OSS加速器最佳实践(总述篇)
本最佳实践提供OSS加速器相关的信息和适合的场景,面向对oss和数据湖相关技术有一定了解的开发者。
大家可以通过这俩篇先做一些了解相关文档:
《配置OSS加速器》https://help.aliyun.com/document_detail/190726.html
《OSS加速器介绍》https://developer.aliyun.com/article/780254
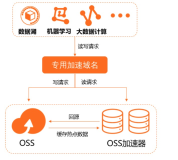
OSS加速器提供AZ(可用区)级的对象下载加速服务,目前已经上线杭州-J,上海-G,北京-H三个可用区,正在白名单申请使用阶段。其用于为AliyunECS/EMR等内部集群的大数据计算场景提供服务(不单独对公网访问服提供务,需要使用Aliyun ECS或Aliyun EMR等基于Aliyun的弹性计算服务来访问)。
OSS加速器面向使用OSS为底座作为数据底座的基因训练、机器学习、数据湖大数据计算等大量数据需要load以及数据重复读较多的场景;其能够提供低延时,高吞吐的数据下载服务。
以10MB的对象多次下载测试,统计其响应延迟(单位ms)分位数,结果显示能降低10倍延迟。

OSS加速器在OSS对象存储的基础上提供更低的延时,特别适合对下载数据延时比较敏感的业务,其基本特性如下:
1) 极致吞吐能力 OSS加速器有效解决多种应用场景(比如数据湖等)的读吞吐的挑战,特别是重复读的场景,其能够每TB提供200MBps(Byte)的吞吐能力,线性扩展,最高可以交付Tbps的带宽交付能力。 2)弹性伸缩 通常计算任务有周期性需求,如何有效避免资源浪费,提效降本,通过OSS加速器的弹性伸缩能力,能够在线进行扩容缩容,可以按需释放或提升资源,有效降低TCO。OSS加速器提供秒级调整配额的弹性能力:对于批任务,一般下载流量都有波峰,对于下载任务带宽波峰特别突出的情况,OSS加速器提供极大的弹性扩缩容能力,可以提供秒级扩缩容量(数十T到数百T)和带宽(数Gb到上百Gb)配额的能力,使用者可以在任务启动前扩大配额,任务完成后缩小配额,节约日常使用成本。 3)存算分离 OSS加速器满足计算资源和存储资源解耦,面对计算任务的多样化,不再需要多个自建缓存搭建匹配,存算分离,灵活选择引擎和版本,满足多业务场景的吞吐加速。 4)数据一致 同时,基于OSS智能元数据架构,OSS加速器提供了传统缓存方案不具备的一致性,当OSS上文件被更新时,加速器能自动识别,确保引擎读取到的都是最新数据。
在以前的oss使用场景中,通常都是通过客户端缓存数据来提供数据的低延迟加速,但是客户端缓存有其不足:
-
客户端空间有限:客户端缓存需要使用客户端的内存或者磁盘,空间有限,无法存放很多数据。在一些面向数据表加速的场景下,需要加载数 TB 至数十 TB 的缓存数据用户分析,明显超过客户端缓存的能力。
-
建设复杂度高:为了突破空间限制,需要客户部署更加复杂的集群缓存系统,然后将 oss 数据搬迁进去。这里就涉及到不同系统间的数据移动,大大增加系统复杂度和建设成本。
-
数据一致性难以解决:如何在客户端缓存或服务端的数据修改后,避免数据不一致,这是一个很难解决好的问题。
OSS加速器提供的是服务端加速的能力:
-
继承了 OSS 海量数据存储的优点,能提供数 TB 至数百 TB 的缓存空间 ,能够直接缓存下数仓中的多个表或者分区
-
不需要客户端做任何额外系统的部署,即可享受数据加速的效果。
-
缓存数据一致性:当 OSS 上文件被更新时,加速器能自动识别,确保引擎读取到的都是最新数据。 OSS 加速器由于不存在一致性的问题,所以只提供 3 种预热策略(反观 Alluxio 等客户端缓存系统,需要提供数十种缓存策略来权衡一致性的问题):
-
写时预热:数据写入时同步预热
-
读时预热:数据读取时未命中加速器,将其预热到缓存集群
-
异步预热:通过命令触发批量预热(开发中)
当然客户端缓存和服务端加速并不是冲突的,我们也可以使用客户端缓存+OSS加速器来构建多级缓存,做到极致加速。

