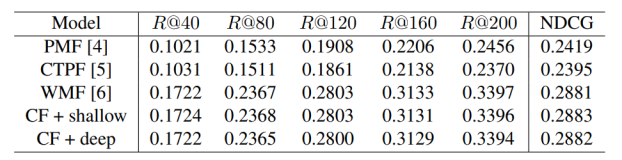
A Unified Approach to Interpreting Model Predictions》论文解读与翻译
论文地址:https://arxiv.org/pdf/1705.07874.pdf
Abstract
Understanding why a model makes a certain prediction can be as crucial as the prediction’s accuracy in many applications. However, the highest accuracy for large modern datasets is often achieved by complex models that even experts struggle to interpret, such as ensemble or deep learning models, creating a tension between accuracy and interpretability. In response, various methods have recently been proposed to help users interpret the predictions of complex models, but it is often unclear how these methods are related and when one method is preferable over another. To address this problem, we present a unified framework for interpreting predictions, SHAP (SHapley Additive exPlanations). SHAP assigns each feature an importance value for a particular prediction. Its novel components include: (1) the identification of a new class of additive feature importance measures, and (2) theoretical results showing there is a unique solution in this class with a set of desirable properties. The new class unifies six existing methods, notable because several recent methods in the class lack the proposed desirable properties. Based on insights from this unification, we present new methods that show improved computational performance and/or better consistency with human intuition than previous approaches.
在许多应用中,理解一个模型为什么要进行某种预测与预测的准确性同样重要。然而,现代大型数据集的最高精度往往是通过复杂的模型来实现的,即使是专家也很难解释,比如集成或深度学习模型,这就造成了准确性和可解释性之间的紧张关系。因此,最近提出了各种方法来帮助用户解释复杂模型的预测,但这些方法之间的关系以及一种方法什么时候比另一种方法更好往往是不清楚的。为了解决这个问题,我们提出了一个统一的框架来解释预测,SHAP (SHapley Additive explanation)。SHAP为每个特征分配一个特定预测的重要性值。它的新颖之处包括:
(1)确定了一类新的可加性特征重要性测度,
(2)理论结果表明,在这类测度中存在一个具有一组理想性质的唯一解。这个新类统一了6个现有的方法,值得注意的是,这个类中最近出现的几个方法都缺乏所建议的所需属性。
基于这种统一的见解,我们提出了比以前的方法更好的计算性能和/或与人类直觉的一致性的新方法。
1 Introduction
The ability to correctly interpret a prediction model’s output is extremely important. It engenders appropriate user trust, provides insight into how a model may be improved, and supports understanding of the process being modeled. In some applications, simple models (e.g., linear models) are often preferred for their ease of interpretation, even if they may be less accurate than complex ones. However, the growing availability of big data has increased the benefits of using complex models, so bringing to the forefront the trade-off between accuracy and interpretability of a model’s output. A wide variety of different methods have been recently proposed to address this issue [5, 8, 9, 3, 4, 1]. But an understanding of how these methods relate and when one method is preferable to another is still lacking.
正确解释预测模型输出的能力是极其重要的。它能够建立使用者的信任,提供对模型如何改进的见解,并支持对建模过程的理解。在某些应用中,简单模型(例如线性模型)往往因其易于解释而受到青睐,即使它们可能不如复杂模型准确。然而,随着大数据可用性的不断增加,使用复杂模型的好处也越来越多,因此,在模型输出的准确性和可解释性之间进行权衡就成了当务之急。最近人们提出了各种不同的方法来解决这个问题[5,8,9,3,4,1]。但是,对于这些方法之间的关系以及哪种方法比哪种方法更好的理解仍然缺乏。
Here, we present a novel unified approach to interpreting model predictions.1 Our approach leads to three potentially surprising results that bring clarity to the growing space of methods:
1. We introduce the perspective of viewing any explanation of a model’s prediction as a model itself, which we term the explanation model. This lets us define the class of additive feature attribution methods (Section 2), which unifies six current methods.
2. We then show that game theory results guaranteeing a unique solution apply to the entire class of additive feature attribution methods (Section 3) and propose SHAP values as a unified measure of feature importance that various methods approximate (Section 4).
3. We propose new SHAP value estimation methods and demonstrate that they are better aligned with human intuition as measured by user studies and more effectually discriminate among model output classes than several existing methods (Section 5).
在这里,我们提出了一个新的统一的方法来解释模型的预测。我们的方法导致了三个潜在的令人惊讶的结果,使越来越多的方法变得清晰起来:
1. 我们引入了这样一种观点,即把对模型预测的任何解释看作模型本身,我们称之为解释模型。这让我们可以定义附加特性属性方法的类(第2节),它统一了6个当前的方法。
2. 然后,我们展示了保证唯一解的博弈论结果适用于整个类别的加性特征属性方法(第3节),并提出了SHAP值作为特征重要性的统一度量,各种方法都近似(第4节)。
3.我们提出了新的SHAP值估计方法,并证明了它们比现有的几种方法更符合用户研究所衡量的人类直觉,更有效地区分模型输出类(第5节)。
2 Additive Feature Attribution Methods
加性特征归因方法
The best explanation of a simple model is the model itself; it perfectly represents itself and is easy to understand. For complex models, such as ensemble methods or deep networks, we cannot use the original model as its own best explanation because it is not easy to understand. Instead, we must use a simpler explanation model, which we define as any interpretable approximation of the original model. We show below that six current explanation methods from the literature all use the same explanation model. This previously unappreciated unity has interesting implications, which we describe in later sections.
Let f be the original prediction model to be explained and g the explanation model. Here, we focus on local methods designed to explain a prediction f(x) based on a single input x, as proposed in LIME [5]. Explanation models often use simplified inputs x 0 that map to the original inputs through a mapping function x = hx(x 0 ). Local methods try to ensure g(z 0 ) ≈ f(hx(z 0 )) whenever z 0 ≈ x 0 . (Note that hx(x 0 ) = x even though x 0 may contain less information than x because hx is specific to the current input x.)
