07-11 14:05:00
b,2020-07-11 15:15:20
b,2020-07-11 15:25:05
b,2020-07-11 16:45:00
b,2020-07-11 16:55:36
b,2020-07-11 16:59:56
b,2020-07-11 17:35:12
b,2020-07-11 17:58:59
import java.text.SimpleDateFormat
import scala.io.Source
object $01_Home {
/**
* 需求: 统计每个用户一小时内的最大登录次数
* @param args
*/
def main(args: Array[String]): Unit = {
//1、读取数据
val datas = Source.fromFile("datas/datas.txt","utf-8").getLines().toList
//2、切割数据,转换时间
val mapDatas = datas.map(line=>{
val arr = line.split(",")
val userID = arr.head
val time = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss").parse(arr.last).getTime
(userID,time)
})
//3、遍历数据,根据遍历的每条数据筛选哪些数据与该数据处于一个小时
mapDatas.map(x=>{
//x = (a,2020-07-11 10:51:12)
//4、统计每个时间对应的登录次数
val num = mapDatas.filter(y=>y._1 == x._1 && y._2>=x._2 && y._2<=x._2+3600000).size
(x._1,num)
})
//5、按照用户进行分组
.groupBy(_._1)
/**
* Map(
* a-> List( (a,5),(a,6),(a,4),..)
* b-> List( (b,4),..)
* )
*/
//6、统计最大登录次数
.map(x=>{
//x=a-> List( (a,5),(a,6),(a,4),..)
x._2.maxBy(_._2)
})
//7、结果展示
.foreach(println(_))
}
}
案例分析二
val list = List[(String,String,String)](
("1001","2020-09-10 10:21:21","home.html"),
("1001","2020-09-10 10:28:10","good_list.html"),
("1001","2020-09-10 10:35:05","good_detail.html"),
("1001","2020-09-10 10:42:55","cart.html"),
("1001","2020-09-10 11:35:21","home.html"),
("1001","2020-09-10 11:36:10","cart.html"),
("1001","2020-09-10 11:38:12","trade.html"),
("1001","2020-09-10 11:40:00","payment.html"),
("1002","2020-09-10 09:40:00","home.html"),
("1002","2020-09-10 09:41:00","mine.html"),
("1002","2020-09-10 09:42:00","favor.html"),
("1003","2020-09-10 13:10:00","home.html"),
("1003","2020-09-10 13:15:00","search.html")
)
//需求: 分析用户每次会话的行为轨迹
import java.text.SimpleDateFormat
import java.util.UUID
case class UserAnasisy(var sessionid:String,userid:String,time:Long,page:String)
object $02_Home {
def main(args: Array[String]): Unit = {
val list = List[(String,String,String)](
("1001","2020-09-10 10:21:21","home.html"),
("1001","2020-09-10 10:28:10","good_list.html"),
("1001","2020-09-10 10:35:05","good_detail.html"),
("1001","2020-09-10 10:42:55","cart.html"),
("1001","2020-09-10 11:35:21","home.html"),
("1001","2020-09-10 11:36:10","cart.html"),
("1001","2020-09-10 11:38:12","trade.html"),
("1001","2020-09-10 11:40:00","payment.html"),
("1002","2020-09-10 09:40:00","home.html"),
("1002","2020-09-10 09:41:00","mine.html"),
("1002","2020-09-10 09:42:00","favor.html"),
("1003","2020-09-10 13:10:00","home.html"),
("1003","2020-09-10 13:15:00","search.html")
)
// 每条数据都给一个唯一标识,进行数据转换
list.map(x=>{
val sessionid = UUID.randomUUID().toString
val time = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss").parse(x._2).getTime
UserAnasisy(sessionid,x._1,time,x._3)
})
//分组
.groupBy(_.userid)
/**
* Map(
* 1001-> List(UserAnasisy("1","1001","2020-09-10 10:21:21","home.html"),UserAnasisy("2","1001","2020-09-10 10:28:10","good_list.html"),UserAnasisy...)
* 1002-> List(...)
* )
*/
//按照时间排序
.flatMap(x=>{
val sortedUser = x._2.sortBy(_.time)
//窗口
val slidingList = sortedUser.sliding(2)
/**
* List(
* List(UserAnasisy("1","1001","2020-09-10 10:21:21","home.html"),UserAnasisy("2","1001","2020-09-10 10:28:10","good_list.html"))
* List(UserAnasisy("2","1001","2020-09-10 10:28:10","good_list.html"),UserAnasisy ("3","1001","2020-09-10 10:35:05","good_detail.html"))
* ...
* )
*/
slidingList.foreach(y=>{
//y = List(UserAnasisy("1","1001","2020-09-10 10:21:21","home.html"),UserAnasisy("2","1001","2020-09-10 10:28:10","good_list.html"))
//判断上一次与下一次是否在30分钟内,如果在30分钟内就是属于同一次会话
if(y.last.time - y.head.time < 30*60*1000) {
y.last.sessionid = y.head.sessionid
}
})
x._2
})
//结果展示
.foreach(println(_))
}
}
案例分析三