什么是数据库设计?
数据库设计(Database Design)是指对于一个给定的应用环境,构造最优的数据库模式,建立数据库及其应用系统,使之能够有效地存储数据,满足各种用户的应用需求(信息要求和处理要求)。在数据库领域内,常常把使用数据库的各类系统统称为数据库应用系统。
无论是应用程序,还是数据库如何变化,数据始终是最重要的部分。通常,数据是系统存在的首要目的。所以数据库设计就要考虑他的健壮性和可扩展性,数据库设计是根据客户具体的应用的需求,需要的数据库做出额一系列设计。
学完本文后,您将能够:
- 描述数据模型的特点和用途;
- 列举数据模型的类型;
- 描述第三范式数据模型的标准;
- 描述逻辑模型中的常见概念;
- 区别逻辑模型和物理模型中对应的概念;
- 列举物理设计过程中常见的反范式化处理手段。
- 以及对四个阶段有基本认识。
数据库设计的难点
- 熟悉数据库的人缺乏业务以及行业相关的专业知识
- 熟悉业务逻辑,但对数据库设计流程了解甚少。
- 数据库初始化设计阶段对业务理解不够透彻,设计的数据库有一定缺陷。
- 数据库的可扩展性极差,体现在后期需求的增加,需要修改数据库设计。
- 数据资源冗余
- 数据库性能不高
数据库设计的目标和基本特征
- 数据结构化,
- 数据共享度高,冗余度低,易于扩展;
- 数据独立性高
- 数据由 DBMS 统一管理和控制
数据库设计方法-新奥尔良方法
新奥尔良(New Orleans)方法的四个阶段:
- 需求分析阶段
- 概念设计阶段
- 逻辑设计阶段
- 物理设计阶段

1.系统需求分析阶段:
意义:
系统分析阶段通过手机信息并通过整理与分析为后续阶段做准备,同时在系统分析阶段需要了解现在系统的运行情况,新系统的功能需求,以及收集所需的业务知识。
任务:
(1)对用户业务行为和流程调查,确定用户期望与目标,以及当前系统的主要问题。
(2)系统调研,收集需求,确定系统边界。
(3)编写系统需求分析报告,包括用户规格说明书和数据字典。
需求分析的调查方法:
(1)问卷调查
(2)小组讨论
(3)采集样本
(4)和业务人员交谈
(5)查看现在资料和文档
需求分析包括
(1)业务
(2)信息源头
(3)外部需求
数据字典
数据字典是指对数据的数据项、数据结构、数据流、数据存储、处理逻辑等进行定义和描述,其目的是对数据流程图中的各个元素做出详细的说明,使用数据字典为简单的建模项目。简而言之,数据字典是描述数据的信息集合,是对系统中使用的所有数据元素的定义的集合。
数据项
■数据项名称,含义,数据类型,长度,取值范围,单位,与其他数据项逻辑关系等。
■是逻辑设计阶段模型优化的依据。
数据结构
■数据结构反映了数据项之间的组合关系。-个数据结构可以由若干数据项和数据结构混合组成。
数据流
■在系统内的传输路径。包括数据来源,流向,平均流量,高峰期流量等。
数据存储
■数据存取拼读,保留时间长度, 数据存取方式。
处理过程
■数据处理过程的功能及处理要求。功能是指处理过程用来做什么,要求包括单位时间内处理多少事务,多少数据量,时间响应要求等。
2.概念结构设计阶段;
概念设计的任务
分析用户提出的需求,对用户需求进行综合、归纳和抽象,形成一个独立于具体数据库管理系统的概念层次抽象模型,即为概念数据模型。
目的
概念设计的目的是根据需求分析的结果,将用户对数据的需求综合成一个统一的概念模型,它是整个数据库设计的关键。概念模型是现实世界和 DBMS 支持的数据模型之间的桥梁
概念模型的主要特点
1.真实准确。概念模型是对现实世界的抽象和概括,它应该真实、客观地反映现实世界中的事物和事物间的联系,应具有丰富的语义表达能力,能表达出用户的各种需求,包括描述现实世界中各种对象及其之问复杂的联系、用户对数据对象的处理要求的手段。
2.易于理解
3.易修改。当客户需求发生改变时,应该容易对概念模型进行修改和补充。
4.易转换。概念模型应容易向关系、层次和面向对象模型转换。易于从概念模式转换成与 DBMS 相关的逻辑模式。
设计时,一般是先根据单个应用的需求,画出能反映每个应用需求的局部 E-R 模型。然后把这些 E-R 图合并起来,并消除冗余和可能存在的矛盾,得到系统的 E-R 图。
E-R 方法
E-R 方法使用的工具称为 E- R 图。
- E-R 图在概念设计阶段使用的比较广泛。
- 用 E-R 模型表示的数据库概念非常直观,易于用户理解。
- E-R 图主要由实体、属性和联系三个要素构成。
实体
具有公共性质并且可以相互区分的现实世界对象的集合,例如:老师,学生,课程都是实体。

