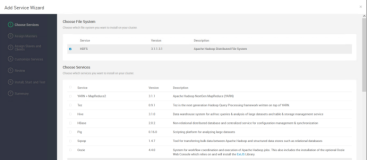
安装HDFS
由于hadoop依赖于特定版本的snappy,请先卸载snappy确保安装的顺利进行:
hawq ssh -f hostfile -e 'yum remove -y snappy'HAWQ的HDFS采用HA的方式进行安装配置。安装Hadoop可执行文件。
hawq ssh -f hostfile -e 'yum install -y hadoop hadoop-hdfs'配置NameNode目录,需要配置的节点有两个,oushum1 和 oushum2。创建nnhostfile,类似前文hostfile:
touch nnhostfile配置nnhostfile内容为hadoop的NameNode节点hostname:
oushum1oushum2创建DataNode主机文件dnhostfile,类似前文nnhostfile:
touch dnhostfile配置dnhostfile内容为hadoop的DataNode节点hostname:
oushus1oushus2创建NameNode目录:
hawq ssh -f nnhostfile -e 'mkdir -p /data1/hdfs/namenode'hawq ssh -f nnhostfile -e 'chmod -R 755 /data1/hdfs'hawq ssh -f nnhostfile -e 'chown -R hdfs:hadoop /data1/hdfs'创建DataNode目录:
hawq ssh -f dnhostfile -e 'mkdir -p /data1/hdfs/datanode'hawq ssh -f dnhostfile -e 'mkdir -p /data2/hdfs/datanode'hawq ssh -f dnhostfile -e 'chmod -R 755 /data1/hdfs'hawq ssh -f dnhostfile -e 'chmod -R 755 /data2/hdfs'hawq ssh -f dnhostfile -e 'chown -R hdfs:hadoop /data1/hdfs'hawq ssh -f dnhostfile -e 'chown -R hdfs:hadoop /data2/hdfs'修改hadoop配置文件, 根据各个节点的自身配置决定的,可以参考下面内容进行修改 ,主要是/etc/hadoop/conf目录下的core-site.xml、hdfs-site.xml、hadoop-env.xml和slaves
修改oushum1上的配置文件/etc/hadoop/conf/core-site.xml 首先需要打开HA,即去掉如下所示的HA注释:
<!-- HA
...
HA -->去掉下面的内容:
<property><name>fs.defaultFS</name><value>hdfs://hdfs-nn:9000</value></property>修改下面的内容:
<configuration><property><name>fs.defaultFS</name><value>hdfs://oushu</value></property><property><name>ha.zookeeper.quorum</name><value>oushum1:2181,oushum2:2181,oushus1:2181</value></property>...<property><name>ipc.server.listen.queue.size</name><value>3300</value></property>...<configuration>修改oushum1上的配置文件/etc/hadoop/conf/hdfs-site.xml 首先打开HA,即去掉如下所示的两行注释:
<!-- HA
...
