http://nathanmarz.com/blog/how-to-beat-the-cap-theorem.html
http://kb.cnblogs.com/page/124567/
面对大数据, 提出一种不同的思路
传统的方法在保证可用性的前提下, 必须用很复杂的逻辑来保证数据的最终一致性, 比如Dynamo的方案, 矢量时钟(vector clock)记录数据的版本历史合并...
作者认为复杂的原因不是 CAP 系统,而是数据增量算法和数据的可变状态
所以他的solution是,
首先, 数据是与时间相关和不可变的, CR(而非CRUD), 只能create新数据, 而非update历史数据
其次, 采用全数据分析, 而不是增量分析, 符合作者对数据系统的定义, 全集的查询
全集查询, 我们可以使用Hadoop, 但是问题是这个比较慢, 会有几个小时的延迟, 但是可以简单的保证最终一致性, 最终的结果最多延迟几个小时, 不会丢失, 不会被更改, 因为数据不可变.
问题是某些领域无法容忍几个小时的延长, 那么就加上实时的分析, 实时的分析是一个补充, 不用保证强一致性, 更加可以采用近似的算法来提高处理的效率, 反正最终会由全集查询给出正确的答案, 以保证最终的一致性
-------------------------------------------------------------------------------------------------------------------------------------------------------
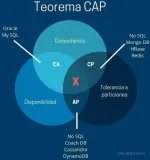
CAP 定理指出,一个数据库不可能同时满足一致性(Consistency)、可用性(Availability)和分区容错性(Partition-Tolerance)
而分区容错性是不能牺牲的,因此只能在一致性和可用性上做取舍,如何处理这种取舍正是目前 NoSQL 数据库的核心焦点
但是牺牲可用性时问题会很多,牺牲一致性时构建和维护系统的复杂度又很高,但这里又只有两个选择,不管怎样做都会不完美。CAP 定理是改不了的,那么还有什么其他可能的选择吗?
你并不能避开 CAP 定理,但可以把复杂的问题独立出来,免得你丧失对整个系统的掌控能力。CAP 定理带来的复杂性,其实是我们如何构建数据系统这一根本问题的体现。
其中有两点特别重要:数据库中可变状态和更新状态的增量算法 (the use of mutable state in databases and the use of incremental algorithms to update that state)
复杂性正是这两点和 CAP 定理之间的相互作用导致的。
本文将挑战你对数据系统如何构建这一问题的假设,通过颠覆传统数据系统构建方法,我会让大家看到一个前所未见的优雅、扩展性强、健壮的数据系统。
什么是数据系统?
下面这个简单的定义:
Query = Function (All Data)
概括了数据库和数据系统的所有领域。每一个领域——有 50 年历史的 RDBMS、索引、OLAP、OLTP、MapReduce、EFL、分布式文件系统、流处理器、NoSQL 等——都可以被概括进这个方程。
所谓数据系统就是要回答数据集问题的系统,这些问题我们称之为“查询”。上面的方程表明,查询就是数据上的一个函数。
A data system answers questions about a dataset. Those questions are called "queries". And this equation states that a query is just a function of all the data you have.
这个方程里面有两个关键概念:数据、查询。这两个完全不同的概念经常被混为一谈,所以下面来看看这两个概念究竟是什么意思。
数据
关于“数据”有两个关键的性质。
首先,数据是跟时间相关的,一个真实的数据一定是在某个时间点存在于那儿。比如,假如 Sally 在她的社交网络个人资料中写她住在芝加哥,你拿到的这个数据肯定是她某个时间在芝加哥填写的。假如某天 Sally 把她资料里面居住地点更新为亚特兰大,那么她肯定在这个时候是住在亚特兰大的,但她住在亚特兰大的事实无法改变她曾经住在芝加哥这个事实——这两个数据都是真实的。
其次,数据无法改变。由于数据跟某个时间点相关,所以数据的真实性是无法改变的。没有人可以回到那个时间去改变数据的真实性,这说明了对数据操作只有两种:读取已存在的数据和添加更多的新数据。
那么 CRUD 就变成了 CR【译者注:CRUD 是指 Create Read Update Delete,即数据的创建、读取、更新和删除】。
查询
查询是一个针对数据集的推导,就像是一个数学里面的定理。
前面我已经定义查询是整个数据集上的函数,当然,不是所有的查询都需要整个数据集,它们只需要数据集的一个子集。但我的定义是涵盖了所有的查询类型,如果想要“打败”CAP 定理,我们需要能够处理所有的查询。
打败 CAP 定理
CAP 定理仍然适用, 但是通常的那些因为 CAP 定理带来的问题,都可以通过不可改变的数据和从原始数据中计算查询来规避 (using immutable data and computing queries from scratch)
所谓打败CAP, 就是在保证可用性的情况下, 还能保证一致性.
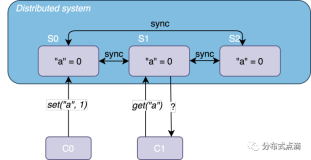
这里的关键在于数据是不可变的。不可变数据意味着这里没有更新操作,所以不可能出现数据复制不同这种不一致的情况,也意味着不需要版本化的数据、矢量时钟或者读取修复。
之前的复杂度主要来自增量更新操作和 CAP 定理之间的矛盾,在最终一致性系统中可变的值需要通过读取修复来保证最终一致性。通过使用不可变数据,去掉增量更新,使用不可变数据,每次从原始数据计算查询,你可以规避那些复杂的问题。CAP 定理就被打败了。
在数据不可变的情况下, 可以给设计带来很大的简化这点上, 很类似MVCC和HBase
MVCC 和 HBase 类似的行版本管理并不能达到上面人为错误容忍级别。MVCC 和 HBase 行版本管理不能永久保存数据,一旦数据库合并了这些版本,旧的数据就会丢失。只有不可变数据系统能够保证你在写入错误数据时可以找到一个恢复数据的方法。
批量计算
“如何让任意一个函数可以在任意一个数据集上快速执行完成”这个问题太过于复杂,所以我们先放宽了一下这个问题依赖条件。首先假设,可以允许数据滞后几小时。放宽这个条件之后,我们可以得到一个简单、优雅、通用的数据系统构建解决方案。之后,我们会通过扩展这个解决方案使得它可以不用放宽条件来解决问题。
我们将数据以文件形式存储到 HDFS 中去。文件可以包括一个数据记录序列。新增数据时,我们只需要在包括所有数据的文件夹中新增一个包含这条新记录的文件即可。像这样在 HDFS 存储数据满足了“能够很容易存储大的、不断增长的数据集”这个要求。
预计算数据集上的查询也很直观,MapReduce 是一个足够复杂的框架,使得几乎所有的函数都可以按照多个 MapReduce 任务这种方式实现。像 Cascalog、Cascading 和 Pig 这样的工具使实现这些函数变得十分简单。
最后,为了可以快速访问这些预计算查询结果,你需要对查询结果进行索引,这里有许多数据库可以完成这个工作。ElephantDB 和 Voldemort read-only 可以通过从 Hadoop 中导出 key/value 数据来加快查询速度。这些数据库支持批量写和随机读,同时不支持随机写。随机写使得数据库变得复杂,所以通过不支持随机写,这些数据库设计得特别简洁,也就几千行代码而已。简洁使得这些数据库鲁棒性变得非常好。