实体中每个具体的记录值,如学生实体中每个具体的学生,称之为实体的一个实例。
属性:
- 描述实体性质或特征的数据项。
- 属于一个实体的所有实例都具有相同的性质。
- 这些性质和特征就是属性,比如学生的学号、姓名和性别等。

联系
描述实体内部以及实体之间的联系。
联系使用菱形框表示。
实体之间的联系通常分为三类:
- 一对一联系(1:1):例如一个班级有一个班主任。
- 一对多联系(1:n):例如一个班级有 n 个学生组成。
- 多对多联系(m:n):例如学生选修课程。一个学生可以选修多门课程,一门课程也可以被多个学生选修。

首先,确定实体的名字并填写实体中各项属性的名称和数据类型。
然后,确定实体的主键以标志实体。
最后,对创建好的实体添加关系。 E-R 图所表示的概念模型是用户数据要求的形式化。E-R 图对立于任何一种数据模型,它不为任何一种 DBMS 所支持。
3.逻辑结构设计阶段:
逻辑设计的任务就是把概念模型转换成某个具体的 DBWS 所支持的数据模型、
逻辑设计
这个阶段是将概念模型转化为具体的数据模型的过程。
- 按照概念设计阶段建立的基本 E-R 图,按选定的目标数据模型(层次、网状、关系、面向对象) ,转换成相应的逻辑模型。
- 对于关系型数据库来说,这种转换要符合关系数据模型的原则,得到的就是逻辑数据模型。
- 这个阶段主要的工作就是确定关系模型里面的属性和码(或者说主键)。
- 比较常用的方式是使用 E- R 设计工具,IDEF1x 方法来进行逻辑模型建设,常用的 ER 图表示法包括 IDEF1x,IE 模型的 Crow's foot,UML 类图方式等。
IDEF1X 方法
IDEF1X(Integration DEFinition for Information Modeling)
信息模型集成定义。
IDEF1X 是 IDEF 系列方法中 IDEF1 的扩 展版本,是在 E-R (实体联系)方法的原则基础上,增加了一些规则,使语义更为丰富的一种方法。
IDEF1X 特点:有四个,如下所示:
- 良好的可扩展性。
- 简明的一致性结构。
- 便于理解。
- 可以自动化生成模型。
逻辑模型中的实体
根据实体的特点,划分为两类:
- 独立型实体(Independent Entity)
- 直角矩形表示。
- 不依赖于其他实体,可以独立存在。
- 依赖型实体(Dependent Entity)
- 圆角矩形表示。
- 必须依赖于其它实体而存在。
- 依赖型实体中的主键必须是独立实体主键的一部分或者全部。