Definition 1 Additive feature attribution methods have an explanation model that is a linear function of binary variables:
where z 0 ∈ {0, 1}M, M is the number of simplified input features, and φi ∈ R.
Methods with explanation models matching Definition 1 attribute an effect φi to each feature, and summing the effects of all feature attributions approximates the output f(x) of the original model. Many current methods match Definition 1, several of which are discussed below.
对简单模型最好的解释是模型本身;它完美地表现了自己,很容易理解。对于复杂模型,如集成方法或深度网络,我们不能使用原始模型作为自己的最佳解释,因为它不容易理解。相反,我们必须使用一个更简单的解释模型,我们将其定义为原始模型的任何可解释的近似。下面我们可以看出,文献中目前的六种解释方法都使用相同的解释模型。这种以前未被重视的统一具有有趣的含义,我们将在后面的章节中描述。
设f为待解释的原始预测模型,g为解释模型。这里,我们着重于局部方法,这些方法被设计用来解释基于单个输入x的预测f(x),如LIME[5]所提出的。解释模型通常使用简化的输入x 0,通过映射函数x = hx(x 0)映射到原始输入。局部方法在z0≈x0时尽量确保g(z0)≈f(hx(z0))。(注意hx(x0) = x,尽管x0包含的信息可能比x少,因为hx是特定于当前输入x的。)
定义1加性特征归因方法的解释模型是二元变量的线性函数:
其中z 0∈{0,1}M, M为简化输入特征的数量,而算得上是∈R。
方法用解释模型匹配定义1,对每个特征属性的效果进行排序,并将所有特征属性的效果相加,逼近原始模型的输出f(x)。许多当前的方法匹配定义1,下面将讨论其中的几个。
2.1 LIME
The LIME method interprets individual model predictions based on locally approximating the model around a given prediction [5]. The local linear explanation model that LIME uses adheres to Equation 1 exactly and is thus an additive feature attribution method. LIME refers to simplified inputs x 0 as “interpretable inputs,” and the mapping x = hx(x 0 ) converts a binary vector of interpretable inputs into the original input space. Different types of hx mappings are used for different input spaces. For bag of words text features, hx converts a vector of 1’s or 0’s (present or not) into the original word count if the simplified input is one, or zero if the simplified input is zero. For images, hx treats the image as a set of super pixels; it then maps 1 to leaving the super pixel as its original value and 0 to replacing the super pixel with an average of neighboring pixels (this is meant to represent being missing). To find φ, LIME minimizes the following objective function:
ξ = arg min g∈G L(f, g, πx0 ) + Ω(g). (2)
Faithfulness of the explanation model g(z 0 ) to the original model f(hx(z 0 )) is enforced through the loss L over a set of samples in the simplified input space weighted by the local kernel πx0 . Ω penalizes the complexity of g. Since in LIME g follows Equation 1 and L is a squared loss, Equation 2 can be solved using penalized linear regression.
LIME方法解释个别模型的预测,基于局部逼近模型周围的一个给定的预测[5]。LIME使用的局部线性解释模型完全符合方程1,是一种加性特征归因方法。LIME将简化的输入x0称为“可解释输入”,映射x = hx(x0)将可解释输入的二进制向量转换为原始输入空间。不同类型的hx映射用于不同的输入空间。对于word包文本特性,如果简体输入为1,hx将1或0(存在与否)的向量转换为原始字数,如果简体输入为0,则转换为零。对于图像,hx将图像视为超像素的集合;然后,它将1映射为保留超像素的原始值,将0映射为用相邻像素的平均值(这意味着缺失)替换超像素。要找到φ,LIME将下列目标函数最小化:
解释模型g(z0)对原始模型f(hx(z0))的忠实程度是通过在简化输入空间中对一组样本L的损失来实现的,该简化输入空间由局部核函数sifx0加权。Ω惩罚g的复杂性。因为在LIMEg方程1,L是一个平方损失,使用惩罚线性回归方程2可以解决。
2.2 DeepLIFT
DeepLIFT was recently proposed as a recursive prediction explanation method for deep learning [8, 7]. It attributes to each input xi a value C∆xi∆y that represents the effect of that input being set to a reference value as opposed to its original value. This means that for DeepLIFT, the mapping x = hx(x 0 ) converts binary values into the original inputs, where 1 indicates that an input takes its original value, and 0 indicates that it takes the reference value. The reference value, though chosen by the user, represents a typical uninformative background value for the feature. DeepLIFT uses a "summation-to-delta" property that states:
where o = f(x) is the model output, ∆o = f(x) − f(r), ∆xi = xi − ri , and r is the reference input. If we let φi = C∆xi∆o and φ0 = f(r), then DeepLIFT’s explanation model matches Equation 1 and is thus another additive feature attribution method.
DeepLIFT是最近提出的一种用于深度学习的递归预测解释方法[8,7]。为每个输入xi赋予一个值C∆xi∆y,表示该输入相对于其原始值被设置为一个参考值后的效果。这意味着对于DeepLIFT,映射x = hx(x 0)将二进制值转换为原始输入,其中1表示输入接受其原始值,0表示它接受引用值。参考值虽然是由用户选择的,但代表了该特性的典型的非信息背景值。DeepLIFT使用了一个“求和到增量”属性,该属性表示:
其中o = f(x)为模型输出,∆o = f(x)−f(r),∆xi = xi−ri, r为参考输入。如果我们φi = C∆xi∆o and φ0 = f(r), ,则DeepLIFT的解释模型符合方程1,是另一种加性特征归因方法。
2.3 Layer-Wise Relevance Propagation
The layer-wise relevance propagation method interprets the predictions of deep networks [1]. As noted by Shrikumar et al., this menthod is equivalent to DeepLIFT with the reference activations of all neurons fixed to zero. Thus, x = hx(x 0 ) converts binary values into the original input space, where 1 means that an input takes its original value, and 0 means an input takes the 0 value. Layer-wise relevance propagation’s explanation model, like DeepLIFT’s, matches Equation 1.