1简单使用
OSS加速器的的API使用方式同OSS相同,使用上只需要替换OSS标准域名为加速域名(OSS加速器和OSS 使用相同的SDK)。
这种用法只是修改一下endpoint即可,上传下载都是使用ossClient初始化时的加速域名,对于上传和非热数据的下载也走了加速路径,会造成客户成本浪费。我们下面介绍一下数据分流读写的方式。
2 数据分流
这里介绍使用API进行读写数据分流的方法。即将发布的新版OSSJavaSDK各种操作都支持单独设置endpoint.
使用者可以在其上定制自己的上传下载数据分离逻辑,甚至做到对不同的下载路径进行再分流,让普通数据走oss机器,只有热数据走oss加速集群,这样可以极大的减少客户的使用成本。
这里我们使用两个endpont来做上传下载数据的分流。

-
oss-cn-beijing.aliyuncs.com用来接收上传数据和下载普通数据(normal_data/*)
-
oss-cache-cn-beijing-h.aliyuncs.com用来获取需要加速的热数据(hot_data/*)。
-
低延时数据共享

需求背景:客户在货柜上购买物品,先通过手机app扫描货柜的货物拍照上传,后台服务接收到图片后通过oss加速器进行存储,后台的子系统随后进行内容安全分析和图片上条码的识别,条码识别后的结果反馈到应用进行扣费等操作。下载图片需要ms级完成,速度要越快越好,才能给客户更快的响应速度和体验。
解决方案:采用OSS加速器写时预热的模式。这个场景下面,对客户上传的图片分析会影响到整个交易链路的延时,时间越短约好,这里使用oss加速器能将分析系统加载图片的延时极大的降低,缩短整个交易链路。
OSS加速器适合对延时敏感,有多次重复读的业务。
-
大数据分析

需求背景:公司的业务数据按照天分区,归档到OSS作为长久的数据存储,,公司分析人员使用hive或spark等计算引擎对数据进行分析,但不确定查询范围,需要尽量减少查询分析时间。
解决方案:使用加速器读时预热的模式。这个场景下面,由于是离线查询,数据量大,并且不确定查询的具体范围,无法做到准确预热,所以读时预热是最合适的。A分析人员查询过的数据,数据会缓存在加速集群,B分析人员查询的数据含有A查过的数据,那么访问就会更加快速。
数据量查询范围不确定,数据量又很大,可以使用加速器读时预热模式,加速分析业务。
-
模型训练(异步预热开发中)

需求背景:模型训练需要拉取训练数据集,将数据从oss加载到训练机器时间长,导致加载数据时计算资源利用率不高。特别是有多个训练任务,都会用相同的数据集,那么多次加载又是漫长的过程。
解决方案:这个场景下,需要加载的数据是提前知道的,我们可以使用OSS异步预热,这样在真正执行训练时就能减少数据加载的时间。多个训练任务使用同样的数据集也能享受到加速效果。对于批任务,一般下载流量都有波峰,对于下载任务带宽波峰特别突出的情况,OSS加速器提供极大的弹性扩缩容能力,可以提供秒级修改容量和带宽配额的能力,使用者可以在任务启动前扩大配额,任务完成后缩小配额,节约使用者日常使用成本。
OSS加速器弹性能力强,能做到秒级配额调整,异步预热模式适合数据量大,范围能确定的分析任务。
-
多级加速
客户端缓存和服务端加速并不是冲突的,根据业务情况合理的结合使用能够达到多级加速的效果。这里我们以Alluxio/jindofs+OSS加速器为例子来说明其结合的优势。

需求背景:结合客户端内存缓存的高性能和OSS加速器的大容量特性,将加速效果达到极致。
解决方案:Alluxio/jindofs推荐co-locate部署形式,和计算集群并置在一起,更加突出其和计算结合的高性能特性。OSS加速设置为读时预热模式。
读取数据时,当Alluxio中缓存未命中时,其会从后端存储来取数据。对于OSS加速器,采用读时预热,其会在第一次获取数据是进行预热。由于客户端主机缓存空间的限制,在alluxio中每个文件和目录都会设置TTL,当TTL到期后缓存会被淘汰,以便节约空间;此时OSS加速器中的数据并不会马上淘汰,其缓存空间可以存放数百TB的数据。当再次用到alluxio未命中的数据时,就可以直接从加速器加载,做到两级加速,达到极致的加速效果。
OSS加速器可以和客户端缓存搭配使用,做到极致性能。