实体中的属性

逻辑模型的总结
实体就是描述业务的元数据。
主键是识别实体每一个实例唯一性的标识。
只有存在外键,实体之间才会存在关系,没有外键不能建立关系。
关系的基数反映了关系之间的业务规则。
- 一个客户只能拥有一个一类储蓄账户。
- 一个客户可以拥有多个储蓄账户。
- 一个订单只能对应一个发货运单。
- 一个产品包括多个零件。
范式理论(Normal Form)
在数据库设计的时候要满足的设计规范
满足不同程度的要求为满足不同的范式;
把属性放置在正确的实体的这个过程称为范式化(normalization).
发展历史
- 1971~1972: Codd 系统地提出了 1NF、2NF 和 3NF 的概念,讨论了规范化问题;
- 1974: Codd 和 Boyce 共同提出 了新范式,BCNF;
- 1976: Fagin 提出了 4NF;
- 之后的研究人员进一步提出 5NF。
意义
设计逻辑模型时候最常遇到的问题
哪些属性应当放到实体中,怎么放?
范式化的意义:
减少数据冗余。
提供良好的可扩展性。
消除数据更新时候可能产生的数据不一致情况。
范式之间的关系:
满足最低要求的叫第一范式,记为 1NF。
在第一范式满足进- 步要求的为第二范式,2NF。以此类推。
一个低一级范式的关系模式通过模式分解(Schema Decomposition)可以转换为若干个
高一级范式的关系模式的集合。
值域
定义一个属性取值的有效范围
在值域里面的值都是合法数据。
值域体现了规则。
数据库设计三大范式
为了建立冗余较小、结构合理的数据库,设计数据库时必须遵循一定的规则。在关系型数据库中这种规则就称为范式。范式是符合某一种设计要求的总结。要想设计一个结构合理的关系型数据库,必须满足一定的范式。
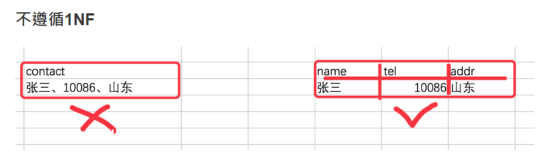
1.第一范式(确保每列保持原子性)
第一范式是最基本的范式。如果数据库表中的所有字段值都是不可分解的原子值,就说明该数据库表满足了第一范式。
原子性的程度
原子性概念在实际应用中容易出现歧义。
不可再分的程度如何确定边界。
具有编码规则的代码实际上都是复合型代码,从规则上讲都是可分的。
比如身份证号码、手机号码,都是可以进一步拆分出更细粒度的数据。
从值域的角度来理解。
身份证号码的值域:只要符合身份证编码规则的就是合法的身份证,就是原子性的数据。
2.第二范式(确保表中的每列都和主键相关)
第二范式在第一范式的基础之上更进一层。第二范式需要确保数据库表中的每一列都和主键相关,而不能只与主键的某一部分相关(主要针对联合主键而言)。也就是说在一个数据库表中,一个表中只能保存一种数据,不可以把多种数据保存在同一张数据库表中。
3.第三范式(确保每列都和主键列直接相关,而不是间接相关)
第三范式需要确保数据表中的每一列数据都和主键直接相关,而不能间接相关。
雪花型模型

逻辑模型建设的主要事项
(1)建立命名规则
命名规则的意义:
统一命名,避免歧义。
防止冗余的实体或者属性产生。
有利于工作中不同角色的人员之间通过规范的命名和属于进行交流。
便于使用。
实体和属性的命名建议:
实体名称:分类域大写+实体描述词(全称,首字母大写)。
属性名称:使用全称,首字母大写,一些约定俗称的空格缩写。
避免英语和拼音的混用。
如果是缩写,一定是英语的缩写,避免使用拼音的声母缩写。
(2)按照设计流程设计逻辑数据模型
(3)确定实体和属性:
定义实体的主键(PK).
定义部分非键属性(Non-Key Attribute).
定义非唯- -属性组。
添加相应的注释内容。
(4)确定实体与实体之间的关系:
通过外键来体现。
决定实体之间是否是可识别的关系。
确定关系的基数属于 1:1, 1:n 还是 n:m。
(5)补充实体的非键值属性:
按照 3NF 的规则,判定添加的属性是否符合 3NF 的设计原则。
如果新增属性违反 3NF,需要进行实体拆分,确定新的实体和关系。
添加注释。
4.数据库物理设计阶段;
数据库物理设计过程中需要对时间效、空间效率、维护代价和各种用户要求进行权衡,其结果可以产生多种方案。评价物理数据库的方法完全依赖于所选用的关系数据库管理系统,主要是从定量估算各种方案的存储空间、存取时间和维护代价入手,对估算结果进行权衡、比较,选择出一个较优的、合理的物理结构。
工作内容:
(1)实体非正则化处理
(2)表和字段的物理命名
(3)确定字段类型,长度,精度等
(4)增加逻辑模型中不存在的物理对象,比如索引,约束等。
相同的事物,不同的名称

