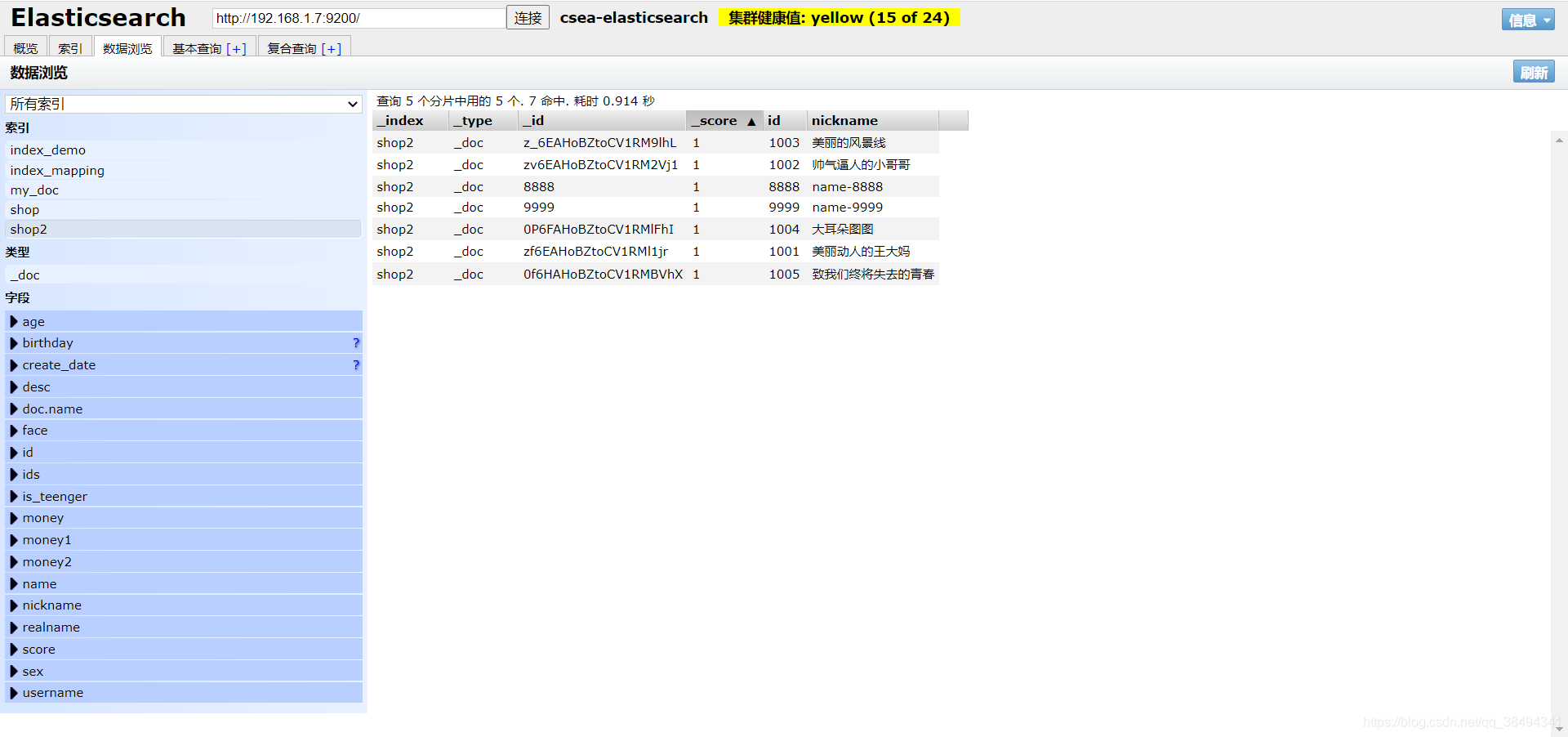
准备工作
新建一个shop索引,并添加mappings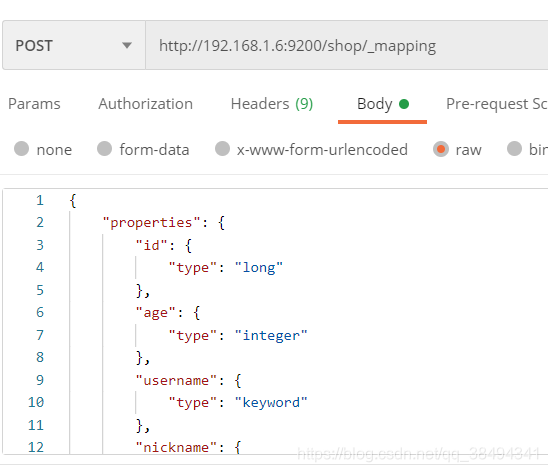
{
"properties": {
"id": {
"type": "long"
},
"age": {
"type": "integer"
},
"username": {
"type": "keyword"
},
"nickname": {
"type": "text"
},
"money": {
"type": "float"
},
"desc": {
"type": "text",
"analyzer": "ik_max_word"
},
"sex": {
"type": "byte"
},
"birthday": {
"type": "date"
},
"face": {
"type": "text",
"index": false
}
}
}数据准备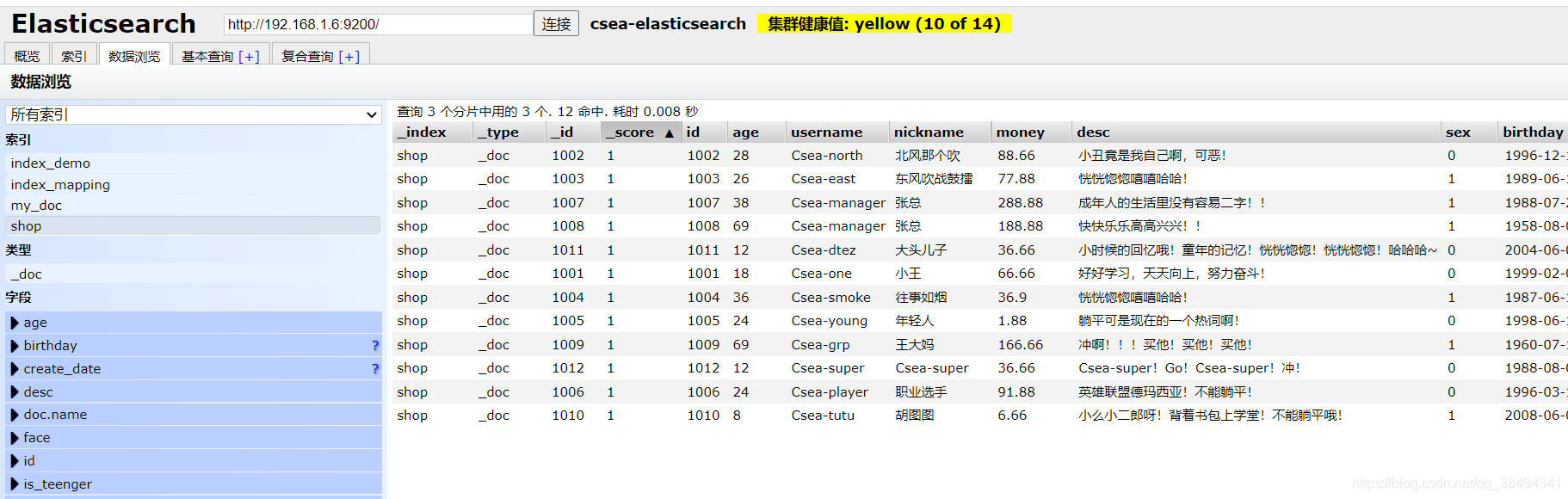
QueryString数据查询
Get请求:http://{IP}:{port}/{索引名称}/_search?q={字段field}:{搜索内容}
多条件查询:
Get请求:http://{IP}:{port}/{索引名称}/_search?q={字段field}:{搜索内容}&q={字段field}:{搜索内容}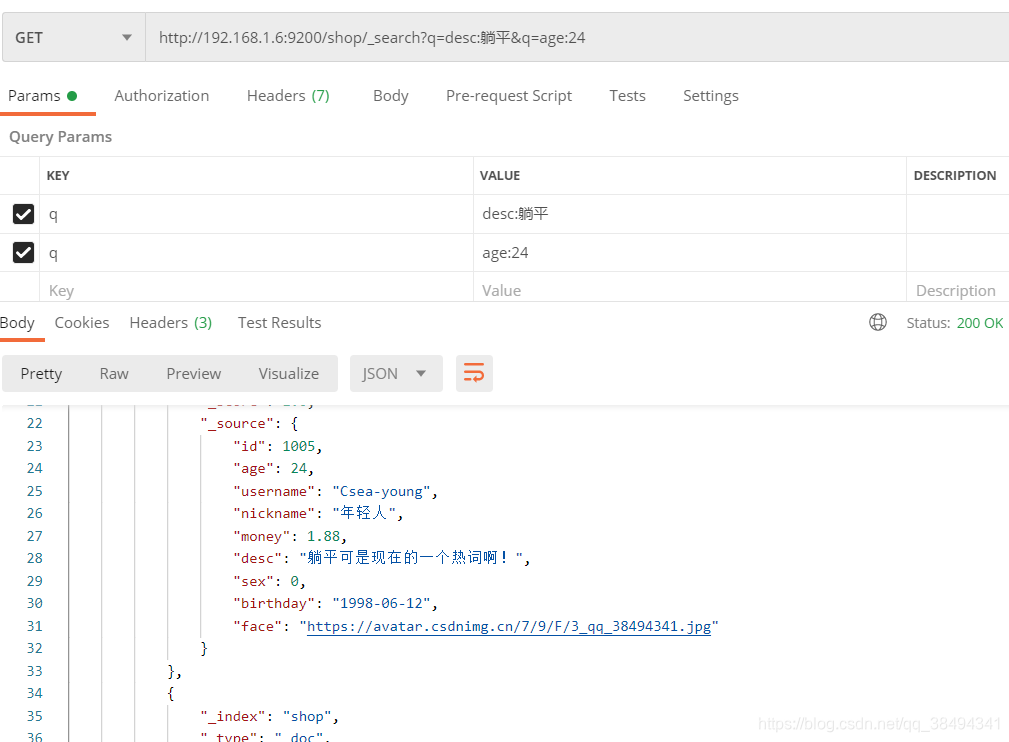
dsl数据查询
match搜索
Post请求:http://{IP}:{port}/{索引名称}/_doc/_search
就是与q={字段field}:{搜索内容}相同功能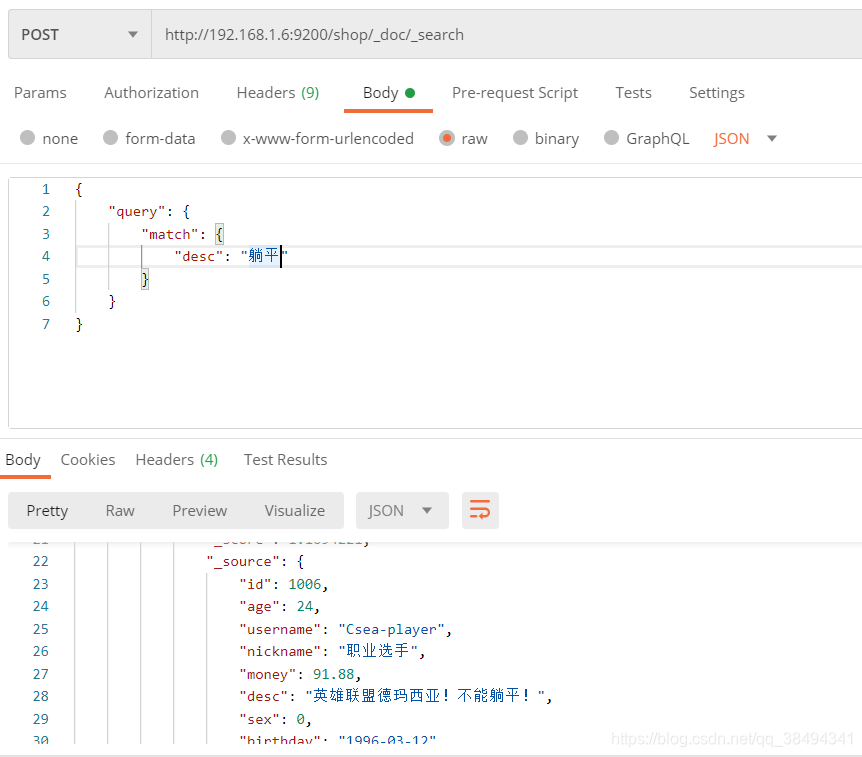
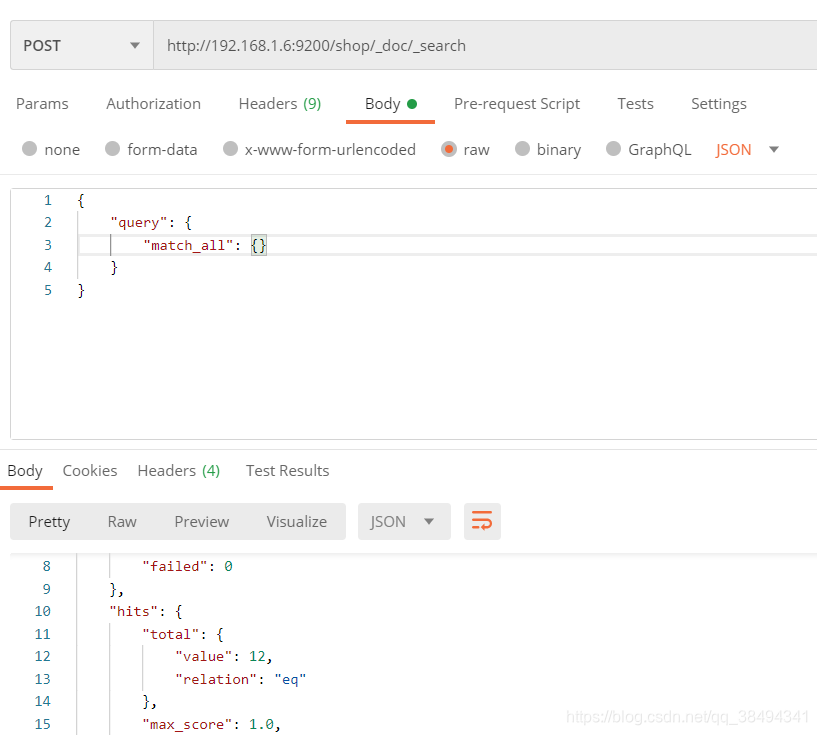
查询所有
指定字段查询
增加_source搜索条件,往数组中添加自己需要的字段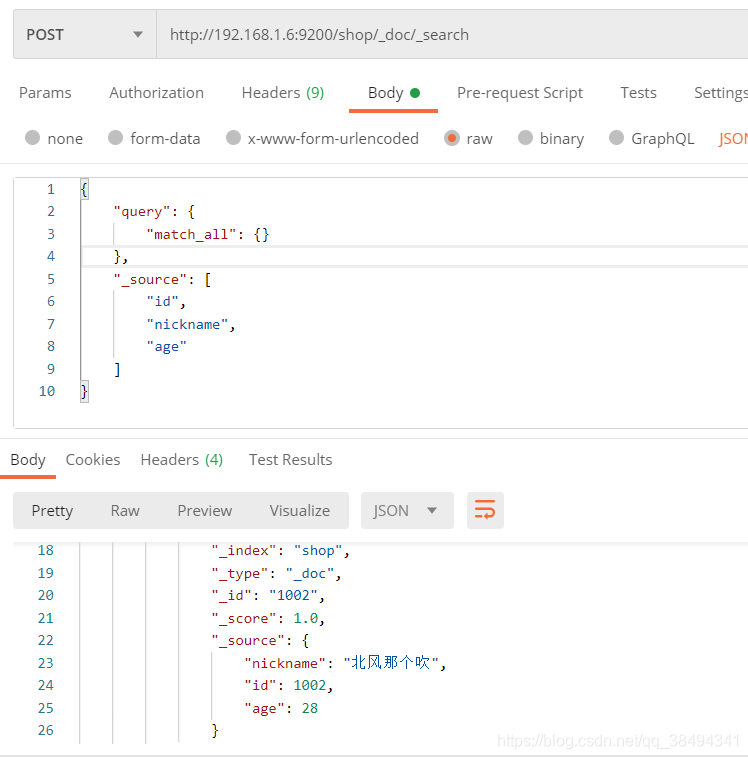