分层关联传播方法解释了深度网络[1]的预测。正如Shrikumar等人所指出的,这种方法相当于将所有神经元的参考激活固定为零的DeepLIFT。因此,x = hx(x 0)将二进制值转换为原始输入空间,其中1表示输入取其原始值,0表示输入取0值。分层关联传播的解释模型,如DeepLIFT,符合方程1。
2.4 Classic Shapley Value Estimation
经典Shapley值估计
Three previous methods use classic equations from cooperative game theory to compute explanations of model predictions: Shapley regression values [4], Shapley sampling values [9], and Quantitative Input Influence [3].
Shapley regression values are feature importances for linear models in the presence of multicollinearity. This method requires retraining the model on all feature subsets S ⊆ F, where F is the set of all features. It assigns an importance value to each feature that represents the effect on the model prediction of including that feature. To compute this effect, a model fS∪{i} is trained with that feature present, and another model fS is trained with the feature withheld. Then, predictions from the two models are compared on the current input fS∪{i}(xS∪{i}) − fS(xS), where xS represents the values of the input features in the set S. Since the effect of withholding a feature depends on other features in the model, the preceding differences are computed for all possible subsets S ⊆ F \ {i}. The Shapley values are then computed and used as feature attributions. They are a weighted average of all possible differences:
For Shapley regression values, hx maps 1 or 0 to the original input space, where 1 indicates the input is included in the model, and 0 indicates exclusion from the model. If we let φ0 = f∅(∅), then the Shapley regression values match Equation 1 and are hence an additive feature attribution method.
之前的三种方法使用合作博弈论的经典方程来计算模型预测的解释:Shapley回归值[4],Shapley采样值[9],定量输入影响[3]。
Shapley回归值是存在多重共线性的线性模型的重要特征。该方法需要对所有特性子集S⊆F重新训练模型,其中F是所有特性的集合。它为每个特征赋值,表示包含该特征对模型预测的影响。为了计算这种效果,一个模型fS∪{i}使用该特征进行训练,另一个模型fS使用保留该特征进行训练。然后,比较从两个模型预测在当前输入fS∪{我}(xS∪{我})−F (x),其中x表示的值输入特性集S以来扣留一个特性的影响取决于模型中的其他功能,前面的差异计算所有可能的子集S⊆F \{我}。然后计算Shapley值作为特征属性。它们是所有可能差异的加权平均值:
对于Shapley回归值,hx将1或0映射到原始输入空间,其中1表示输入包含在模型中,0表示从模型中排除。如果我们让bx0 = f∅(∅),那么Shapley回归值与方程1匹配,因此是一种加性特征归因方法。
Shapley sampling values are meant to explain any model by: (1) applying sampling approximations to Equation 4, and (2) approximating the effect of removing a variable from the model by integrating over samples from the training dataset. This eliminates the need to retrain the model and allows fewer than 2 |F | differences to be computed. Since the explanation model form of Shapley sampling values is the same as that for Shapley regression values, it is also an additive feature attribution method.
Quantitative input influence is a broader framework that addresses more than feature attributions. However, as part of its method it independently proposes a sampling approximation to Shapley values that is nearly identical to Shapley sampling values. It is thus another additive feature attribution method.
Shapley采样值用于解释任何模型:(1)对公式4应用采样逼近,(2)通过对训练数据集的样本进行积分来逼近从模型中移除一个变量的效果。这就消除了对模型进行再训练的需要,并允许计算小于2 |F |的差异。由于Shapley采样值的解释模型形式与Shapley回归值的解释模型形式相同,也是一种加性特征归因方法。
定量输入影响是一个更广泛的框架,解决的不仅仅是特征属性。然而,作为其方法的一部分,它独立地提出了一个近似于Shapley值的采样方法,该方法几乎与Shapley采样值相同。因此,它是另一种加性特征归因方法。
3 Simple Properties Uniquely Determine Additive Feature Attributions
简单属性唯一地决定了可加性特征属性
A surprising attribute of the class of additive feature attribution methods is the presence of a single unique solution in this class with three desirable properties (described below). While these properties are familiar to the classical Shapley value estimation methods, they were previously unknown for other additive feature attribution methods.
The first desirable property is local accuracy. When approximating the original model f for a specific input x, local accuracy requires the explanation model to at least match the output of f for the simplified input x 0 (which corresponds to the original input x).
Property 1 (Local accuracy)
The explanation model g(x 0 ) matches the original model f(x) when x = hx(x 0 ).
The second property is missingness. If the simplified inputs represent feature presence, then missingness requires features missing in the original input to have no impact. All of the methods described in Section 2 obey the missingness property.
Property 2 (Missingness)
Missingness constrains features where x 0 i = 0 to have no attributed impact.
The third property is consistency. Consistency states that if a model changes so that some simplified input’s contribution increases or stays the same regardless of the other inputs, that input’s attribution should not decrease.