逻辑模型和物理模型的对比

物理模型反范式处理
(1)从性能和应用需求出发
物理模型是以性能为出发点,支持应用需求,兼顾数据库物理限制。
CPU 无限快,内存无限多,存储无限大,带宽无限宽,还有必要反范式处理么?
(2)有限的资源,有限的硬件条件提出了物理模型反范式化的需求。
(3)反范式处理需要适度进行
对于特定配置的硬件系统,在满足应用功能目标和性能指标的前提下,适度进行。
带来数据冗余问题。.
有可能会导致数据不一致问题。
反范式常见手段
常见反范式化处理方式
。增加重复组(repeating groups)
。预关联(pre-joins)
。派生字段
。建立汇总表或临时表
。表拆分(水平拆分或者垂直拆分)
影响
。并非对所有处理过程都能带来性能提升,有些负面影响需要综合考虑进行平衡。
。反范式会降低数据模型的灵活性。
。带来数据不一致的风险。
维护数据完整性
反范式处理后增加了数据冗余性,需要一 定的管理措施来维护数据完整性。
(1)批处理维护
批处理维护是指对复制列或派生列的修改积累-定的时间后,运行一批处理作业或存
储过程对复制或派生列进行修改,这只能在对实时性要求不高的情况下使用。
(2)应用逻辑
在应用实现过程中,在同- -事务中对所有涉及的表进行增、删、改操作。
风险较大,容易遗漏,特别是在需求变化时,不易于维护。
(3)触发器
实时处理性高。
但对于数据库压力较大,尤其是高并发环境,触发器数量需要严格控制。
建立物理化命名规范
建立命名规范,对实体进行物理化命名
- 根据数据库物理特性进行命名;
- 名称有效字符的范围(避免使用非法字符出现在名称中) ;
- 避免使用物理数据库的保留关键字;
- 命名尽量采用富有意义、易于记忆、描述性强、简短及具有唯一-性的英文词汇,
- 不准采用汉语拼音。
- 制定项目组范围内统- 的命名规则,并严格遵守。
- 名称缩写要达成约定。
对象命名示例

表的物理化
- 进行反范式化操作。
- 决定是否要分区。
- 对于大表进行分区,减少 IO 扫描量,加速范围查询。
- 决定是否要拆分历史表和当前表。
- 历史表是冷数据,可以放在低速存储上;当前表是热数据,使用高速存储。
- 历史表可以使用压缩方法减少占用的存储空间。
字段的物理化
选择合适的类型,考虑以下因素:
尽量使用短字段的数据类型。
长度较短的数据类型不仅可以减小数据文件的大小,提升 IO 性能;同时也可以减小相关计算时的内存消耗,提升计算性能。比如对于整型数据,如果可以用 smallint 就尽量不用 int,如果可以用 int 就尽量不用 bigint。
使用一致的数据类型。
表关联列尽量使用相同的数据类型。如果表关联列数据类型不同,数据库必须动态地转化为相同的数据类型进行比较,这种转换会带来一定的性能消耗 。选择高效数据类型。
字段的约束 DEFAULT
如果能够从业务层面补全字段值,就不建议使用 DEFAULT 约束,避免数据加载时产生不符合预期的结果。 NOT NULL
给明确不存在 NULL 值的字段加上 NOT NULL 约束。
唯一约束/主键约束
主键=唯一+ NOT NULL。
如果条件允许,就增加。
检查约束
检查约束因为对于数据质量提出了要求,不满足约束的数据在插入数据表会导致 SQL 失败。
索引的创建与使用
可以增加索引的情况:
1.在经常需要搜索查询的列;
2.在作为主键的列,上创建索引,强制该列的唯一性;
3.在经常使用连接的列上创建索引;
4.在经常需要根据范围进行搜索的列上创建索引;
5.在经常需要排序的列上创建索引;
6.在经常使用 WHERE 子句的列上创建索引。
索引建多了,会有负面影响
- 占用更多的空间;
- 插入基表数据的效率会下降。
- 删除无效的索引,避免空间浪费
其他物理手段
根据其他特定需求:
- 是否采用压缩。
- 是否需要对数据进行加密。
- 是否需要对数据进行脱敏。
使用建模软件
使用建模软件来进行逻辑建模和物理建模:
- 功能强大而丰富;
- 正向生成 DDL,反向解析; .
- 在逻辑模型和物理模型中自由切换使用视图;
- 全面满足建模中的各种需求,高效进行建模。
相关软件:
- CA ERWin;
- SAP PowerDesigner;
- ER/Studio;
- pgModeler;
- Dbeaver Community;
物理模型产出物
●物理数据模型;
●物理模型命名规范;
●物理数据模型设计说明书;
●生成 DDL 建表语句。
总结
在本文中,围绕着数据库建模的新奥尔良法,对需求分析,概念设计,逻辑设计和物理设计这四个阶段进行了介绍和讲解,对每一个设计阶段的任务都进行了明确说明。对需求分析阶段的重要意义进行了阐述。在概念设计阶段引入了 E-R 方法。在逻辑设计一节中阐述了重要的基本概念和三大范式模型,并结合实例对各层范式进行了深入讲解。在物理设计阶段重点讲解了反范式化手段和工作中需要关注的重点。希望大家通过本文可以了解基本的数据库设计方法。