分页搜索
增加from、size查询条件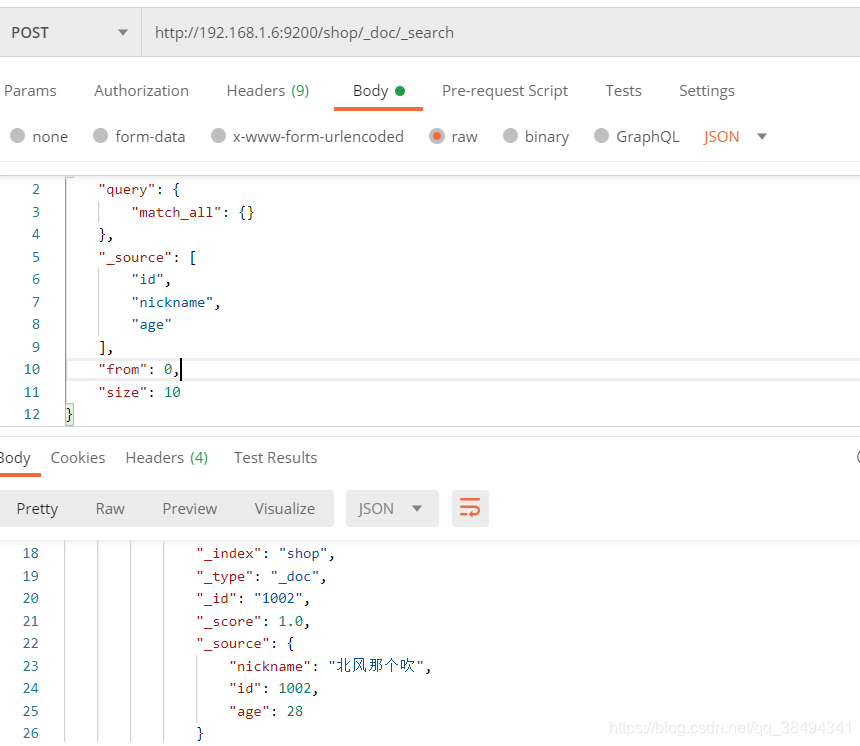
exists搜索
判断某个字段是否存在,存在的话就把数据返回回来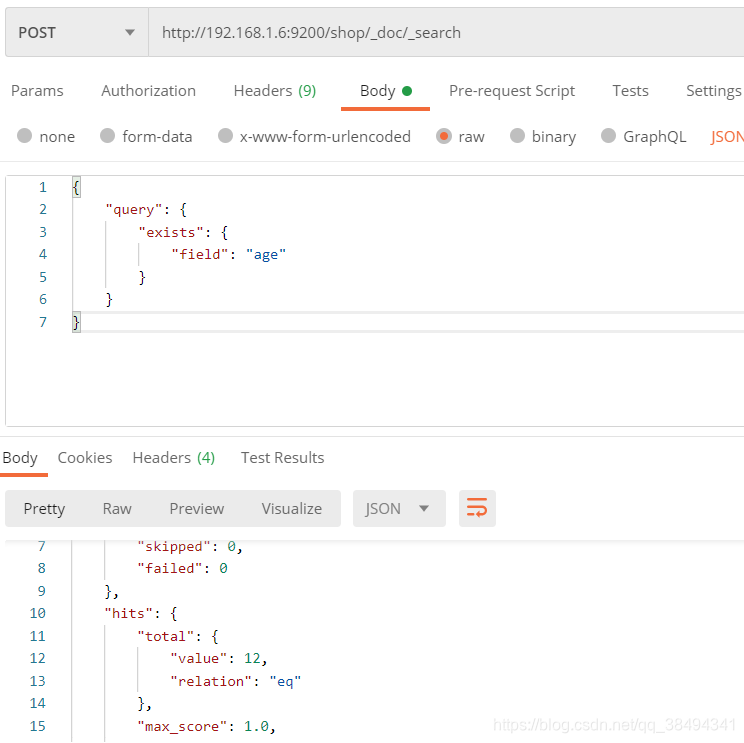
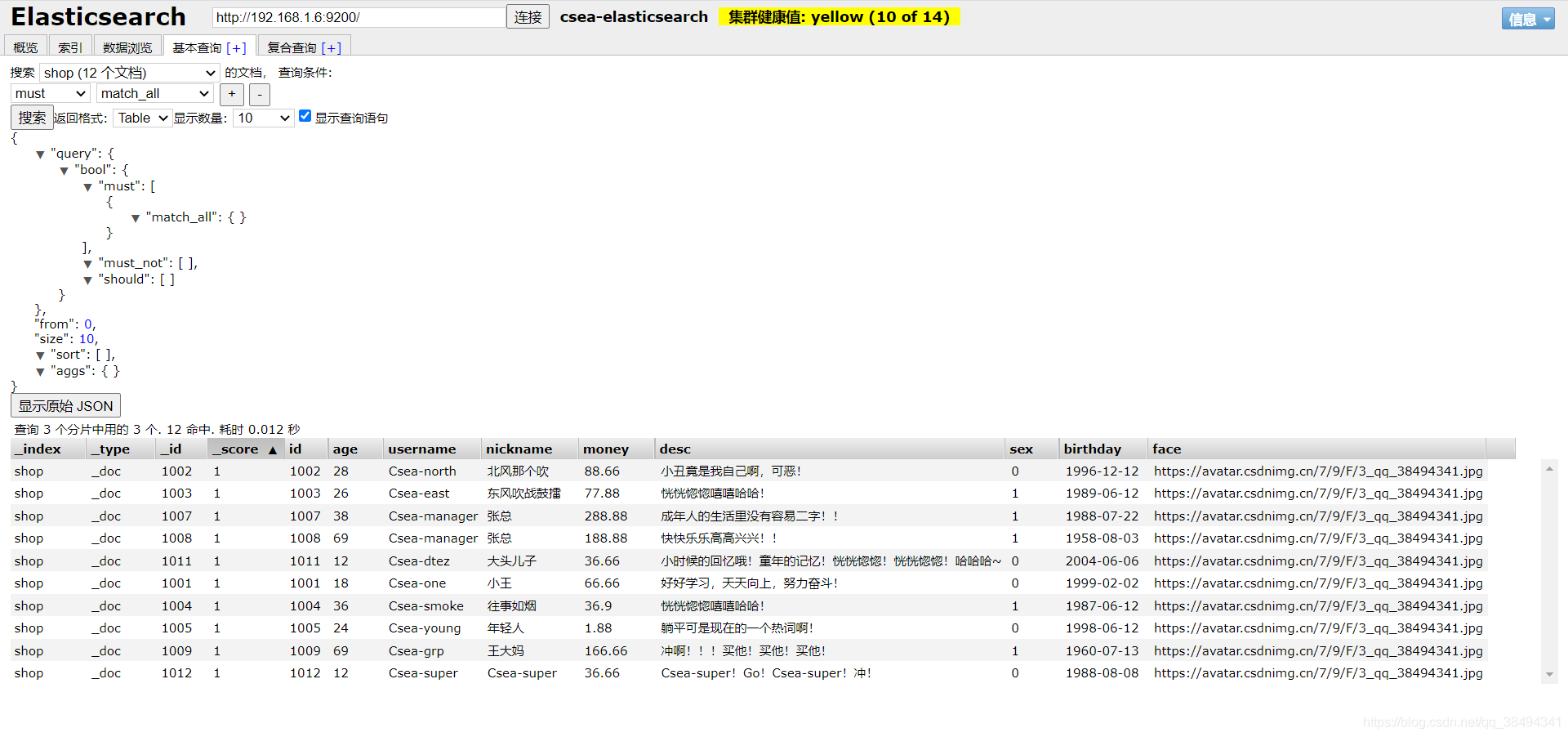
可视化界面查询
term和match
term
term是把字段当做keyword,不会进行分词
如下:
二字就是一个分词,会去匹配desc中包含“二字”的内容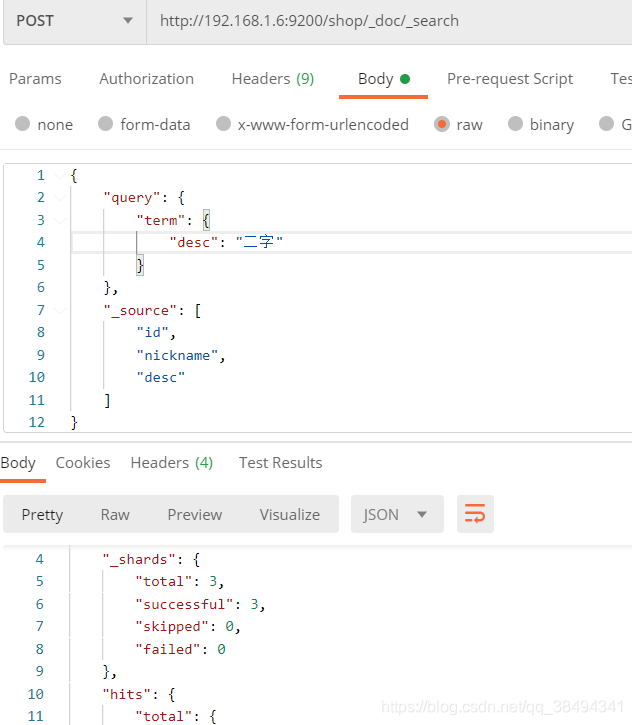
terms
传入一个数组,去匹配desc包含“快快乐乐” 或 “高高兴兴”的内容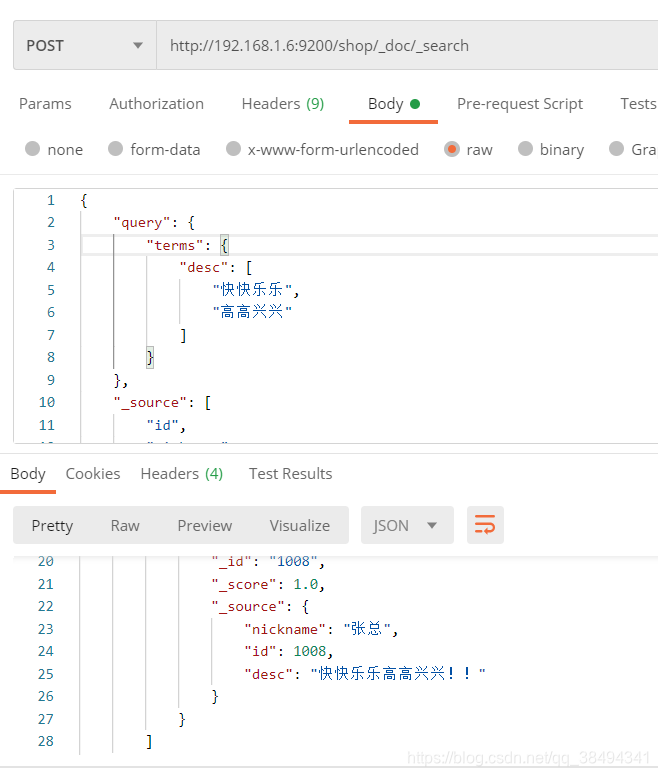
match
match会把字段的内容进行分词
如下,会把二字分词为二,词,二词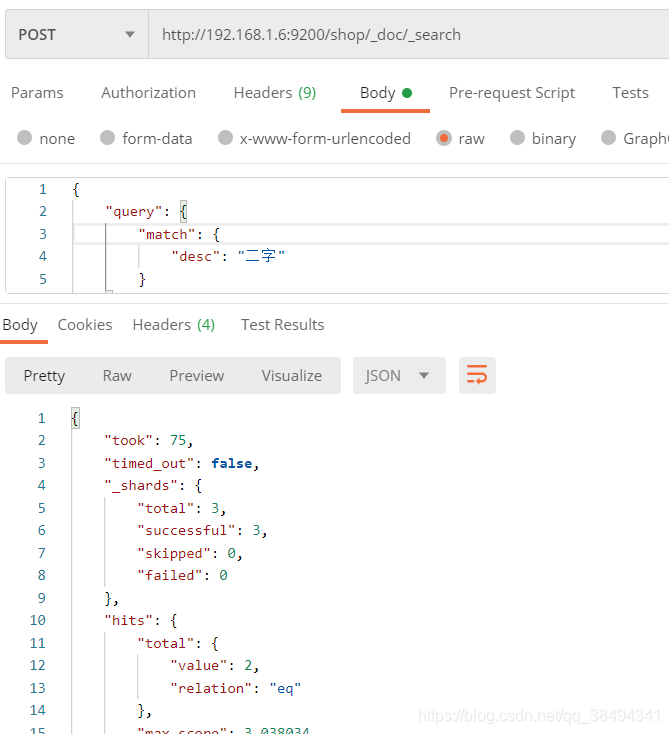
match_phrase
"query":"恍恍惚惚 嘻嘻哈哈"的意思表达是,我所匹配的内容中,必须是连贯的,比如恍恍惚惚后面必须紧跟的是嘻嘻哈哈,否则是不会匹配到的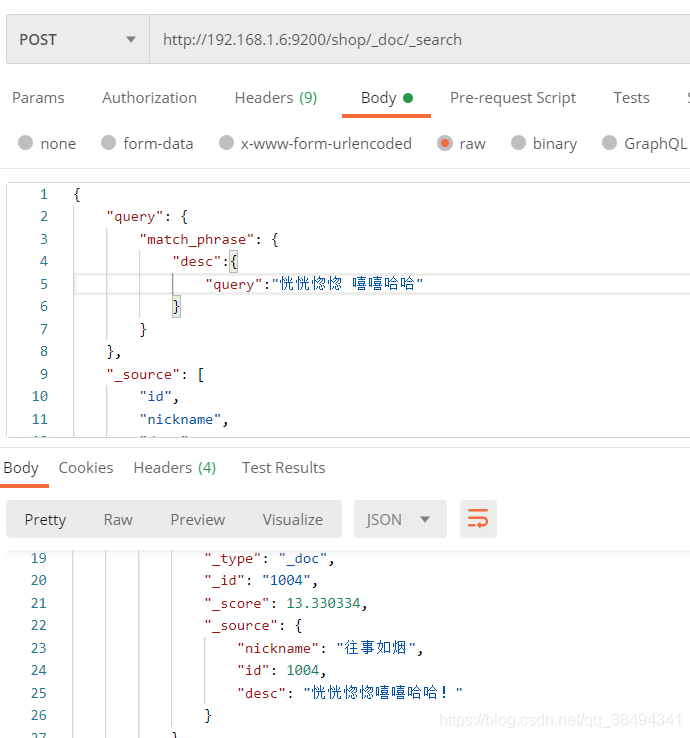
还有一种方式,比如你就是想后面不是连贯的匹配,可以使用slop,slop的意思是允许你中间可以有多少分词间隔
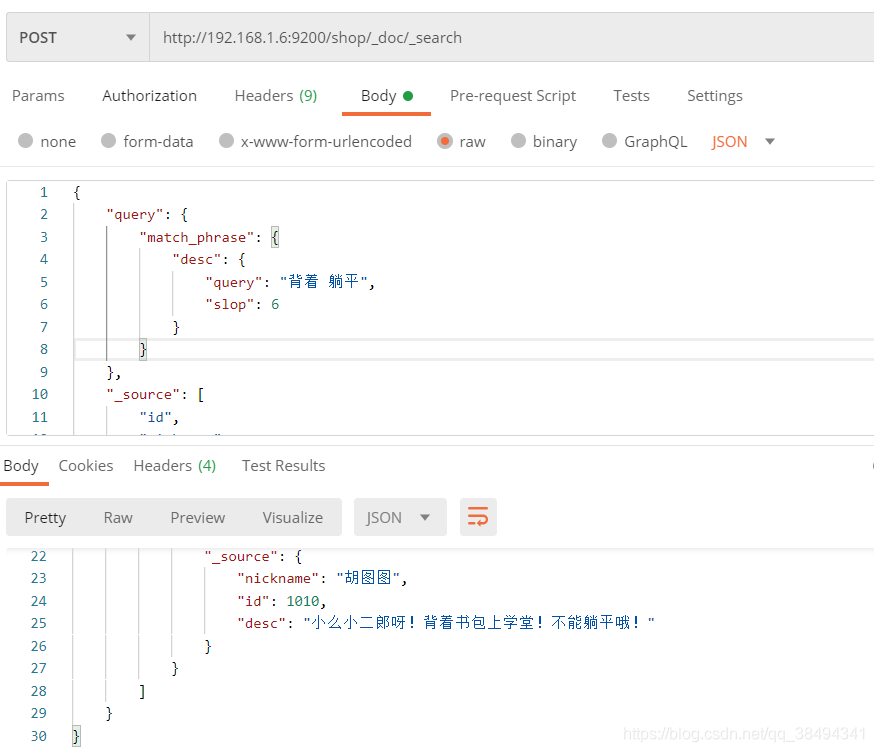
match进一步了解
operator
可以对match查询增加operator,默认是or条件,也就是查询的信息里只要匹配到分词:小,二,小二就可以。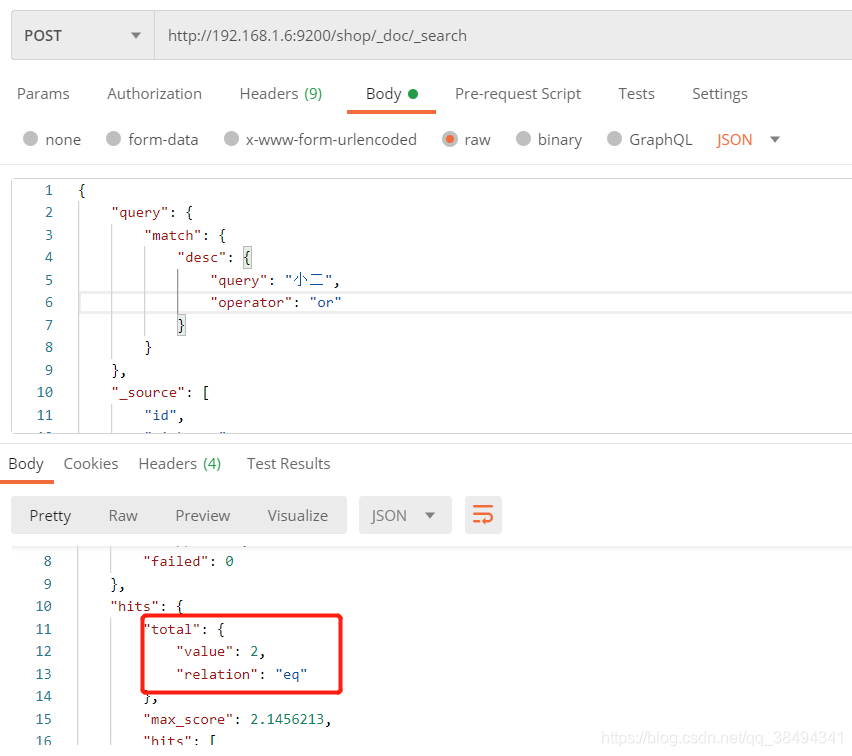
但是如果把operator改为and,那么在匹配的内容中必须同时出现分词内容,也就是小、二这两个词必须出现,顺序没有关系。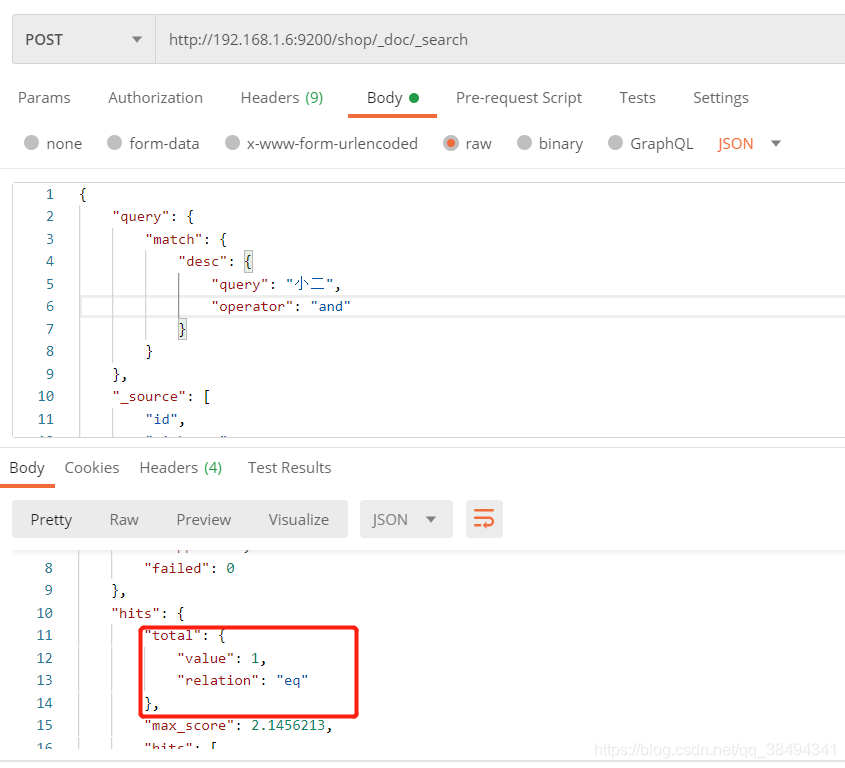