Property 3 (Consistency)
加法特征属性方法类的一个令人惊讶的属性是该类中存在一个唯一的解决方案,具有三个理想的属性(如下所述)。虽然这些特性对于经典的Shapley值估计方法来说是很常见的,但是对于其他的加性特征属性方法来说,它们是未知的。
第一个需要的特性是局部精度。当对特定输入x近似原始模型f时,局部精度要求解释模型至少匹配简化输入x 0的f输出(对应于原始输入x)。
属性1(局部精度)
f(x) = g(x 0) = x0 + xm i=1 (5)
当x = hx(x0)时,解释模型g(x0)与原始模型f(x)匹配。
第二个特性是缺失。如果简化的输入表示特性的存在,那么丢失要求原始输入中丢失的特性不会产生影响。第2节中描述的所有方法都服从失联性。
属性2 (Missingness)
(6) x 0 i = 0从下= 0 (6)
缺失限制了x0i = 0没有属性影响的特征。
第三个属性是一致性。一致性指的是,如果一个模型发生了变化,使得某些简化输入的贡献增加或保持不变,而不受其他输入的影响,那么该输入的属性就不应该减少。
属性3(一致性)
设fx(z0) = f(hx(z0))和z0 \ i表示设z0 i = 0。对于任意两种模型f和f0,如果f0x (z0)−f0x (z0 \ i)≥fx(z0)−fx(z0 \ i)(7)对于所有输入z 0∈{0,1}M,则rqi (f0, x)≥rqi (f, x)。
定理1只有一种可能的解释模型g遵循定义1并满足属性1、2和3:(M−|z−0 |−1)!米其中,| z0 |为z0中非零项的数量,z0⊆x 0表示所有的z0向量,其中非零项是x0中非零项的子集。
Theorem 1 Only one possible explanation model g follows Definition 1 and satisfies Properties 1, 2, and 3: φi(f, x) = X z 0⊆x0 |z 0 |!(M − |z 0 | − 1)! M! [fx(z 0 ) − fx(z 0 \ i)] (8) where |z 0 | is the number of non-zero entries in z 0 , and z 0 ⊆ x 0 represents all z 0 vectors where the non-zero entries are a subset of the non-zero entries in x 0 .
Theorem 1 follows from combined cooperative game theory results, where the values φi are known as Shapley values [6]. Young (1985) demonstrated that Shapley values are the only set of values that satisfy three axioms similar to Property 1, Property 3, and a final property that we show to be redundant in this setting (see Supplementary Material). Property 2 is required to adapt the Shapley proofs to the class of additive feature attribution methods.
Under Properties 1-3, for a given simplified input mapping hx, Theorem 1 shows that there is only one possible additive feature attribution method. This result implies that methods not based on Shapley values violate local accuracy and/or consistency (methods in Section 2 already respect missingness). The following section proposes a unified approach that improves previous methods, preventing them from unintentionally violating Properties 1 and 3.
定理1来源于组合合作博弈论的结果,其中的值称为Shapley值[6]。Young(1985)证明Shapley值是唯一满足三个公理的值集,这三个公理与属性1、属性3和最后一个我们在此设置中显示为冗余的属性相似(参见补充材料)。属性2需要将Shapley证明应用于可加性特征归属方法的类别。
在属性1-3下,对于给定的简化输入映射hx,定理1表明只有一种可能的加性特征属性方法。这个结果意味着不基于Shapley值的方法会破坏局部精度和/或一致性(第2节中的方法已经考虑了缺失)。下面的部分提出了一种统一的方法,可以改进以前的方法,防止它们无意中违反属性1和属性3。
4 SHAP (SHapley Additive exPlanation) Values
We propose SHAP values as a unified measure of feature importance. These are the Shapley values of a conditional expectation function of the original model; thus, they are the solution to Equation 8, where fx(z 0 ) = f(hx(z 0 )) = E[f(z) | zS], and S is the set of non-zero indexes in z 0 (Figure 1). Based on Sections 2 and 3, SHAP values provide the unique additive feature importance measure that adheres to Properties 1-3 and uses conditional expectations to define simplified inputs. Implicit in this definition of SHAP values is a simplified input mapping, hx(z 0 ) = zS, where zS has missing values for features not in the set S. Since most models cannot handle arbitrary patterns of missing input values, we approximate f(zS) with E[f(z) | zS]. This definition of SHAP values is designed to closely align with the Shapley regression, Shapley sampling, and quantitative input influence feature attributions, while also allowing for connections with LIME, DeepLIFT, and layer-wise relevance propagation.
The exact computation of SHAP values is challenging. However, by combining insights from current additive feature attribution methods, we can approximate them. We describe two model-agnostic approximation methods, one that is already known (Shapley sampling values) and another that is novel (Kernel SHAP). We also describe four model-type-specific approximation methods, two of which are novel (Max SHAP, Deep SHAP). When using these methods, feature independence and model linearity are two optional assumptions simplifying the computation of the expected values (note that S¯ is the set of features not in S):
、
我们提出SHAP值作为特征重要性的统一度量。这些是原始模型的条件期望函数的Shapley值;因此,他们是方程的解,在fx (z 0) = f (hx (z 0)) = E (f (z) | z)和S中的非零索引集z 0(图1)。基于部分2和3,SHAP值提供了遵循属性1-3的独特的加性特征重要性度量,使用条件期望来定义简化输入。SHAP值的定义隐含了一个简化的输入映射,hx(z0) = zS,其中zS对于s集合中没有的特征有缺失值。由于大多数模型不能处理缺失输入值的任意模式,我们用E[f(z) | zS]来逼近f(zS)。SHAP值的定义被设计成与Shapley回归、Shapley抽样和定量输入影响特征属性紧密一致,同时也允许与LIME、DeepLIFT和分层关联传播的联系。
SHAP值的精确计算具有挑战性。然而,通过结合现有的加性特征归因方法,我们可以对它们进行近似。我们描述了两种模型不可知的近似方法,一种是已知的(Shapley采样值),另一种是新的(Kernel SHAP)。我们还描述了四种特定模型类型的近似方法,其中两种是新颖的(Max SHAP, Deep SHAP)。使用这些方法时,特征独立性和模型线性是简化期望值计算的两个可选假设(注意,S¯是不在S中的特征集):
Figure 1: SHAP (SHapley Additive exPlanation) values attribute to each feature the change in the expected model prediction when conditioning on that feature. They explain how to get from the base value E[f(z)] that would be predicted if we did not know any features to the current output f(x). This diagram shows a single ordering. When the model is non-linear or the input features are not independent, however, the order in which features are added to the expectation matters, and the SHAP values arise from averaging the φi values across all possible orderings.
