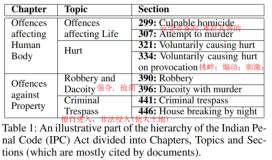
Learn Many Models, Not Just One 学习多种模型,而不仅仅是一种
In the early days of machine learning, everyone had a favorite learner, together with some a priori reasons to believe in its superiority. Most effort went into trying many variations of it and selecting the best one. Then systematic empirical comparisons showed that the best learner varies from application to application, and systems containing many different learners started to appear. Effort now went into trying many variations of many learners, and still selecting just the best one. But then researchers noticed that, if instead of selecting the best variation found, we combine many variations, the results are better—often much better—and at little extra effort for the user.
Creating such model ensembles is now standard.1 In the simplest technique, called bagging, we simply generate random variations of the training set by resampling, learn a classifier on each, and combine the results by voting. This works because it greatly reduces variance while only slightly increasing bias. In boosting, training examples have weights, and these are varied so that each new classifier focuses on the examples the previous ones tended to get wrong. In stacking, the outputs of individual classifiers become the inputs of a “higher-level” learner that figures out how best to combine them. 在机器学习的早期,每个人都有一个喜欢的学习者,加上一些先验的理由相信它的优越性。最努力的尝试是尝试它的多种变体并选择最佳的一种。然后系统的经验比较表明,最佳学习者因应用程序而异,并且包含许多不同学习者的系统开始出现。现在,我们努力尝试许多学习者的许多变体,但仍然只选择最好的一个。但是随后研究人员注意到,如果我们不选择发现的最佳变体,而是结合许多变体,则结果会更好-通常更好得多-并且对用户来说几乎没有额外的精力。
创建这样的模型集成现在是标准的.1。在最简单的技术(称为装袋)中,我们只需通过重新采样就可以生成训练集的随机变化,在每个学习一个分类器,然后通过投票合并结果。之所以行之有效,是因为它大大减少了方差,而偏差却稍有增加。在增强方面,训练示例具有权重,并且这些权重是可变的,因此每个新分类器都将重点放在示例上,而先前的那些往往会出错。在堆叠中,单个分类器的输出成为一个``高级''学习器的输入,该学习器找出了如何最好地组合它们。
Many other techniques exist, and the trend is toward larger and larger ensembles. In the Netflix prize, teams from all over the world competed to build the best video recommender system (http://netflixprize.com). As the competition progressed, teams found they obtained the best results by combining their learners with other teams’, and merged into larger and larger teams. The winner and runnerup were both stacked ensembles of over 100 learners, and combining the two ensembles further improved the results. Doubtless we will see even larger ones in the future.
Model ensembles should not be confused with Bayesian model averaging (BMA)—the theoretically optimal approach to learning.4 In BMA, predictions on new examples are made by averaging the individual predictions of all classifiers in the hypothesis space, weighted by how well the classifiers explain the training data and how much we believe in them a priori. Despite their superficial similarities, ensembles and BMA are very different. Ensembles change the hypothesis space (for example, from single decision trees to linear combinations of them), and can take a wide variety of forms. BMA assigns weights to the hypotheses in the original space according to a fixed formula. BMA weights are extremely different from those produced by (say) bagging or boosting: the latter are fairly even, while the former are extremely skewed, to the point where the single highest-weight classifier usually dominates, making BMA effectively equivalent to just selecting it.8 A practical consequence of this is that, while model ensembles are a key part of the machine learning toolkit, BMA is seldom worth the trouble. 存在许多其他技术,并且趋势正在越来越大。在Netflix奖项中,来自世界各地的团队竞争建立了最佳的视频推荐系统(http://netflixprize.com)。随着比赛的进行,团队发现他们通过将学习者与其他``团队''结合在一起而获得了最佳成绩,并合并为越来越大的团队。获胜者和亚军都是超过100名学习者的堆叠乐团,并且将这两个乐团结合起来可以进一步改善结果。毫无疑问,我们将来会看到更大的机型。
模型集合不应与贝叶斯模型平均(BMA)混淆-理论上的最佳学习方法.4在BMA中,对新示例的预测是通过对假设空间中所有分类器的各个预测取平均,并通过对分类器加权的方式得出的解释训练数据以及我们对它们有先验的信任度。尽管它们在表面上有相似之处,但合奏和BMA却有很大不同。集合更改假设空间(例如,从单个决策树更改为它们的线性组合),并且可以采用多种形式。 BMA根据固定公式将权重分配给原始空间中的假设。 BMA权重与(例如)装袋或提升产生的权重极为不同:后者相当均匀,而前者则极为偏斜,以至于单个最高权重的分类器通常占主导地位,这使得BMA有效地等同于仅选择它.8的实际结果是,虽然模型集成是机器学习工具包的关键部分,但BMA很少值得为此烦恼。
Simplicity Does Not Imply Accuracy 简易性不准确
Just because a function can be represented does not mean it can be learned. 仅仅因为可以表示一个函数并不意味着可以学习它。