minimum_should_match
对于operator的and和or是两种极端情况,如果需要对匹配内容达到一定比例进行查询就可以使用minimum_should_match,如果minimum_should_match使用百分比那么就对对于匹配的内容达到这个百分比就可以查询出来。
当然也可以使用数值:1,2,3这些,这样的话就是当有1个值匹配到就查询出来,2个值匹配到就查询出来,以此类推。
ids查询
其实就是多id查询数据,有命中多少条就返回多少数据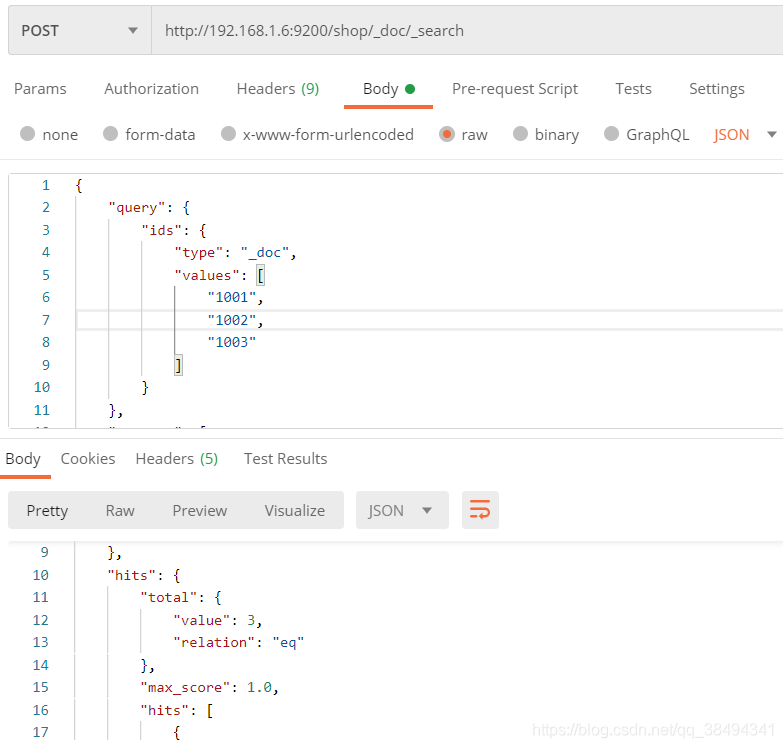
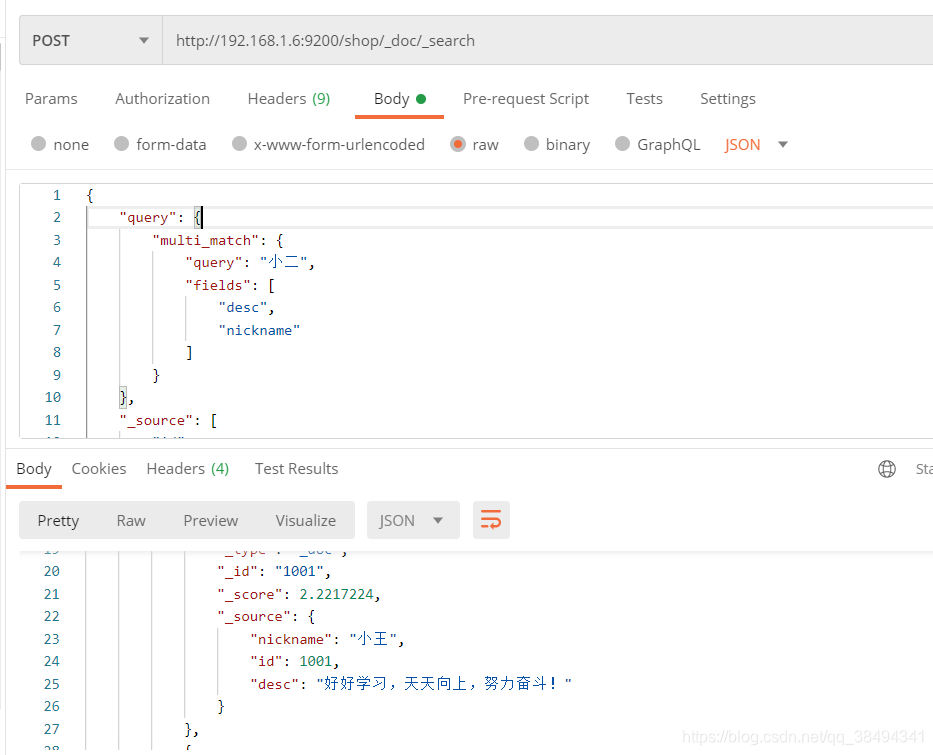
multi_match
多字段的匹配查询,fields中就去放入想要匹配的字段
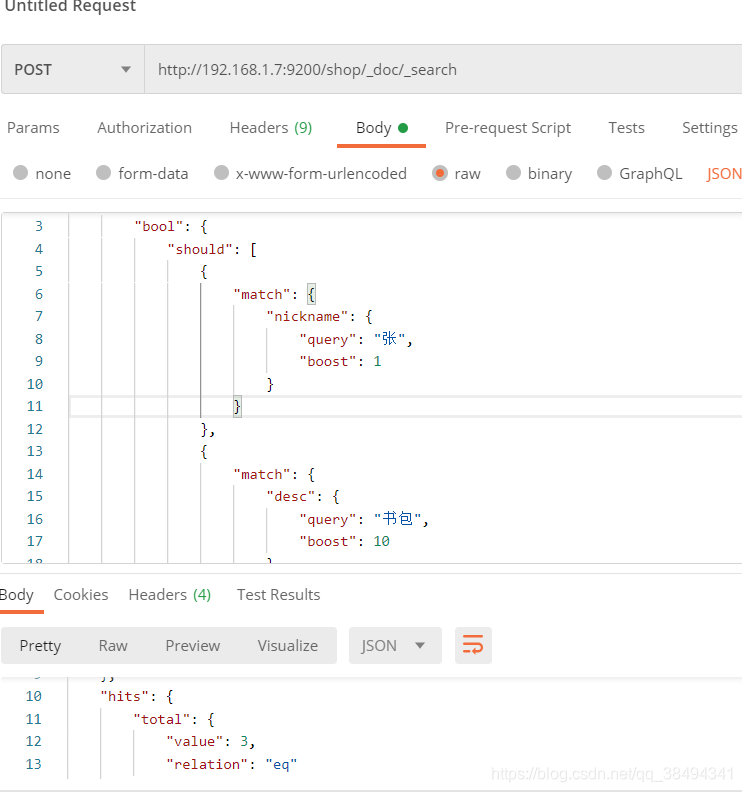
当需要对某个字段进行权重设置,也就是希望查询出来的某个字段匹配的数据信息往前排,就可以通过权重来实现
这里我给desc设置了权重,这样他的score就变大了,score越大,他在返回数据的排名中就越靠前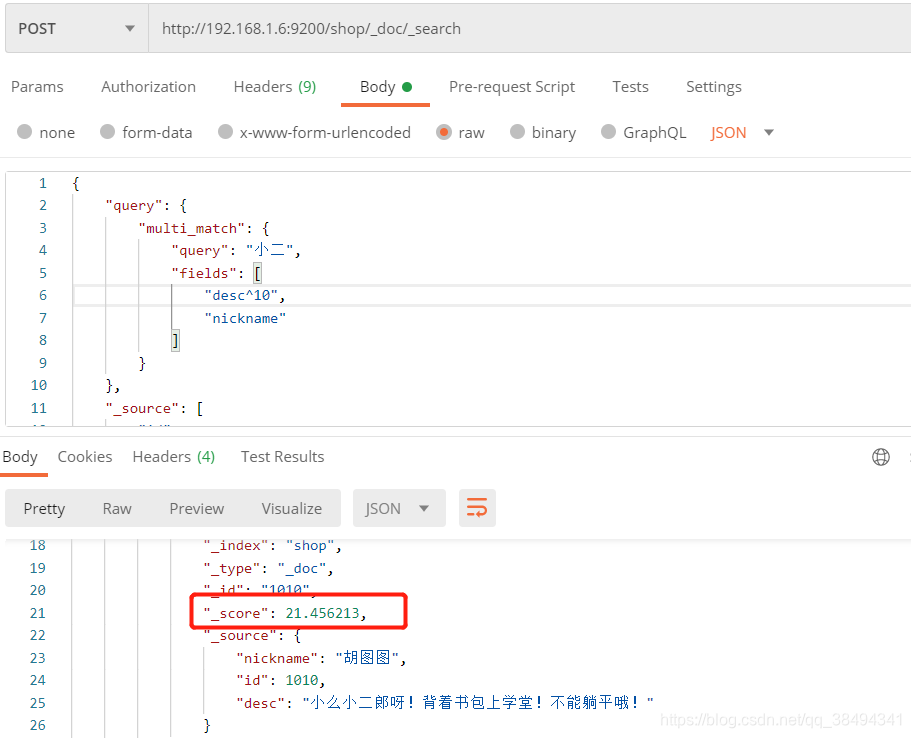
布尔查询
通过可视化查询可以看到boo的查询语句,bool查询包含must、must_not、should,是一种组合的查询方式,每一种查询都可以包含很多条件去查询,因为这3中查询他每一个都是一个数组。
must: 条件必须都匹配,相当于sql中的and查询。
must_not: 条件不匹配,把不满足条件的内容查询出来。
should: 相当于sql中的or查询,这个查询中的条件只要满足或者即可。
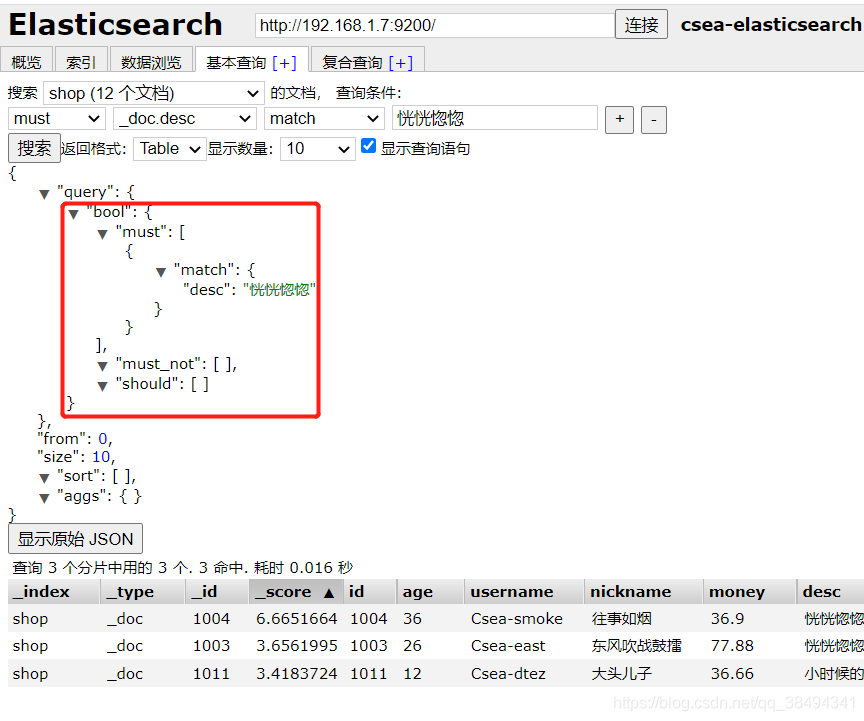
must查询
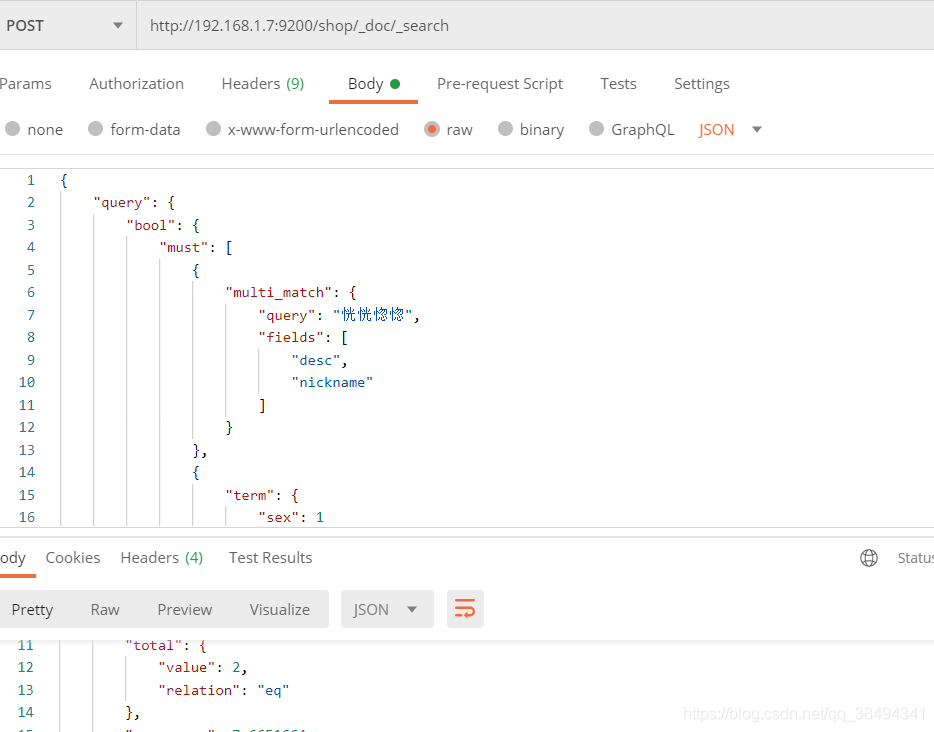
查询desc、nickname字段包含恍恍惚惚分词,并且sex为1的数据
{
"query": {
"bool": {
"must": [
{