图1:SHAP (SHapley加性解释)值属性为每个特征在满足该特征时预期模型预测中的变化。它们解释了如果我们不知道当前输出f(x)的任何特征,如何从基值E[f(z)]得到预测值。这个图显示了一个单一的顺序。然而,当模型是非线性的或输入特征不是独立的时,特征添加到期望中的顺序很重要,SHAP值来自于对所有可能的顺序的φi 值的平均。
4.1 Model-Agnostic Approximations
Model-Agnostic近似
If we assume feature independence when approximating conditional expectations (Equation 11), as in [9, 5, 7, 3], then SHAP values can be estimated directly using the Shapley sampling values method [9] or equivalently the Quantitative Input Influence method [3]. These methods use a sampling approximation of a permutation version of the classic Shapley value equations (Equation 8). Separate sampling estimates are performed for each feature attribution. While reasonable to compute for a small number of inputs, the Kernel SHAP method described next requires fewer evaluations of the original model to obtain similar approximation accuracy (Section 5).
如果我们在近似条件期望时假设特征独立性(式11),如[9,5,7,3],则可以直接使用Shapley采样值方法[9]或定量输入影响方法[3]估算SHAP值。这些方法使用经典Shapley值方程(方程8)的排列版本的抽样近似。对每个特征属性执行单独的抽样估计。虽然计算少量输入是合理的,但是下面描述的核形状方法需要对原始模型进行较少的评估,以获得类似的逼近精度(第5节)。
Kernel SHAP (Linear LIME + Shapley values)
Kernel SHAP(线性LIME + Shapley值)
Linear LIME uses a linear explanation model to locally approximate f, where local is measured in the simplified binary input space. At first glance, the regression formulation of LIME in Equation 2 seems very different from the classical Shapley value formulation of Equation 8. However, since linear LIME is an additive feature attribution method, we know the Shapley values are the only possible solution to Equation 2 that satisfies Properties 1-3 – local accuracy, missingness and consistency. A natural question to pose is whether the solution to Equation 2 recovers these values. The answer depends on the choice of loss function L, weighting kernel πx0 and regularization term Ω. The LIME choices for these parameters are made heuristically; using these choices, Equation 2 does not recover the Shapley values. One consequence is that local accuracy and/or consistency are violated, which in turn leads to unintuitive behavior in certain circumstances (see Section 5).
Linear LIME使用一个线性解释模型来局部逼近f,其中局部是在简化的二进制输入空间中度量的。乍一看,方程2中的LIME回归公式与经典的方程8的Shapley值公式有很大的不同。然而,由于线性LIME是一种加性特征属性的方法,我们知道Shapley值是等式2的唯一可能的解,满足特性1-3 -局部精度、缺失和一致性。人们自然会提出这样一个问题:方程式2的解决方案能否恢复这些价值?答案取决于损失函数的选择,权重内核πx0Ω和正则化项。这些参数的LIME选择是启发式的;使用这些选项,方程2不能恢复Shapley值。一个后果是局部准确性和/或一致性被违反,这反过来导致在某些情况下的非直觉行为(见第5节)。
Below we show how to avoid heuristically choosing the parameters in Equation 2 and how to find the loss function L, weighting kernel πx0 , and regularization term Ω that recover the Shapley values.
Theorem 2 (Shapley kernel) Under Definition 1, the specific forms of πx0 , L, and Ω that make solutions of Equation 2 consistent with Properties 1 through 3 are:
where |z 0 | is the number of non-zero elements in z 0 .
The proof of Theorem 2 is shown in the Supplementary Material.
It is important to note that πx0 (z 0 ) = ∞ when |z 0 | ∈ {0, M}, which enforces φ0 = fx(∅) and f(x) = PM i=0 φi . In practice, these infinite weights can be avoided during optimization by analytically eliminating two variables using these constraints.
Since g(z 0 ) in Theorem 2 is assumed to follow a linear form, and L is a squared loss, Equation 2 can still be solved using linear regression. As a consequence, the Shapley values from game theory can be computed using weighted linear regression.2 Since LIME uses a simplified input mapping that is equivalent to the approximation of the SHAP mapping given in Equation 12, this enables regression-based, model-agnostic estimation of SHAP values. Jointly estimating all SHAP values using regression provides better sample efficiency than the direct use of classical Shapley equations (see Section 5).
下面我们展示如何避免一些选择方程2中的参数和如何找到损失函数L,加权内核πx0,正则化项Ω夏普利值恢复。
定理2(ShapleyKernel )定义1,具体形式的πx0, L,和Ω方程2的解决方案符合1到3属性:
Ω(g) = 0,πx0 z (0) = (M−1)z (M z选择| 0 |)| 0 | (M−z | 0 |), L (f, g,πx0) = X z 0 z∈f (h−1 X z(0))−g (z 0) 2πx0 (z 0),
其中| z0 |为z0中非零元素的个数。
定理2的证明在补充材料中给出。
需要注意的是,当|z 0 |∈{0,M}时,x0 (z 0) =∞,这就使得x0 = fx(∅)和f(x) = PM i=0的isi。在实践中,这些无限权值可以避免在优化过程中分析消除两个变量使用这些约束。
由于假设定理2中的g(z0)是线性形式,而L是平方损失,所以方程2仍然可以用线性回归来求解。因此,从博弈论的Shapley值可以计算使用加权线性回归。2由于LIME使用了一个简化的输入映射,它等价于公式12中给出的SHAP映射的近似值,这使得基于回归的、不依赖模型的SHAP值估计成为可能。使用回归联合估计所有SHAP值比直接使用经典Shapley方程提供了更好的样本效率(见第5节)。
The intuitive connection between linear regression and Shapley values is that Equation 8 is a difference of means. Since the mean is also the best least squares point estimate for a set of data points, it is natural to search for a weighting kernel that causes linear least squares regression to recapitulate the Shapley values. This leads to a kernel that distinctly differs from previous heuristically chosen kernels (Figure 2A).
