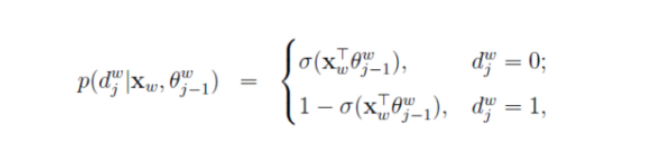🔔理论参考: Word2Vec Tutorial - The Skip-Gram Model
Word2vec原理-刘建平博客
理解 Word2Vec 之 Skip-Gram 模型
Ⅰ.Word2Vec理论部分
introduction
机器是处理向量信息的,如果想要处理自然语言中的词句信息,就要找到一个办法将单词信息转化为向量信息,这个转化的过程被称为词向量嵌入。
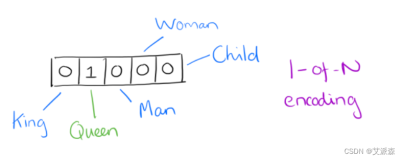
给定一篇文章,文章中所有单词组成的集合称为一个词典,如果对文章中的每个单词以向量的形式表示,最显然的方法即为设定该向量的维度为该词典的总单词数,每个单词以某个位置为1,其他位置均为0的向量表示。(这样的表示方法被叫做one-hot)这样就可以把一篇文章中所有的单词转为向量表示形式。
但是这种方法存在一个明显的缺陷:浪费了大量的空间。如果想办法既可以减小向量的维度,又可以将单词所代表的各种特征信息蕴含在向量里,则可以有效的解决这个问题。
假设词典中总词数为V,定义一个rep_size作为最终我们要的词向量的维度数,起始的onehot向量是1×V的,最终我们要的是1×rep_size的,那么我们需要一个V×repsize的矩阵作为‘桥梁’来进行这种转化,这个矩阵被称为嵌入矩阵,我们所要训练得到的矩阵也就是这个嵌入矩阵。
训练过程
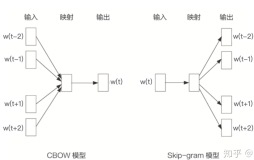
文章中提出了两种训练该嵌入矩阵的模型,一是CBOW,另一个是SKIP-GRAM,前着是希望通过一个中心词的周围几个词来预测中心词,后者则是通过中心词来预测周围词,这两种方法在本质上没有区别,在选取负样本以及训练优化的过程有少许差异,后面遇到了会进行区分和说明。
在传统的深度学习网络中,在已知输入输出以及要优化的参数及目标后,可以使用参考DNN相关知识(前向传播算法,反向传播算法)进行训练得到所要的嵌入矩阵。但是DNN模型的处理过程非常耗时:词嵌入问题的词汇表一般在百万级别以上,这意味着DNN的输出层需要进行softmax计算各个词的输出概率的的计算量很大。因此要找一个更好的优化算法来加速训练。
优化嵌入矩阵有两种加速训练的方法。一是基于Hierarchical Softmax,一是基于negtive sampling
a.基于Hierarchical Softmax的加速
首先把所有单词在文章中存在的词频计算出来,按构造霍夫曼树的方法将每个单词放到合适的叶子结点位置,该霍夫曼树的中间节点则存储着参数信息,给定一个样本,该样本中包含一个中心词w0和2c个窗口词,先将这2c+1个单词投影到对应的2c+1个词向量。
由于是二叉树,之前计算量为V,现在变成了log2V(V个叶子结点的霍夫曼树共有2n-1个结点,且平衡的霍夫曼树高度为log2V,这样一来,计算的次数就变成了log2V)。且由于使用霍夫曼树是高频的词靠近树根,这样高频词需要更少的时间会被找到,这符合贪心优化思想。
CBOW模型
该树的根结点代表这2c个窗口单词词向量的均值(即所有向量相加除以窗口大小),得到一个xw向量,到达中心词w0的路径上的若干个中间节点也对应着各参数,将xw与这些参数分别相乘,得到的结果再分别sigmod一下,若是得到的值大于0.5,则表明是正项,否则则是负项。具体举例来说:
下图中w2是中心词,也就是训练样本的输出部分,我们期望在n(w2,1)节点处左子树概率较大,而在n(w2,2)处期待左子树概率较大,如果定义左子树为负类,右子树为正类,定义正负类概率如下(其中 为样本的输入词向量,
为样本的输入词向量, 为当前节点的参数(对于树的每个中间节点均有此参数)):
为当前节点的参数(对于树的每个中间节点均有此参数)):