HA -->HA打开后,修改内容如下:
<configuration><property><name>dfs.name.dir</name><value>file:/data1/hdfs/namenode</value><final>true</final></property><property><name>dfs.data.dir</name><value>file:/data1/hdfs/datanode,file:/data2/hdfs/datanode</value><final>true</final></property>...<property><name>dfs.block.local-path-access.user</name><value>gpadmin</value></property>...<property><name>dfs.domain.socket.path</name><value>/var/lib/hadoop-hdfs/dn_socket</value></property>...<property><name>dfs.block.access.token.enable</name><value>true</value><description>If "true", access tokens are used as capabilities for accessingdatanodes.If "false", no access tokens are checked on accessing datanodes.</description></property>...<property><name>dfs.nameservices</name><value>oushu</value></property><property><name>dfs.ha.namenodes.oushu</name><value>nn1,nn2</value></property><property><name>dfs.namenode.rpc-address.oushu.nn1</name><value>oushum2:9000</value></property><property><name>dfs.namenode.http-address.oushu.nn1</name><value>oushum2:50070</value></property><property><name>dfs.namenode.rpc-address.oushu.nn2</name><value>oushum1:9000</value></property><property><name>dfs.namenode.http-address.oushu.nn2</name><value>oushum1:50070</value></property><property><name>dfs.namenode.shared.edits.dir</name><value>qjournal://oushum1:8485;oushum2:8485;oushus1:8485/oushu</value></property><property><name>dfs.ha.automatic-failover.enabled.oushu</name><value>true</value></property><property><name>dfs.client.failover.proxy.provider.oushu</name><value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value></property><property><name>dfs.journalnode.edits.dir</name><value>/data1/hdfs/journaldata</value></property>...修改oushum1上/etc/hadoop/conf/hadoop-env.sh:
export JAVA_HOME="/usr/java/default"export HADOOP_CONF_DIR="/etc/hadoop/conf"export HADOOP_NAMENODE_OPTS="-Xmx6144m -XX:+UseCMSInitiatingOccupancyOnly -XX:CMSInitiatingOccupancyFraction=70"export HADOOP_DATANODE_OPTS="-Xmx2048m -Xss256k"export HADOOP_LOG_DIR=/var/log/hadoop/$USER修改oushum1上/etc/hadoop/conf/slaves 将所有DataNode的HostName写入该文件:
oushus1oushus2拷贝oushum1上/etc/hadoop/conf中的配置文件到所有节点:
hawq scp -r -f hostfile /etc/hadoop/conf =:/etc/hadoop/在oushum1节点,格式化ZKFailoverController
sudo -u hdfs hdfs zkfc -formatZK在配置journal的所有节点上,启动journalnode。创建jhostfile,类似前文hostfile,内容为配置journal的节点hostname:
oushum1oushum2oushus1使用下面的命令,启动journalnode:
hawq ssh -f jhostfile -e 'sudo -u hdfs /usr/hdp/current/hadoop-client/sbin/hadoop-daemon.sh start journalnode'格式化并启动oushum1上的NameNode:
sudo -u hdfs hdfs namenode -format -clusterId sssudo -u hdfs /usr/hdp/current/hadoop-client/sbin/hadoop-daemon.sh start namenode在另一个NameNode oushum2中进行同步操作,并启动NameNode:
hawq ssh -h oushum2 -e 'sudo -u hdfs hdfs namenode -bootstrapStandby'hawq ssh -h oushum2 -e 'sudo -u hdfs /usr/hdp/current/hadoop-client/sbin/hadoop-daemon.sh start namenode'通过hawq ssh启动所有datanode节点:
hawq ssh -f dnhostfile -e 'sudo -u hdfs /usr/hdp/current/hadoop-client/sbin/hadoop-daemon.sh start datanode'通过hawq ssh启动oushum2上的zkfc进程,使其成为active namenode:
hawq ssh -h oushum2 -e 'sudo -u hdfs /usr/hdp/current/hadoop-client/sbin/hadoop-daemon.sh start zkfc'通过hawq ssh启动oushum1上的zkfc进程,使其成为standby namenode:
hawq ssh -h oushum1 -e 'sudo -u hdfs /usr/hdp/current/hadoop-client/sbin/hadoop-daemon.sh start zkfc'检查hdfs是否成功运行:
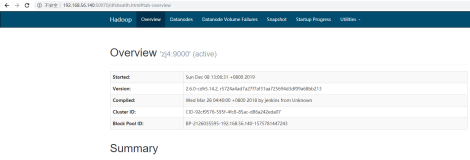
su - hdfshdfs dfsadmin -reporthdfs dfs -mkdir /testnodehdfs dfs -put /usr/hdp/current/hadoop-client/sbin/hadoop-daemon.sh /testnode/hdfs dfs -ls -R /你也可以查看HDFS web界面:http://oushum1:50070/