线性回归和Shapley值之间的直观联系是,方程8是平均值的差异。由于平均值也是一组数据点的最佳最小二乘点估计值,因此很自然地需要搜索一个加权核函数,它可以导致线性最小二乘回归来重新获得Shapley值。这将导致一个与之前启发式选择的内核明显不同的内核(图2A)。
4.2 Model-Specific Approximations
模型相关的近似
While Kernel SHAP improves the sample efficiency of model-agnostic estimations of SHAP values, by restricting our attention to specific model types, we can develop faster model-specific approximation methods.
虽然核形状提高了模型不可知的形状值估计的样本效率,但通过限制我们的注意力到特定的模型类型,我们可以开发更快的模型特定的近似方法。
Linear SHAP
For linear models, if we assume input feature independence (Equation 11), SHAP values can be approximated directly from the model’s weight coefficients.
This follows from Theorem 2 and Equation 11, and it has been previously noted by Štrumbelj and Kononenko [9].
Low-Order SHAP
Since linear regression using Theorem 2 has complexity O(2M + M3 ), it is efficient for small values of M if we choose an approximation of the conditional expectations (Equation 11 or 12).
线性SHAP
对于线性模型,如果我们假设输入特征独立性(方程11),SHAP值可以直接从模型的权重系数近似得到。
推论1(线性SHAP)给定线性模型
从定理2和方程11在此之前,它已经被Š前所述trumbelj和Kononenko[9]。
低阶SHAP
由于使用定理2的线性回归的复杂度为O(2M + M3),如果我们选择条件期望的近似值(方程11或12),那么它对于M的小值是有效的。
Figure 2: (A) The Shapley kernel weighting is symmetric when all possible z 0 vectors are ordered by cardinality there are 2 15 vectors in this example. This is distinctly different from previous heuristically chosen kernels. (B) Compositional models such as deep neural networks are comprised of many simple components. Given analytic solutions for the Shapley values of the components, fast approximations for the full model can be made using DeepLIFT’s style of back-propagation.
图2:(A) Shapley核加权是对称的,当所有可能的z0向量是由基数排序时,在这个例子中有2 15个向量。这与以前启发式选择的内核明显不同。(B)组成模型,如深度神经网络,是由许多简单组件组成的。给定组件Shapley值的解析解,可以使用DeepLIFT的反向传播方式对整个模型进行快速逼近。
Max SHAP
Using a permutation formulation of Shapley values, we can calculate the probability that each input will increase the maximum value over every other input. Doing this on a sorted order of input values lets us compute the Shapley values of a max function with M inputs in O(M2 ) time instead of O(M2M). See Supplementary Material for the full algorithm.
最大SHAP
使用Shapley值的置换公式,我们可以计算每个输入比其他输入增加最大值的概率。按照输入值的排序进行此操作,可以让我们在O(M2)时间内计算M个max函数的Shapley值,而不是O(M2M)。参见补充资料了解完整的算法。
Deep SHAP (DeepLIFT + Shapley values)
While Kernel SHAP can be used on any model, including deep models, it is natural to ask whether there is a way to leverage extra knowledge about the compositional nature of deep networks to improve computational performance. We find an answer to this question through a previously unappreciated connection between Shapley values and DeepLIFT [8]. If we interpret the reference value in Equation 3 as representing E[x] in Equation 12, then DeepLIFT approximates SHAP values assuming that the input features are independent of one another and the deep model is linear. DeepLIFT uses a linear composition rule, which is equivalent to linearizing the non-linear components of a neural network. Its back-propagation rules defining how each component is linearized are intuitive but were heuristically chosen. Since DeepLIFT is an additive feature attribution method that satisfies local accuracy and missingness, we know that Shapley values represent the only attribution values that satisfy consistency. This motivates our adapting DeepLIFT to become a compositional approximation of SHAP values, leading to Deep SHAP.
Deep SHAP combines SHAP values computed for smaller components of the network into SHAP values for the whole network. It does so by recursively passing DeepLIFT’s multipliers, now defined in terms of SHAP values, backwards through the network as in Figure 2B:
Deep SHAP (DeepLIFT + Shapley值)
虽然Kernel SHAP可以用于任何模型,包括深度模型,但我们很自然地会问,是否有一种方法可以利用关于深度网络组成特性的额外知识来提高计算性能。我们通过Shapley值和DeepLIFT[8]之间先前未被重视的联系找到了这个问题的答案。如果我们将公式3中的参考值解释为公式12中的E[x],则DeepLIFT近似SHAP值,假设输入特征是相互独立的,深模型是线性的。DeepLIFT使用线性组合规则,这相当于线性化一个神经网络的非线性成分。它的反向传播规则定义了如何将每个分量线性化是直观的,但是启发式地选择的。由于DeepLIFT是一种满足局部精度和缺失性的加性特征属性方法,我们知道Shapley值代表了唯一满足一致性的属性值。这促使我们适应DeepLIFT,成为SHAP值的合成近似值,从而形成了Deep SHAP。
深度SHAP将网络中较小组件的SHAP值合并为整个网络的SHAP值。它通过递归传递DeepLIFT的乘数,现在定义为SHAP值,向后通过网络,如图2B所示:
Since the SHAP values for the simple network components can be efficiently solved analytically if they are linear, max pooling, or an activation function with just one input, this composition rule enables a fast approximation of values for the whole model. Deep SHAP avoids the need to heuristically choose ways to linearize components. Instead, it derives an effective linearization from the SHAP values computed for each component. The max function offers one example where this leads to improved attributions (see Section 5).