根据上面的描述,我们所要优化的目标就变成下列式子:优化参数 ,
, 使得该函数最大化,若是在测试的时候再输入这个
使得该函数最大化,若是在测试的时候再输入这个 时,经过这个树的每个节点参数判断后就可以得到最接近w2的输出结果,也就达到了我们希望用上下文预测中心词的目的。
时,经过这个树的每个节点参数判断后就可以得到最接近w2的输出结果,也就达到了我们希望用上下文预测中心词的目的。

为了更好地描述这个模型,对这个模型进一步抽象化,定义:
- 一个样本的输入输出组成为
 (上下文,中心词)
(上下文,中心词) - 样本的输入层词向量求和平均后的霍夫曼树根节点词向量为

- 从根节点到输出的节点总数为

 的霍夫曼编码在中间节点的霍夫曼编码表示为
的霍夫曼编码在中间节点的霍夫曼编码表示为 ,对应的节点为
,对应的节点为 (对于上图来说,w2在节点n(w123,2)所对应的霍夫曼编码就为110)
(对于上图来说,w2在节点n(w123,2)所对应的霍夫曼编码就为110)- 中间节点的逻辑回归概率表示为

- 整个样本的训练目标就为最大化该似然函数

 (对数似然函数表达)
(对数似然函数表达)
CBOW模型梯度计算
梯度下降参考链接
可以简单地理解对数似然函数L有两个变量 ,要进行梯度上升以找到L的最大值。
,要进行梯度上升以找到L的最大值。
将目标函数变为:
这样要进行梯度下降法来找到 的最小值
的最小值
- 对
 求偏导(下式中j在2...lw)
求偏导(下式中j在2...lw)
- 对
 求导(CBOW中
求导(CBOW中 是由2c个窗口词向量求和平均得到,因此在后面的梯度下降过程中会直接更新
是由2c个窗口词向量求和平均得到,因此在后面的梯度下降过程中会直接更新 )
)

因此计算出更新后的梯度后,参数所要进行的更新如下, 是步长,所要更新的参数为
是步长,所要更新的参数为 ,
,

(在复现的过程中,得到了损失函数,也知道要更新的参数,利用已有的Adam,SGD等可以自动更新参数,但是为了更好地理解其中的原理和该奶奶,在这里知道怎么进行梯度下降也很重要。)
SKIPGRAM模型
给定的是中心词,要求预测窗口内单词,路径要么是将中心词词向量作为输入到根结点的向量,要么将窗口内的某一单词作为输入到根结点的向量,这样最后更新的还是窗口单词的向量表示,这两种方式的本质并无差别,目的都是为了提高最后的词向量表示中,这两者更靠近。(选择后者的原因在于这样可以在一个输入样本中得到更多词向量的更新,这样一来SKIPGRAM下的Hierarchical加速就变成了对样本中输出词的词向量进行更新了,而不是像CBOW那样对输入词的词向量进行更新)
SKIP-GRAM的输入输出样本为 (中心词,上下文)
(中心词,上下文)
这样,举例来说,对于其中一对 ,分别作输入到根节点的向量和目的叶子节点,SKIP-GRAM模型的对数似然函数表达为
,分别作输入到根节点的向量和目的叶子节点,SKIP-GRAM模型的对数似然函数表达为
只是其中的 应该为样本的输出部分的一个单词对应的词向量,而
应该为样本的输出部分的一个单词对应的词向量,而 以及对应的霍夫曼编码的选择则是由输入的中心词
以及对应的霍夫曼编码的选择则是由输入的中心词 决定的。
决定的。
怎么利用这些样本进行训练我们要的嵌入矩阵以及霍夫曼树的节点参数?(这里可以看出我们所要求得的其实是两大参数,也就相当于后面采用负采样时所需要求的embedding和context_embedding)
在了解了如上的更新原理后,下面需要讨论的就是如何构建似然函数,用逻辑回归的方法进行更新参数和嵌入矩阵。
SKIP-GRAM梯度计算
和CBOW模型梯度计算基本一致,不同在于给定一个样本要进行一对一对找到参数并更新,不过由于霍夫曼树对应的路径是一致的,会减少很多麻烦。
b.基于Negative Sampling的加速
在Hierarchical Softmax加速方法中,存在对生僻词处理的问题,如果目标词是一个出现频率很低的词,那么要找到并计算似然函数就变得很复杂,为了解决这一问题,引入负采样的方法。
CBOW模型
先以CBOW模型为例,还是按照上面的方法取 和
和 ,组成一个样本
,组成一个样本 ,
, 视作中心词,其余则是上下文窗口词。上下文
视作中心词,其余则是上下文窗口词。上下文 和中心词
和中心词 存在着相关性,因此这可以视作一个正例,为了提升效果,还需要任意取neg个与中心词不同的词
存在着相关性,因此这可以视作一个正例,为了提升效果,还需要任意取neg个与中心词不同的词 作为负例,尽可能减少
作为负例,尽可能减少 和
和 的相关性。
的相关性。
同样的,先计算所有上下文单词对应的词向量的求和均值 ,以及所有正例以及负例的词向量表示
,以及所有正例以及负例的词向量表示 。(这表明
。(这表明 和
和 是分别用两个矩阵投影映射而来的。)
是分别用两个矩阵投影映射而来的。)
正例 对应的逻辑回归概率为
对应的逻辑回归概率为
负例 对应的逻辑回归概率为
对应的逻辑回归概率为
有了前面的基础,理解起来这个就显得更加容易,将所有的正例负例的逻辑回归概率相乘就可以得到似然函数:
负对数似然函数为:
接着按照梯度下降的方法更新 和
和 。以此来更新对应的两个嵌入矩阵。
。以此来更新对应的两个嵌入矩阵。