"multi_match": {
"query": "恍恍惚惚",
"fields": [
"desc",
"nickname"
]
}
},
{
"term": {
"sex": 1
}
}
]
}
},
"_source": [
"id",
"sex",
"nickname",
"desc"
]
}
should
当把must改为should之后,匹配到的数量就变为了7条,因为只要满足其中一个条件即可。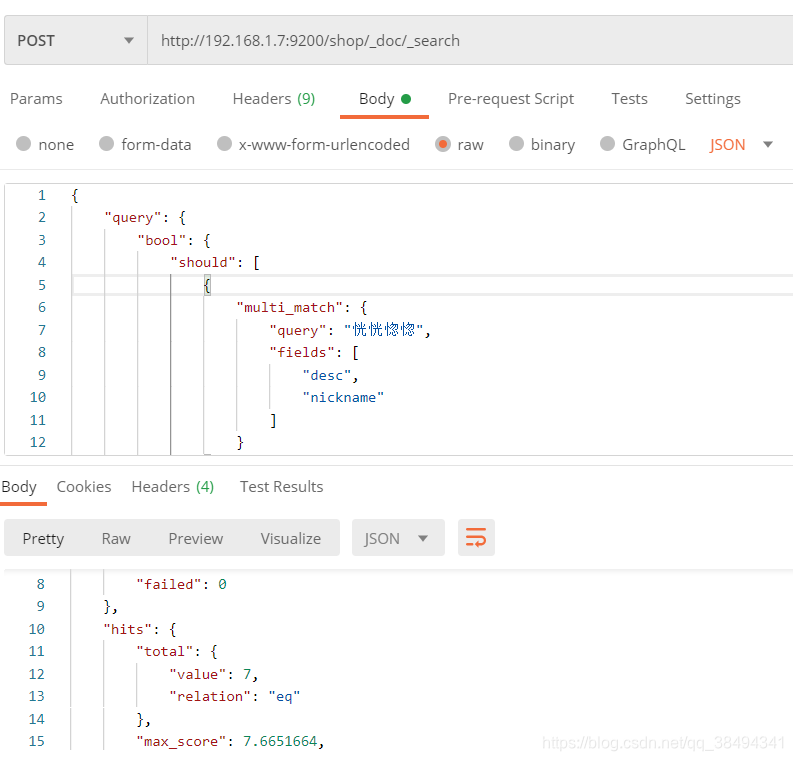
must_not
当改为must_not之后,查询结果就只有5条了,把不满足条件的数据全部查询出来,就跟should查询的数据量相加就是数据总量。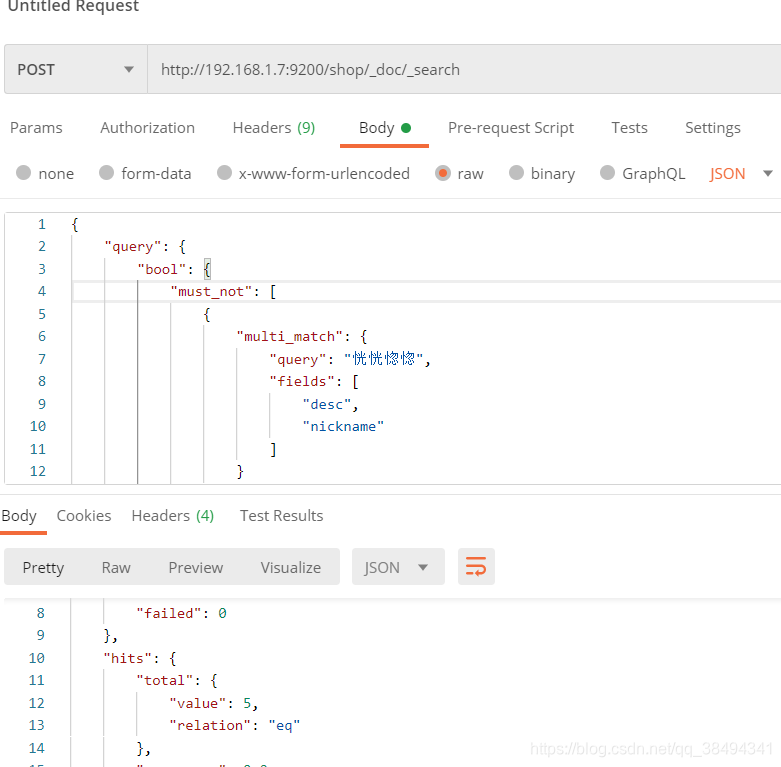
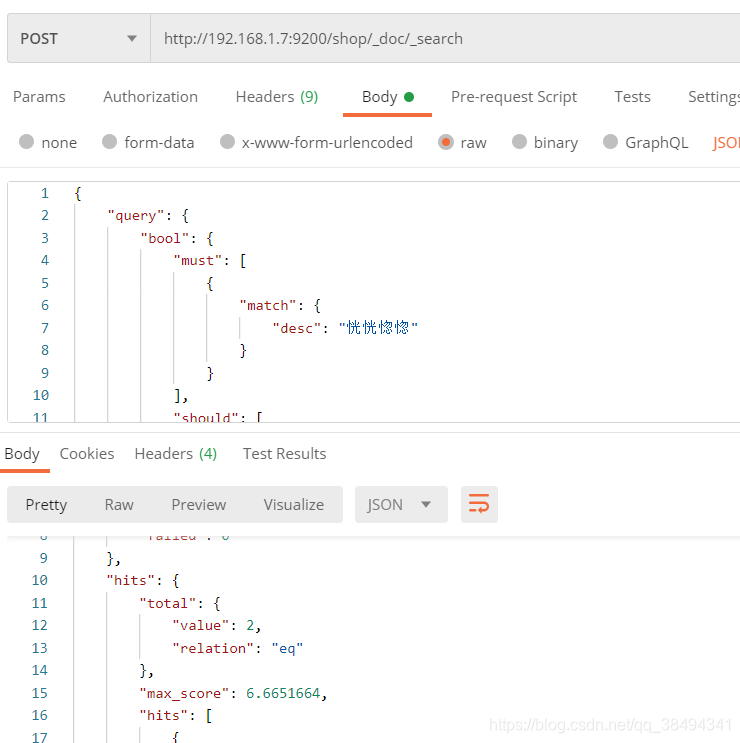
must、must_not、should组合查询
查询desc字段包含“恍恍惚惚”分词的,或者sex匹配“1”的数据,并且birthday字段内容不为“1989-06-12”的内容。
{
"query": {
"bool": {
"must": [
{
"match": {
"desc": "恍恍惚惚"
}
}
],
"should": [
{
"match": {
"sex": 0
}
}
],
"must_not": [
{
"term": {
"birthday": "1989-06-12"
}
}
]
}
},
"_source": [
"id",
"sex",
"nickname",
"desc",
"birthday"
]
}
boost权重
可以通过设置boost权重来提高要查询的内容的分数(排名)排在前面
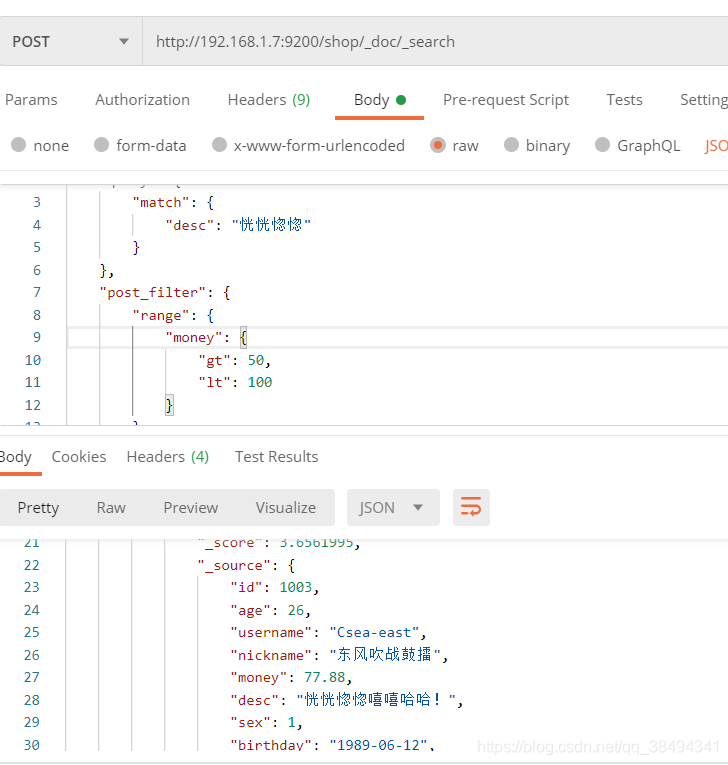
post_filter 过滤器
主要是针对于查询出的结果,在进行一次过滤,如下:
先匹配desc内容之后再进行money数值的过滤,下面是money的值大于50且小于100。