由于简单网络组件的SHAP值可以有效地解析求解,如果它们是线性的、最大池化的或只有一个输入的激活函数的,这个组合规则允许对整个模型的值进行快速逼近。深度SHAP避免了启发式地选择线性化组件的方法的需要。相反,它从为每个组件计算的SHAP值得到有效的线性化。max函数提供了一个例子,在这个例子中可以改进属性(见第5节)。
Figure 3: Comparison of three additive feature attribution methods: Kernel SHAP (using a debiased lasso), Shapley sampling values, and LIME (using the open source implementation). Feature importance estimates are shown for one feature in two models as the number of evaluations of the original model function increases. The 10th and 90th percentiles are shown for 200 replicate estimates at each sample size. (A) A decision tree model using all 10 input features is explained for a single input. (B) A decision tree using only 3 of 100 input features is explained for a single input.
图3:比较三种附加特性属性方法:Kernel SHAP(使用去偏套索)、Shapley采样值和LIME(使用开源实现)。随着原始模型函数的评估数量的增加,在两个模型中显示一个特征的特征重要性估计值。第10百分位数和第90百分位数显示了200个重复估计在每个样本大小。(A)一个决策树模型使用所有10个输入特征解释单一输入。(B)对于单个输入,说明一个决策树只使用100个输入特征中的3个。
5 Computational and User Study Experiments
计算和用户研究实验
We evaluated the benefits of SHAP values using the Kernel SHAP and Deep SHAP approximation methods. First, we compared the computational efficiency and accuracy of Kernel SHAP vs. LIME and Shapley sampling values. Second, we designed user studies to compare SHAP values with alternative feature importance allocations represented by DeepLIFT and LIME. As might be expected, SHAP values prove more consistent with human intuition than other methods that fail to meet Properties 1-3 (Section 2). Finally, we use MNIST digit image classification to compare SHAP with DeepLIFT and LIME.
我们评估了利用Kernel SHAP和Deep SHAP近似方法的SHAP值的好处。首先,我们比较了Kernel SHAP与LIME和Shapley采样值的计算效率和精度。其次,我们设计了用户研究来比较SHAP值和其他特征重要性分配,如DeepLIFT和LIME。正如预期的那样,SHAP值被证明比其他无法满足属性1-3的方法更符合人类直觉(第2节)。最后,我们使用MNIST数字图像分类将SHAP与DeepLIFT和LIME进行比较。
5.1 Computational Efficiency
计算效率
Theorem 2 connects Shapley values from game theory with weighted linear regression. Kernal SHAP uses this connection to compute feature importance. This leads to more accurate estimates with fewer evaluations of the original model than previous sampling-based estimates of Equation 8, particularly when regularization is added to the linear model (Figure 3). Comparing Shapley sampling, SHAP, and LIME on both dense and sparse decision tree models illustrates both the improved sample efficiency of Kernel SHAP and that values from LIME can differ significantly from SHAP values that satisfy local accuracy and consistency.
定理2将博弈论中的Shapley值与加权线性回归联系起来。Kernal SHAP使用这种连接来计算特征的重要性。这导致更精确的估计,用更少的原始模型的评估比先前sampling-based 8的估计方程,特别是当正规化添加到线性模型(图3)。Shapley抽样比较,SHAP,LIME稠密和稀疏的决策树模型说明了改进后的样品的效率值的Kernel SHAP和LIME可以明显的区别于SHAP值满足当地的准确性和一致性。
5.2 Consistency with Human Intuition
符合人类直觉
Theorem 1 provides a strong incentive for all additive feature attribution methods to use SHAP values. Both LIME and DeepLIFT, as originally demonstrated, compute different feature importance values. To validate the importance of Theorem 1, we compared explanations from LIME, DeepLIFT, and SHAP with user explanations of simple models (using Amazon Mechanical Turk). Our testing assumes that good model explanations should be consistent with explanations from humans who understand that model.
We compared LIME, DeepLIFT, and SHAP with human explanations for two settings. The first setting used a sickness score that was higher when only one of two symptoms was present (Figure 4A). The second used a max allocation problem to which DeepLIFT can be applied. Participants were told a short story about how three men made money based on the maximum score any of them achieved (Figure 4B). In both cases, participants were asked to assign credit for the output (the sickness score or money won) among the inputs (i.e., symptoms or players). We found a much stronger agreement between human explanations and SHAP than with other methods. SHAP’s improved performance for max functions addresses the open problem of max pooling functions in DeepLIFT [7].