因此计算出更新后的梯度后,参数所要进行的更新如下, 是步长,所要更新的是
是步长,所要更新的是


SKIP-GRAM模型
不同于CBOW,该模型所给的样本是一个中心词和多个上下文词,为了实现负样本采样的效果,需要再随机采样几个不在此窗口的单词作为负样本,取(中心词,窗口内的1个词,neg个负样本)组成样本
参考CBOW负采样的似然函数,可以得到这里的似然函数应当为(其中 为
为 在context矩阵的映射):
在context矩阵的映射):
由此,如果将窗口扩大至2c,似然函数则变为:
负对数似然函数为:
Ⅱ.代码复现部分
SKIP-GRAM模型
- 语言:python3
- 框架:pytorch
- 线上编辑器和线上CPU资源:Colab
起初参考的是知乎文章 基于TensorFlow实现Skip-Gram模型,是用tensorflow实现的,再仔细阅读代码并学习了pytorch构建动态图的方法后,尝试用pytorch实现skip-gram模型。(Github链接)
在参考的tf版代码中,所用的负采样是已有的,只需要将相关参数传入,即可实现负采样并计算loss,再采用adam优化算法,实现梯度下降优化目标embedding。而在pytorch中则无,故要自己构建loss函数,并在构造batch过程中实现负采样。再用adam优化算法实现梯度下降。最后随机选取16个词,找到各自最接近的8个词,以直观地验证训练的效果。
下面是代码整体解释:(代码见链接:Colab)
核心1:loss函数的确定
参考(negative-sampling 的公式推导) :
word2vec Explained: deriving Mikolov et al.'s negative-sampling word-embedding method
知乎专栏:skip-gram
上面的部分已经找到了负对数似然函数,这就是需要进行梯度下降的目标
参考这个化简的方法
可以找到需要的损失函数且与下面这个负对数似然函数有着同样的精髓
对于 ,
, 对应正例,则sign=1;
对应正例,则sign=1; 对应负例,则sign=-1,将所有取得的样本求和平均,即可得到loss损失函数
对应负例,则sign=-1,将所有取得的样本求和平均,即可得到loss损失函数
对应代码里的:
train_loss=-torch.sum(lgS(torch.multiply(self.x_e,self.y_e*self.sign)))核心2:负采样的方法以及效果
使用 一元模型分布 (unigram distribution) 来选择 negative words,一个单词被选作 negative sample 的概率跟它出现的频次有关,出现频次越高的单词越容易被选作negative words,经验公式为:

以此作为单词表中的vi的词频,根据词频决定被选中的概率。取M为108,将1分为M份,每个单词都占属于自己的P(vi)*M份,随机选取其中的neg份,neg份各自所在的单词区间即为选中的。
在代码实现过程中使用了torch.multinomial,可以根据权重随机选择一定数目的值。
但是这里没有避免可能会选到与中心词重合的问题。
其他
在复现的过程中附带了看了下以下内容:
关于batch_size的选择:可以参考多篇知乎回答:链接
关于adam优化算法的理解以及各种优化算法的比较:链接
一些调参经验:链接[
](https://www.cnblogs.com/pinard/p/7249903.html) 采用的是数据集Javasplittedwords
是某中文招聘网站上的数据
作为词向量嵌入的重要模型,这里最重要的是理解整个的原理,我在复现的过程中可以大概地看到相邻近词的效果,例如下面截图中,专心和迅速,勤奋这一类词常常出现在对应聘者的要求中,常常会一起出现(但是语料规模较小,因此效果并不是很好) [
[
](https://www.cnblogs.com/pinard/p/7249903.html)
CBOW模型复现
只要修改下batch的获取方法,修改下loss函数即可。
一些小的记录点:
- pytorch中要更新的参数tensor要有require_grad=True,并且在后续调用该tensor可能需要以.detach()来去除该属性
-