query是去es里检索的,post_filter去针对于query检索出来的数据进行的再次筛选。
{
"query": {
"match": {
"desc": "恍恍惚惚"
}
},
"post_filter": {
"range": {
"money": {
"gt": 50,
"lt": 100
}
}
}
}
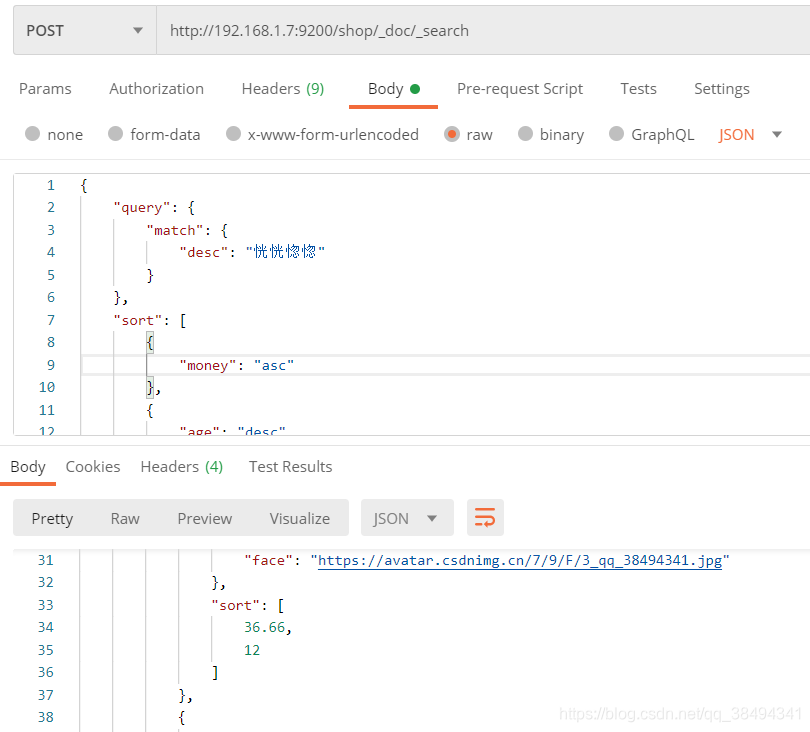
sort排序
顾名思义,就是排序。
如下:
先根据money字段升序,再根据age降序
{
"query": {
"match": {
"desc": "恍恍惚惚"
}
},
"sort": [
{
"money": "asc"
},
{
"age": "desc"
}
]
}
注意:
对于text类型的字段是不能直接进行排序的,必须给他添加一个附加类型keyword,因为text类型是可以进行多个分词的,这时候不知道是该如何进行排序的。此时只能用keyword进行进行排序。
演示keyword排序
新建一个shop2索引,新建mapping
{
"properties": {
"id": {
"type": "long"
},
"nickname": {
"type": "text",
"analyzer": "ik_max_word",
# 创建附加类型
"fields":{
"keyword":{
"type": "keyword"
}
}
}
}
}自行添加数据之后进行nickname的排序查询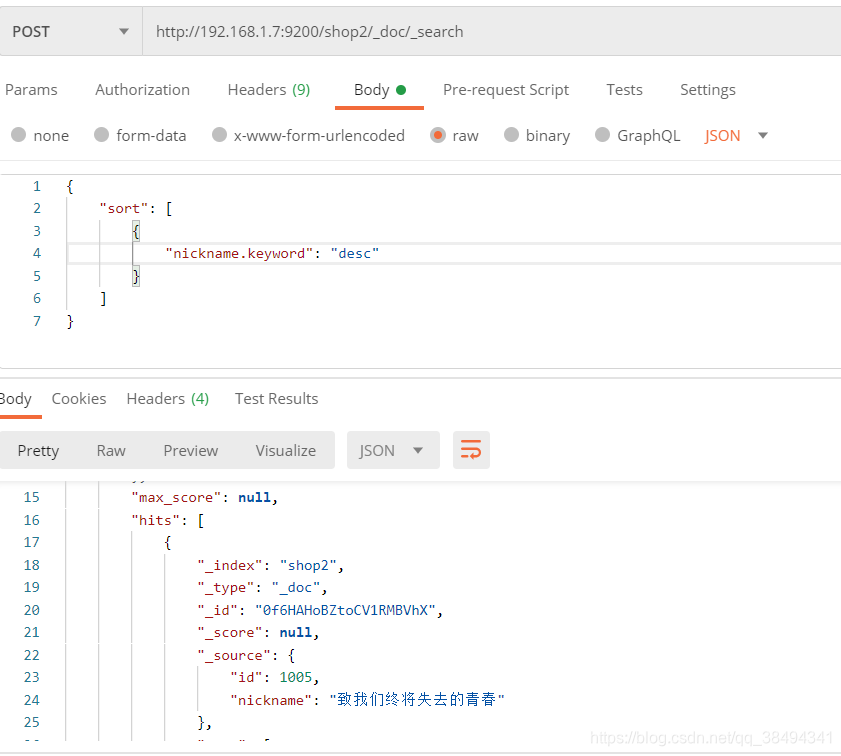
使用文本的排序应用场景也是比较少的
高亮
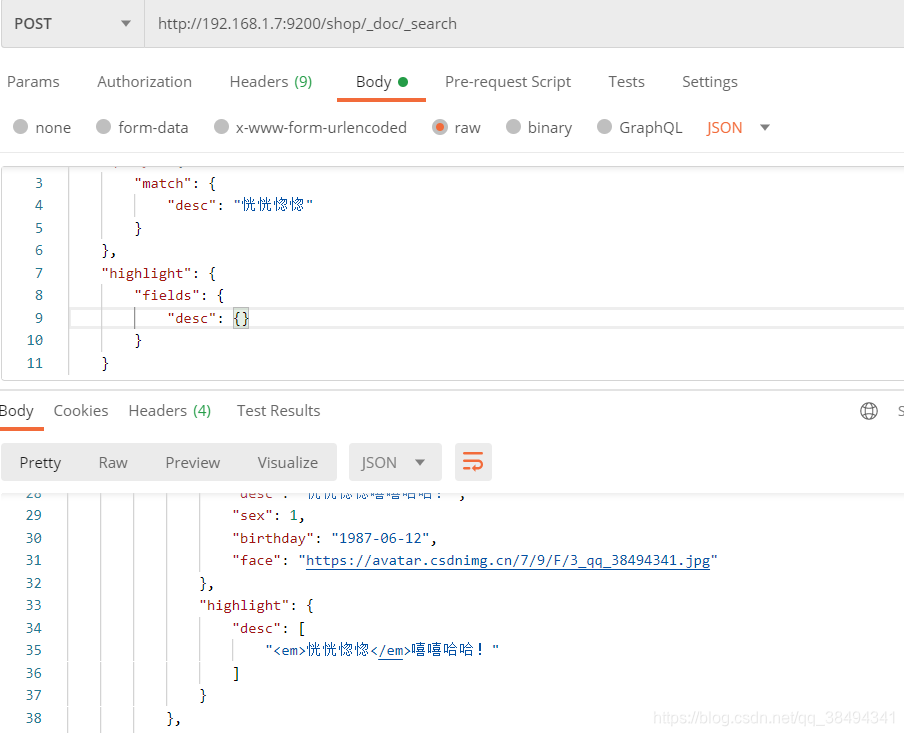
通过增加highlight来设置高亮,es默认是使用em标签来高亮
{
"query": {
"match": {
"desc": "恍恍惚惚"
}
},
"highlight": {
"fields": {
"desc": {}
}
}
}
通过自定义高亮标签来返回
"pre_tags":["<span>"],