实时层
上面的批量处理系统几乎完全解决了在任意数据集上运行任意函数的实时性需求。任何超过几个小时的数据已经被计算进入了批处理视图中,所以剩下来要做的就是处理最近几个小时的数据。我们知道在最近几小时数据上进行查询比在整个数据集上查询要容易,这是关键点。
为了处理最近几个小时的数据,需要一个实时系统和批处理系统同时运行。这个实时系统在最近几个小时数据上预计算查询函数。要计算一个查询函数,需要查询批处理视图和实时视图,并把它们合并起来以得到最终的数据。

在实时层,可以使用 Riak 或者 Cassandra 这种读写数据库,而且实时层依赖那些数据库中对状态更新的增量算法。
让 Hadoop 模拟实时计算的工具是 Storm。我写 Storm 的目的是让 Hadoop 可以健壮、可扩展地处理大量的实时数据。Storm 在数据流上运行无限的计算,并且对这些数据处理提供了强有力的保障。

批处理层+实时层、CAP 定理和人为错误容忍性
貌似又回到一开始提出的问题上去了,访问实时数据需要使用 NoSQL 数据库和增量算法。这就说明回到了版本化数据、矢量时钟和读取修复这些复杂问题中来。但这是有本质区别的。由于实时层只处理最近几小时的数据,所有实时层的计算都会被最终批处理层重新计算。所以如果犯了什么错误或者实时层出了问题,最终都会被批处理层更正过来,所有复杂的问题都是暂时的。
总结
让可扩展的数据系统复杂的原因不是 CAP 系统,而是数据增量算法和数据的可变状态。
最近由于分布式数据库的兴起导致了复杂度越来越不可控。前面讲过,我将挑战对传统数据系统构建方法的假设。我把 CRUD 变成了 CR,把持久化层分成了批处理和实时两个层,并且得到对人为错误容忍的能力。我花费了多年来之不易的经验打破我对传统数据库的假设,并得到了这些结论。
批处理/实时架构有许多有趣的能力我并没有提到,下面我总结了一些。
- 算法的灵活性。随着数据量的增长,一些算法会越来越难计算。比如计算标识符的数量,当标识符集合越来越大时,将会越来越难计算。批处理/实时分离系统给了你在批处理系统上使用精确算法和在实时系统上使用近似算法的灵活性。批处理系统计算结果会最终覆盖实时系统的计算结果,所以最终近似值会被修正,而你的系统拥有了“最终精确性”。
- 数据结构迁移变得很容易。数据结构迁移的难题将一去不复返。由于批量计算是系统的核心,很容易在整个系统上运行一个函数,所以很容易更改你数据的结构或者视图。
- 简单的 Ad-Hoc 网络。由于批处理系统的任意性,使得你可以在数据上进行任意查询。由于所有的数据在一个点上都可以获取,所以 Ad-Hoc 网络变得简单而且方便。
- 自我检查。由于数据是不可变的,数据集就可以自我检查。数据集记录了它的数据历史,对于人为错误容忍性和数据分析很有用。