Occam’s razor famously states that entities should not be multiplied beyond necessity. In machine learning, this is often taken to mean that, given two classifiers with the same training error, the simpler of the two will likely have the lowest test error. Purported proofs of this claim appear regularly in the literature, but in fact there are many counterexamples to it, and the “no free lunch” theorems imply it cannot be true. We saw one counterexample previously: model ensembles. The generalization error of a boosted ensemble continues to improve by adding classifiers even after the training error has reached zero. Another counterexample is support vector machines, which can effectively have an infinite number of parameters without overfitting. Conversely, the function sign(sin(ax)) can discriminate an arbitrarily large, arbitrarily labeled set of points on the x axis, even though it has only one parameter.23 Thus, contrary to intuition, there is no necessary connection between the number of parameters of a model and its tendency to overfit. 奥卡姆(Occam)的剃刀著名地指出,实体不应超出必需的数量。在机器学习中,这通常是指给定两个具有相同训练误差的分类器,两个简单的分类器可能具有最低的测试误差。据称该主张的证据在文献中经常出现,但实际上有很多反例,并且``无免费午餐''定理表明它不成立。之前我们看到了一个反例:模型集成。甚至在训练误差达到零之后,通过添加分类器,仍可以提高增强的合奏的泛化误差。另一个反例是支持向量机,它可以有效地具有无限数量的参数而不会过度拟合。相反,功能符号(sin(ax))可以区分x轴上任意大的,带有标签的点集,尽管它只有一个参数.23因此,与直觉相反,数字之间没有必要的联系模型的参数及其过度拟合的趋势。
A more sophisticated view instead equates complexity with the size of the hypothesis space, on the basis that smaller spaces allow hypotheses to be represented by shorter codes. Bounds like the one in the section on theoretical guarantees might then be viewed as implying that shorter hypotheses generalize better. This can be further refined by assigning shorter codes to the hypotheses in the space we have some a priori preference for. But viewing this as “proof” of a trade-off between accuracy and simplicity is circular reasoning: we made the hypotheses we prefer simpler by design, and if they are accurate it is because our preferences are accurate, not because the hypotheses are “simple” in the representation we chose.
A further complication arises from the fact that few learners search their hypothesis space exhaustively. A learner with a larger hypothesis space that tries fewer hypotheses from it is less likely to overfit than one that tries more hypotheses from a smaller space. As Pearl18 points out, the size of the hypothesis space is only a rough guide to what really matters for relating training and test error: the procedure by which a hypothesis is chosen.
Domingos7 surveys the main arguments and evidence on the issue of Occam’s razor in machine learning. The conclusion is that simpler hypotheses should be preferred because simplicity is a virtue in its own right, not because of a hypothetical connection with accuracy. This is probably what Occam meant in the first place.
相反,一个更复杂的视图将复杂度与假设空间的大小等同起来,其依据是较小的空间允许用较短的代码表示假设。像理论保证一节中所述的界限可能会被认为暗示着较短的假设通常会更好。可以通过为我们具有某些先验偏好的空间中的假设分配较短的代码来进一步完善。但是,将其视为在准确性和简单性之间进行权衡的``证明''是循环推理:我们通过设计使假设变得更简单,如果假设是准确的,那是因为我们的偏好是准确的,而不是因为假设是``简单的''在我们选择的表示形式中。
更为复杂的是由于几乎没有学习者详尽地搜索其假设空间这一事实。拥有较大假设空间的学习者从中尝试较少的假设的可能性比从较小空间尝试更多假设的学习者的过拟合可能性小。正如Pearl18所指出的那样,假设空间的大小仅是对与训练和测试误差有关的真正重要性的粗略指导:选择假设的过程。 Domingos7调查了有关机器学习中Occam剃刀问题的主要论点和证据。结论是,应采用更简单的假设,因为简单性本身就是一种美德,而不是因为假设与准确性之间的联系。这可能是Occam首先的意思。
Representable Does Not Imply Learnable 有代表性的不容易学习
Essentially all representations used in variable-size learners have associated theorems of the form “Every function can be represented, or approximated arbitrarily closely, using this representation.” Reassured by this, fans of the representation often proceed to ignore all others. However, just because a function can be represented does not mean it can be learned. For example, standard decision tree learners cannot learn trees with more leaves than there are training examples. In continuous spaces, representing even simple functions using a fixed set of primitives often requires an infinite number of components. Further, if the hypothesis space has many local optima of the evaluation function, as is often the case, the learner may not find the true function even if it is representable. Given finite data, time and memory, standard learners can learn only a tiny subset of all possible functions, and these subsets are different for learners with different representations. Therefore the key question is not “Can it be represented?” to which the answer is often trivial, but “Can it be learned?” And it pays to try different learners (and possibly combine them).