"post_tags":["</span>"]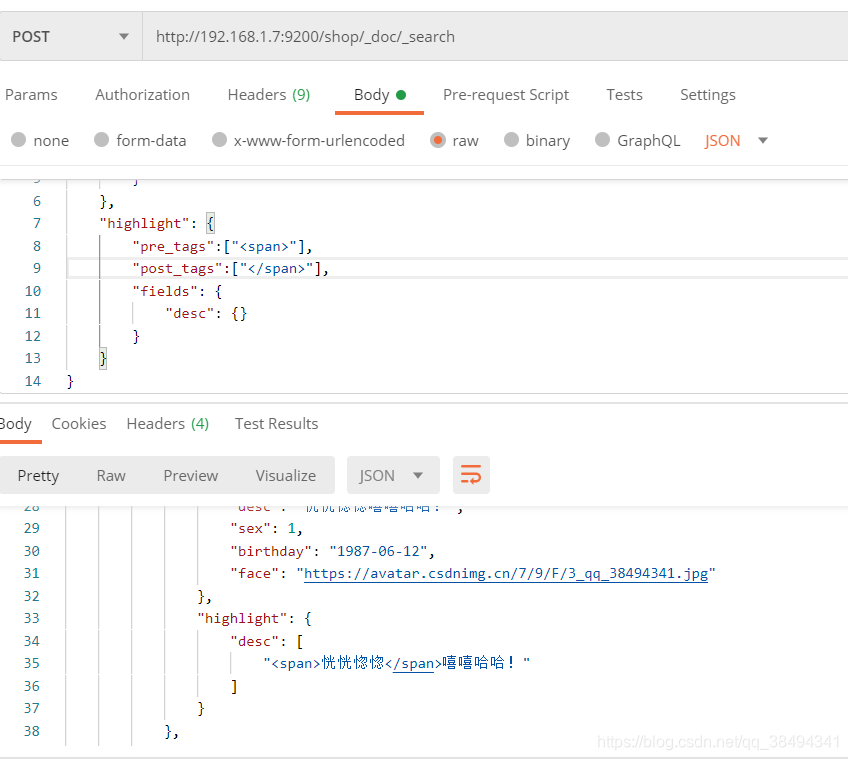
深度分页
当只是查询第10、20页,这还只是浅分页,当页码数越大越靠后时,就会产生深度分页。
当ES的from达到9999,size为10时,ES自己做了一层校验,来进行提示。以免我们分页太深,对性能造成影响。
Result window is too large, from + size must be less than or equal to:
[10000] but was [10009]. See the scroll api for a more efficient way
to request large data sets. This limit can be set by changing the
[index.max_result_window] index level setting.

ES之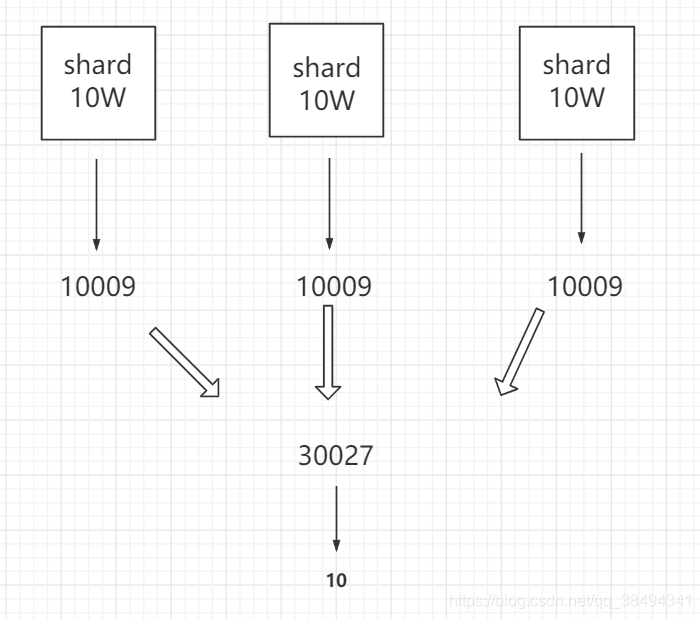
比如当前有3个shard,那么对于ES来说是从每个shard中拿10009条数据,然后汇总为30029条数据,再从30029中排序拿到前10条数据,那么另外的30019条数据就是无效的,在这个过程中就有性能的损耗。
一般这种情况使用业务来进行规避,比如淘宝的搜索,页面就已经限制了最大100页的分页。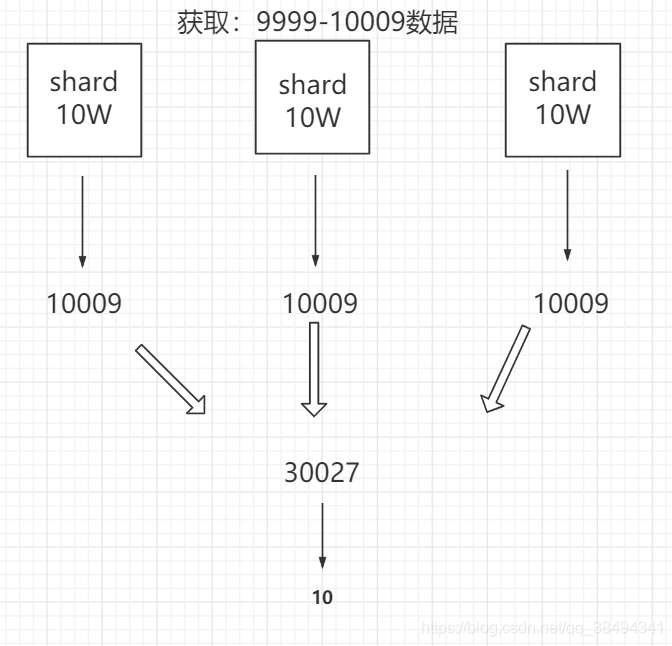
提示搜索量
Result window is too large, from + size must be less than or equal to:
[10000] but was [10009]. See the scroll api for a more efficient way
to request large data sets. This limit can be set by changing the
[index.max_result_window] index level setting.