定理1强烈鼓励所有加性特征属性方法使用SHAP值。正如最初演示的那样,LIME和DeepLIFT都可以计算不同的特征重要度值。为了验证定理1的重要性,我们将来自LIME、DeepLIFT和SHAP的解释与用户对简单模型的解释(使用Amazon Mechanical Turk)进行了比较。我们的测试假设好的模型解释应该与理解该模型的人的解释一致。
我们比较了LIME、DeepLIFT和SHAP与人类对两种设置的解释。第一组使用的疾病评分在两种症状中只有一种出现时更高(图4A)。第二种方法使用了一个可以应用DeepLIFT的最大分配问题。参与者被告知一个关于三个男人如何根据他们中的任何一个人获得的最高分赚钱的小故事(图4B)。在这两种情况下,参与者被要求为输入(即症状或玩家)中的输出(疾病分数或赢得的钱)分配分数。我们发现人类的解释与SHAP之间的一致性比其他方法要强得多。SHAP对max函数性能的改进解决了DeepLIFT[7]中max池函数的开放问题。
5.3 Explaining Class Differences
解释分类差异
As discussed in Section 4.2, DeepLIFT’s compositional approach suggests a compositional approximation of SHAP values (Deep SHAP). These insights, in turn, improve DeepLIFT, and a new version includes updates to better match Shapley values [7]. Figure 5 extends DeepLIFT’s convolutional network example to highlight the increased performance of estimates that are closer to SHAP values. The pre-trained model and Figure 5 example are the same as those used in [7], with inputs normalized between 0 and 1. Two convolution layers and 2 dense layers are followed by a 10-way softmax output layer. Both DeepLIFT versions explain a normalized version of the linear layer, while SHAP (computed using Kernel SHAP) and LIME explain the model’s output. SHAP and LIME were both run with 50k samples (Supplementary Figure 1); to improve performance, LIME was modified to use single pixel segmentation over the digit pixels. To match [7], we masked 20% of the pixels chosen to switch the predicted class from 8 to 3 according to the feature attribution given by each method.
如4.2节所讨论的,DeepLIFT的组分方法建议对形状值进行组分近似(Deep SHAP)。这些见解反过来改进了DeepLIFT,新版本包括更新以更好地匹配Shapley值[7]。图5扩展了DeepLIFT的卷积网络示例,以突出显示更接近SHAP值的估计所增加的性能。预训练的模型和图5示例与[7]中使用的相同,其输入在0和1之间规范化。两个卷积层和2个密集层之后是一个10路softmax输出层。两个DeepLIFT版本都解释了线性层的规范化版本,而SHAP(使用Kernel SHAP计算)和LIME解释了模型的输出。SHAP和LIME均在50k样品中运行(补充图1);为了提高性能,LIME被修改为对数字像素使用单一像素分割。为了匹配[7],我们根据每种方法给出的特征属性,对选择的将预测类从8切换到3的像素的20%进行掩蔽。
Figure 4: Human feature impact estimates are shown as the most common explanation given among 30 (A) and 52 (B) random individuals, respectively.
(A) Feature attributions for a model output value (sickness score) of 2. The model output is 2 when fever and cough are both present, 5 when only one of fever or cough is present, and 0 otherwise.
(B) Attributions of profit among three men, given according to the maximum number of questions any man got right. The first man got 5 questions right, the second 4 questions, and the third got none right, so the profit is $5.
图4:分别在30 (A)和52 (B)随机个体中,最常见的解释是人类特征影响估计。
(A)模型输出值(疾病得分)为2的特征属性。当同时出现发烧和咳嗽时,模型输出为2,只有发烧或咳嗽一种时输出为5,其余输出为0。
(B)根据每个人所答对的问题的最大数量,由三个人来确定利益的归属。第一个人答对了5道题,第二个答对了4道题,第三个没答对,所以利润是5美元。
Figure 5: Explaining the output of a convolutional network trained on the MNIST digit dataset. Orig. DeepLIFT has no explicit Shapley approximations, while New DeepLIFT seeks to better approximate Shapley values.
(A) Red areas increase the probability of that class, and blue areas decrease the probability. Masked removes pixels in order to go from 8 to 3.
(B) The change in log odds when masking over 20 random images supports the use of better estimates of SHAP values.
图5:解释在MNIST数字数据集上训练的卷积网络的输出。DeepLIFT没有明确的Shapley近似,而New DeepLIFT寻求更好的近似Shapley值。
(A)红色区域增加该类的概率,蓝色区域减少该类的概率。为了从8到3去除像素。
(B)当掩蔽超过20幅随机图像时,日志概率的变化支持更好地估计SHAP值。
6 Conclusion
The growing tension between the accuracy and interpretability of model predictions has motivated the development of methods that help users interpret predictions. The SHAP framework identifies the class of additive feature importance methods (which includes six previous methods) and shows there is a unique solution in this class that adheres to desirable properties.
The thread of unity that SHAP weaves through the literature is an encouraging sign that common principles about model interpretation can inform the development of future methods.
We presented several different estimation methods for SHAP values, along with proofs and experiments showing that these values are desirable. Promising next steps involve developing faster model-type-specific estimation methods that make fewer assumptions, integrating work on estimating interaction effects from game theory, and defining new explanation model classes.
模型预测的准确性和可解释性之间的紧张关系推动了帮助用户解释预测的方法的发展。SHAP框架确定了附加特征重要性方法的类别(包括以前的6个方法),并表明在该类中有一个唯一的解决方案,它符合需要的属性。
SHAP在文献中统一的线索是一个令人鼓舞的信号,表明有关模型解释的通用原理可以为将来方法的发展提供信息。
我们提出了几种不同的SHAP值估计方法,并通过证明和实验表明这些值是可取的。有希望的下一步包括开发更快的模型-特定类型的估计方法,使假设更少,整合从博弈论中估算交互作用的工作,并定义新的解释模型类。
Acknowledgements
This work was supported by a National Science Foundation (NSF) DBI-135589, NSF CAREER DBI-155230, American Cancer Society 127332-RSG-15-097-01-TBG, National Institute of Health (NIH) AG049196, and NSF Graduate Research Fellowship. We would like to thank Marco Ribeiro, Erik Štrumbelj, Avanti Shrikumar, Yair Zick, the Lee Lab, and the NIPS reviewers for feedback that has significantly improved this work.
这项工作得到了美国国家科学基金会(NSF) DBI-135589、NSF CAREER DBI-155230、美国癌症学会127332-RSG-15-097-01-TBG、美国国家卫生研究院(NIH) AG049196和NSF研究生研究奖学金的支持。我们要感谢Marco Ribeio, Erik Štrumbelj, Avanti Shrikumar, Yair Zick, Lee实验室,和NIPS 的评论反馈,大大提高这项工作。