Some representations are exponentially more compact than others for some functions. As a result, they may also require exponentially less data to learn those functions. Many learners work by forming linear combinations of simple basis functions. For example, support vector machines form combinations of kernels centered at some of the training examples (the support vectors). Representing parity of n bits in this way requires 2n basis functions. But using a representation with more layers (that is, more steps between input and output), parity can be encoded in a linear-size classifier. Finding methods to learn these deeper representations is one of the major research frontiers in machine learning.2
基本上,可变大小学习器中使用的所有表示形式都有相关的定理,形式为``可以使用该表示形式来表示或任意近似地逼近每个函数''。对此感到放心的是,代表制的支持者经常会忽略其他所有人。但是,仅仅因为可以表示一个函数并不意味着可以学习它。例如,标准决策树学习者无法学习叶子多于训练实例的树。在连续空间中,使用一组固定的基元表示甚至简单的函数通常需要无限数量的组件。此外,如果假设空间具有很多评估函数的局部最优值(通常是这样),则学习者即使可以表示,也可能找不到真正的函数。给定有限的数据,时间和内存,标准学习者只能学习所有可能功能的一小部分,而对于具有不同表示形式的学习者来说,这些子集是不同的。因此,关键问题不是“能否代表?”答案通常是微不足道的,但是“可以学习吗?”尝试不同的学习者(并可能将他们合并)是值得的。
对于某些功能,某些表示形式比其他表示形式更紧凑。结果,他们可能还需要以指数形式减少的数据来学习这些功能。许多学习者通过形成简单基函数的线性组合来工作。例如,支持向量机形成了以一些训练示例(支持向量)为中心的内核组合。以这种方式表示n位的奇偶校验需要2n个基函数。但是使用具有更多层的表示(即输入和输出之间的更多步骤),可以将奇偶校验编码为线性大小的分类器。寻找学习这些更深层表示的方法是机器学习的主要研究领域之一.2
Correlation Does Not Imply Causation 关联不表示因果关系
The point that correlation does not imply causation is made so often that it is perhaps not worth belaboring. But, even though learners of the kind we have been discussing can only learn correlations, their results are often treated as representing causal relations. Isn’t this wrong? If so, then why do people do it?
More often than not, the goal of learning predictive models is to use them as guides to action. If we find that beer and diapers are often bought together at the supermarket, then perhaps putting beer next to the diaper section will increase sales. (This is a famous example in the world of data mining.) But short of actually doing the experiment it is difficult to tell. Machine learning is usually applied to observational data, where the predictive variables are not under the control of the learner, as opposed to experimental data, where they are. Some learning algorithms can potentially extract causal information from observational data, but their applicability is rather restricted.19 On the other hand, correlation is a sign of a potential causal connection, and we can use it as a guide to further investigation (for example, trying to understand what the causal chain might be). 关联并不意味着因果关系如此频繁,这一点也许值得我们去研究。但是,即使我们一直在讨论的那种学习者只能学习相关性,他们的结果也经常被视为代表因果关系。这不是错吗?如果是这样,那么人们为什么这样做?
通常,学习预测模型的目的是将其用作行动指南。如果我们发现啤酒和尿布经常是在超市一起买的,那么也许把啤酒放在尿布下面会增加销量。 (这是数据挖掘世界中的一个著名示例。)但是实际上很难进行实验,很难说清楚。机器学习通常应用于观测数据,而预测变量不在学习者的控制之下,而与实验数据相反。一些学习算法可能会从观测数据中提取因果信息,但其适用性受到限制.19另一方面,相关性是潜在因果关系的标志,我们可以将其用作进一步调查的指南(例如,试图了解原因链可能是什么)。
Many researchers believe that causality is only a convenient fiction. For example, there is no notion of causality in physical laws. Whether or not causality really exists is a deep philosophical question with no definitive answer in sight, but there are two practical points for machine learners. First, whether or not we call them “causal,” we would like to predict the effects of our actions, not just correlations between observable variables. Second, if you can obtain experimental data (for example by randomly assigning visitors to different versions of a Web site), then by all means do so.14 许多研究人员认为因果关系只是一种方便的小说。 例如,物理定律中没有因果关系的概念。 因果关系是否真的存在是一个深刻的哲学问题,没有明确的答案,但是对于机器学习者来说有两个实践点。 首先,无论我们是否称其为``因果关系'',我们都希望预测行为的影响,而不仅仅是可观察变量之间的相关性。 其次,如果您可以获得实验数据(例如通过将访问者随机分配给网站的不同版本),则一定要这样做.14
Conclusion 结论
Like any discipline, machine learning has a lot of “folk wisdom” that can be difficult to come by, but is crucial for success. This article summarized some of the most salient items. Of course, it is only a complement to the more conventional study of machine learning. Check out http://www. cs.washington.edu/homes/pedrod/ class for a complete online machine learning course that combines formal and informal aspects. There is also a treasure trove of machine learning lectures at http://www.videolectures. net. A good open source machine learning toolkit is Weka.24
Happy learning! 像任何学科一样,机器学习具有许多难以获得的``民间智慧'',但对于成功至关重要。 本文总结了一些最突出的项目。 当然,它只是对机器学习的更常规研究的补充。 查看http:// www。 cs.washington.edu/homes/pedrod/上一堂完整的在线机器学习课程,该课程结合了正式和非正式方面。 在http://www.videolectures上还有一个机器学习宝库。 净。 一个很好的开源机器学习工具包是Weka.24祝您学习愉快!