在上面的深度分页中,ES也有提示,可以设置index.max_result_window提升10000的限制。
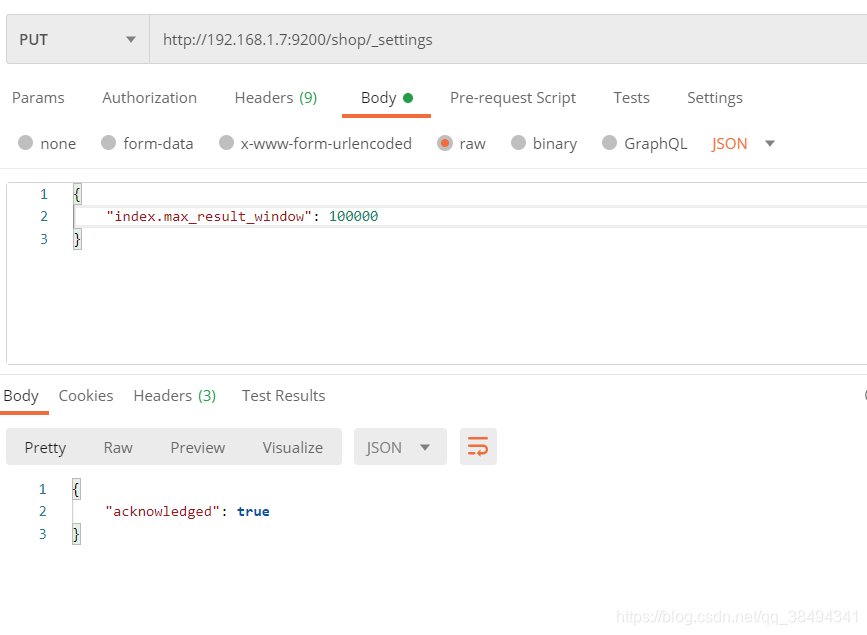
可以通过查看设置,数量限制已经生效,在没有设置之前可能看不到这个属性。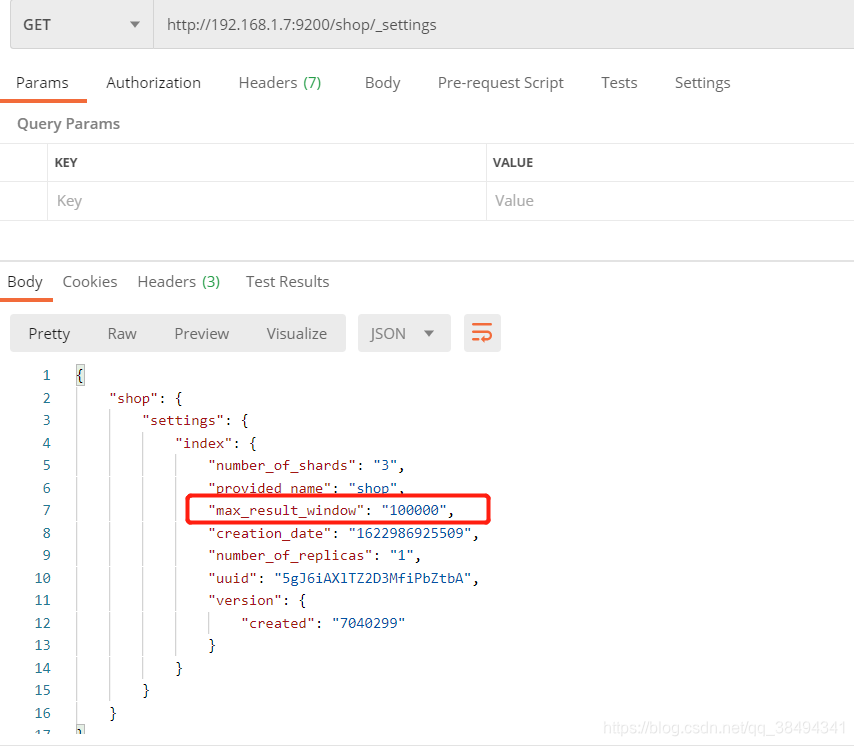
这个时候再去查询9999分页就没有问题了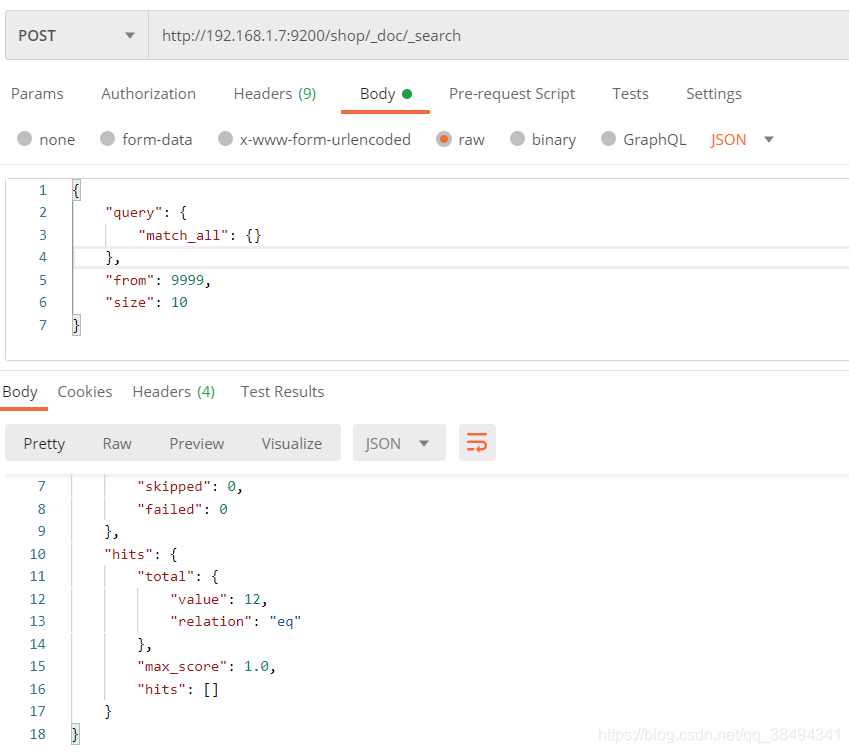
scroll滚动搜索(游标搜索)
当分页到99999会进行如下提示: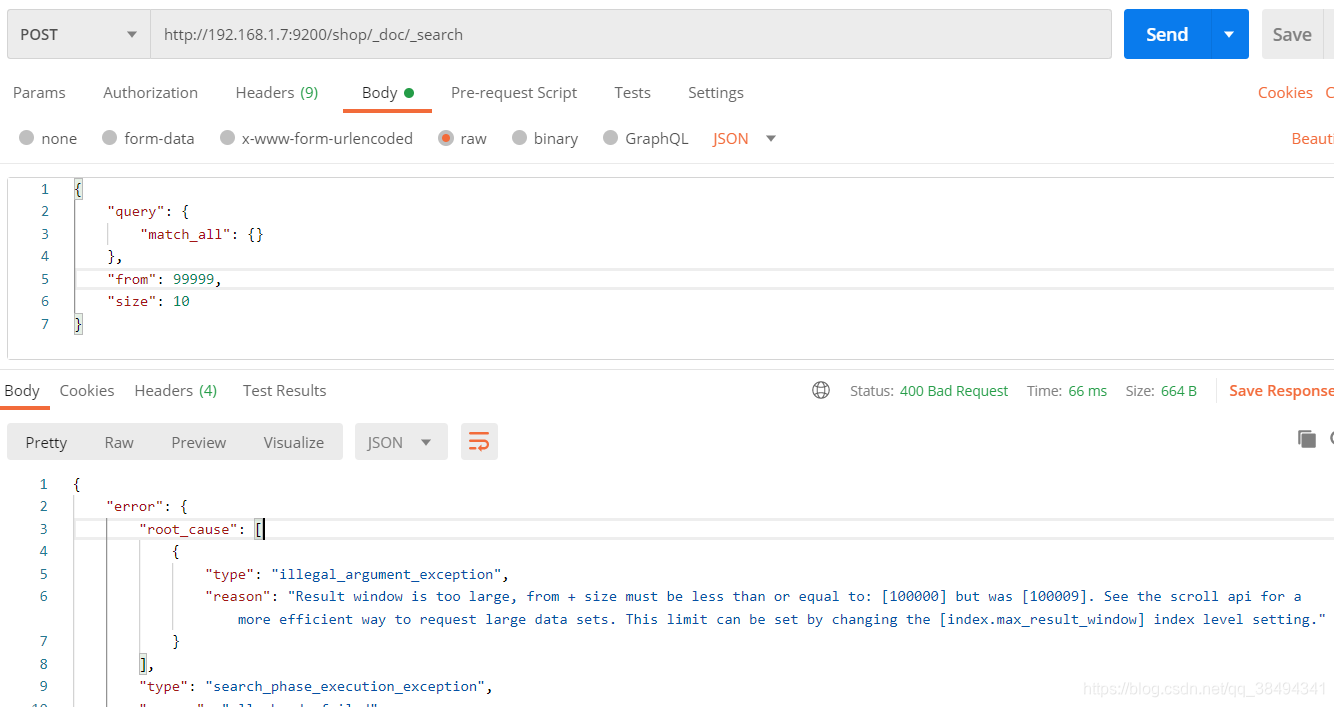
Result window is too large, from + size must be less than or equal to:
[100000] but was [100009]. See the scroll api for a more efficient way
to request large data sets. This limit can be set by changing the
[index.max_result_window] index level setting.
如果一下子要查询出10W的数据量,那肯定是对性能有影响的,那么ES提示可以使用滚动搜索。
那么对于滚动搜索就是,分批次进行加载数据,比如先查询一部分数据,再依次往下查询。
在第一次查询的时候,会有一个滚动的ID(类似锚标记),在下一次请求的时候只需要把上一次的锚标记拿到,传给下一次的查询就可以往下查询。如果查询过程中有数据变更,不会影响搜索结果(查询的是快照数据)。
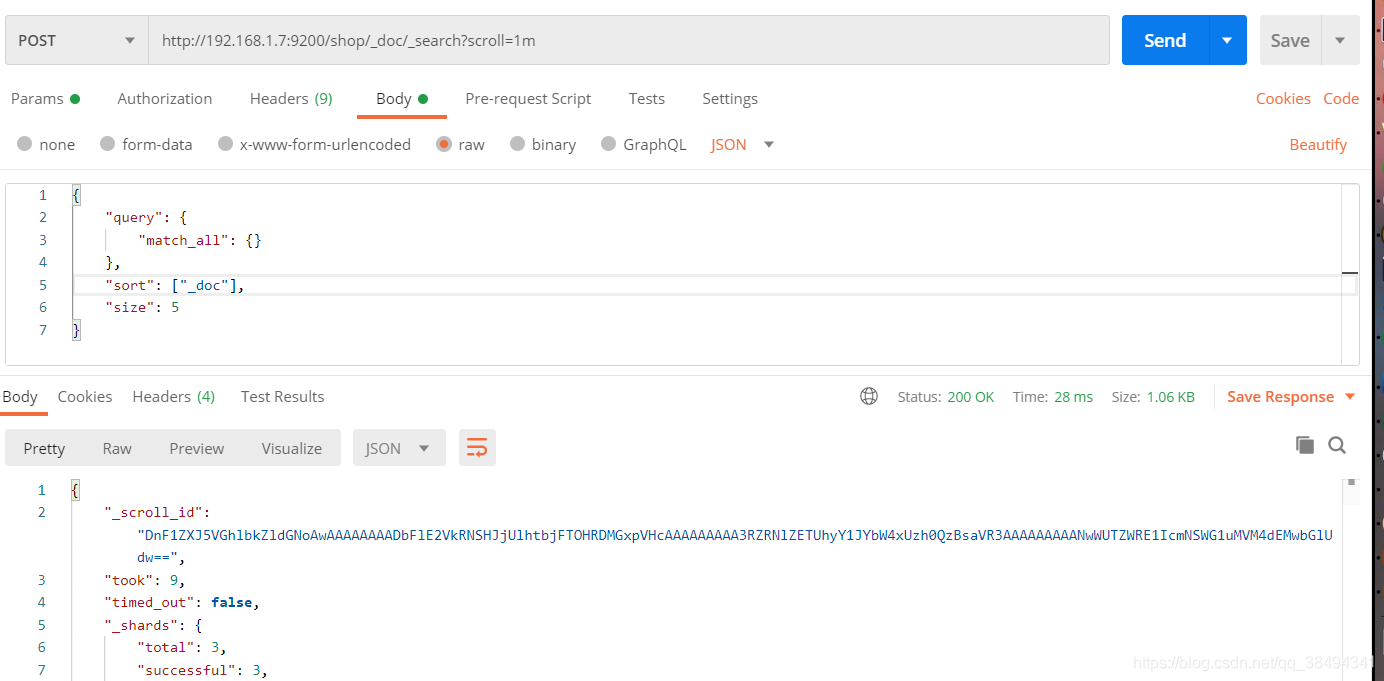
第一次查询:
POST:http://{IP}:{port}/{索引}/_doc/_search?scroll={时间}
{时间}:表示滚动的时候所存留的时间,一次请求的会话时间。
{
"query": {
"match_all": {}
},
# 固定"_doc"
"sort": ["_doc"],
# 每一次请求的数据量
"size": 5
}
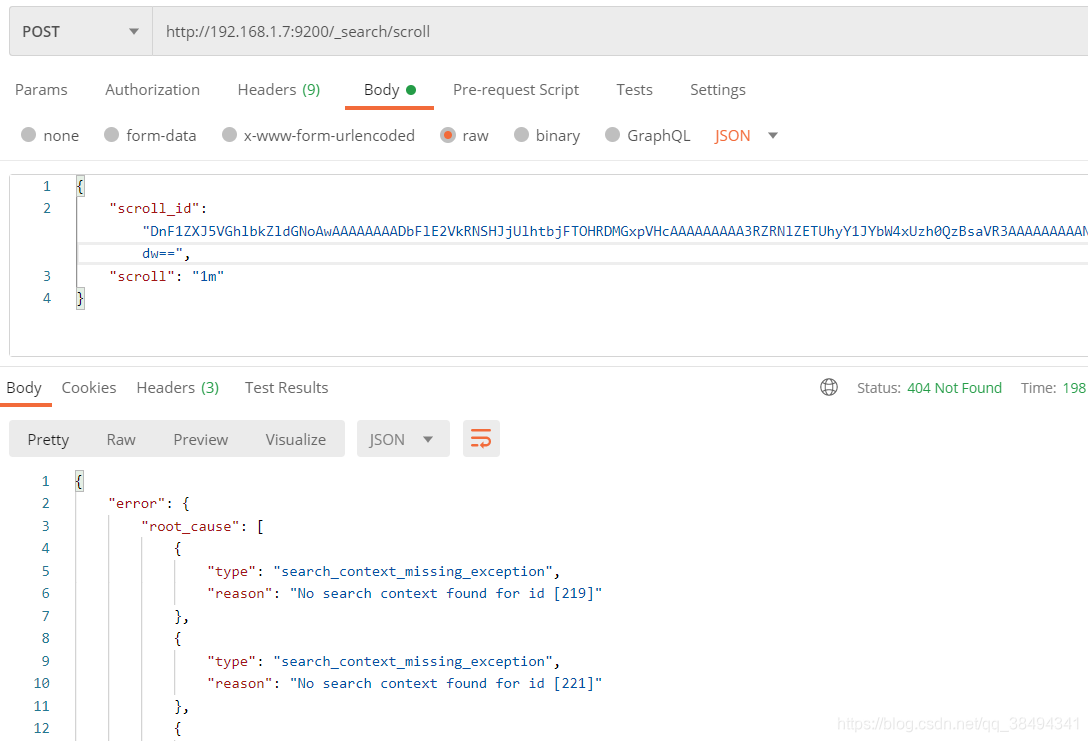
当出现如下提示,说明会话失效了,需要重新发起第一次调用(第一次的时候设置的1m)
第二次及之后的查询:
http://{IP}:{port}/_search/scroll
{
"scroll_id": "DnF1ZXJ5VGhlbkZldGNoAwAAAAAAAADeFlE2VkRNSHJjUlhtbjFTOHRDMGxpVHcAAAAAAAAA4BZRNlZETUhyY1JYbW4xUzh0QzBsaVR3AAAAAAAAAN8WUTZWRE1IcmNSWG1uMVM4dEMwbGlUdw==",
"scroll": "1m"
}
当请求回来的"hits"是一个空数组,那就说明数据已经都查询完毕了。
如果设置的size为1000,但是有可能取到超过这个值数量的文档。因为查询的时候,size作用于单个分配,所以实际返回的文档最大数是 size * 分片数。
_mget批量查询
除了使用ids查询方式,还有_mget
POST:http://{IP}:{port}/{索引名称}/_doc/_mget
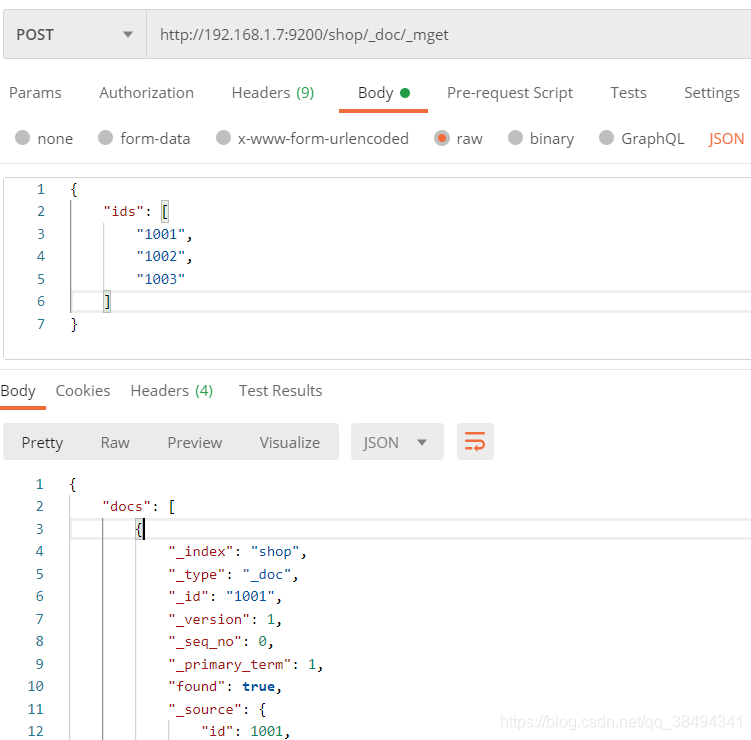
与ids查询的区别:
- ids查询更偏向于分页搜索,返回的元数据中包含分页的一些信息,而mget返回的元数据就是按照查询的条件来进行返回;
- ids查询中如果查询3个id,但是有一个没有查询到,那么就只返回2条记录,并不知道哪个没有匹配到;但是mget返回的数据中有一个found标记,表示这个条件的数据有没有查询到。
批量操作bulk
bulk操作和其他的基本操作不同,bulk不需要使用json格式化。
{ action: { metadata }}\n
{ request body }\n
{ action: { metadata }}\n
{ request body }\n
...
action: 表示操作的类型,新增、修改、删除。
metadata : 需要操作的文档的 _index 、 _type 和 _id , _index 、 _type 也可以在url中指定。
\n: 每行结尾都需要有\n,这是es的一个解析规范。
{ request body }: 请求体,新增、修改需要有,删除可以不用。
action有以下类型:
create:文档不存在,就会创建;如果文档存在就会报错,但是报错不影响其他操作。
index:创建一个新文档或者替换一个现有的文档。
update:部分更新一个文档。
delete:删除一个文档。
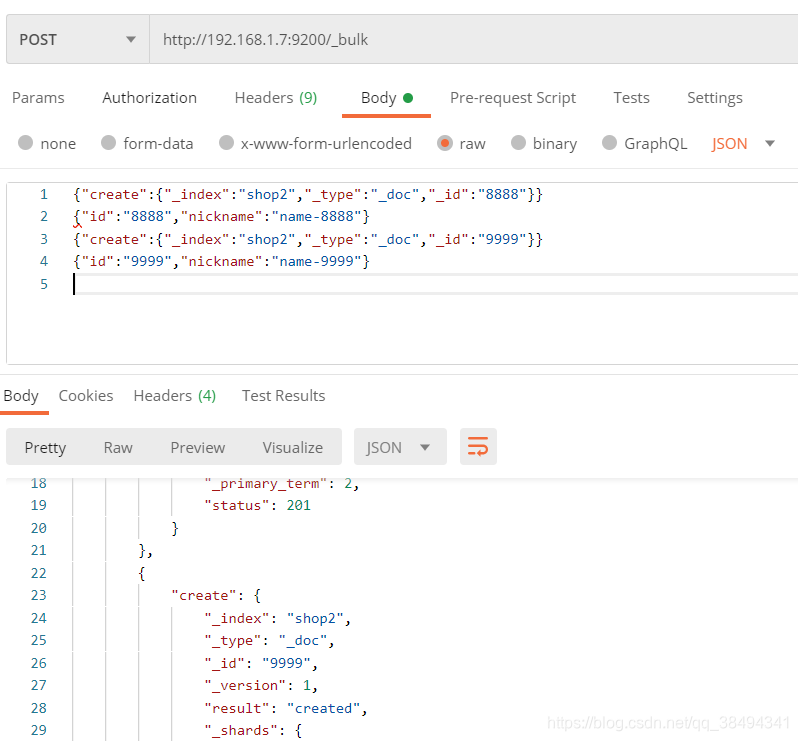
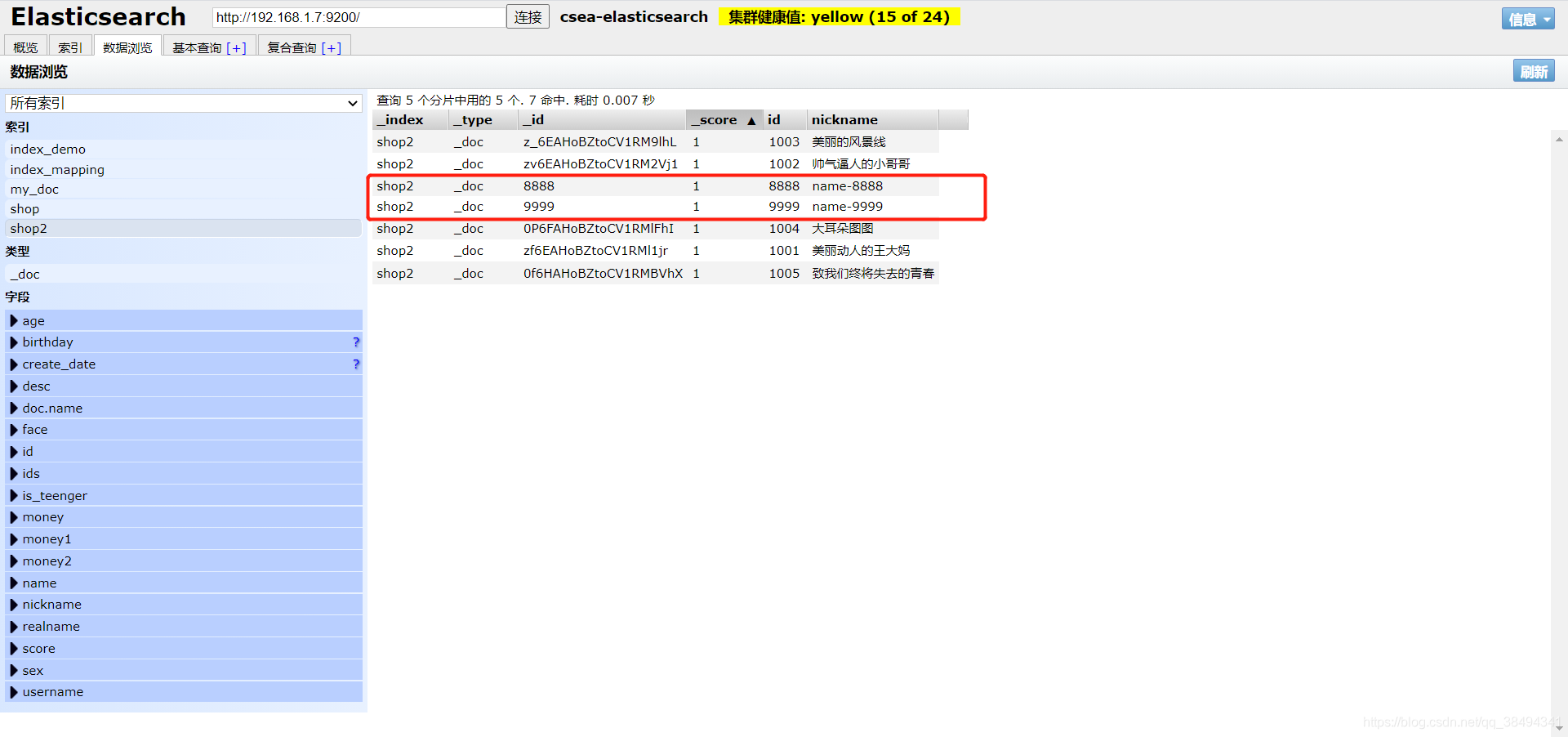
create
POST:http://{IP}:{port}/_bulk
{"create":{"_index":"shop2","_type":"_doc","_id":"8888"}}
{"id":"8888","nickname":"name-8888"}
{"create":{"_index":"shop2","_type":"_doc","_id":"9999"}}
{"id":"9999","nickname":"name-9999"}
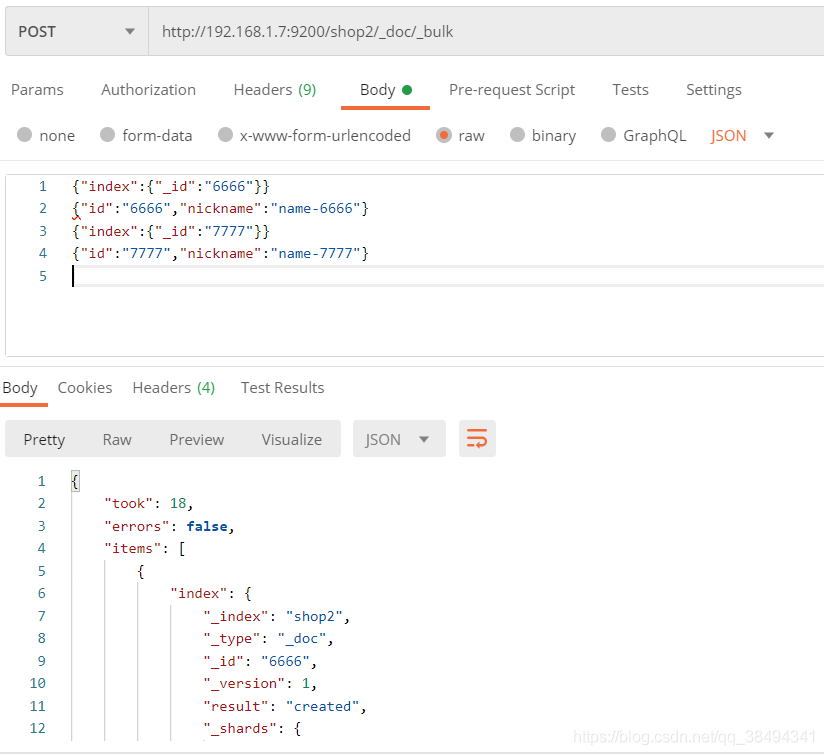
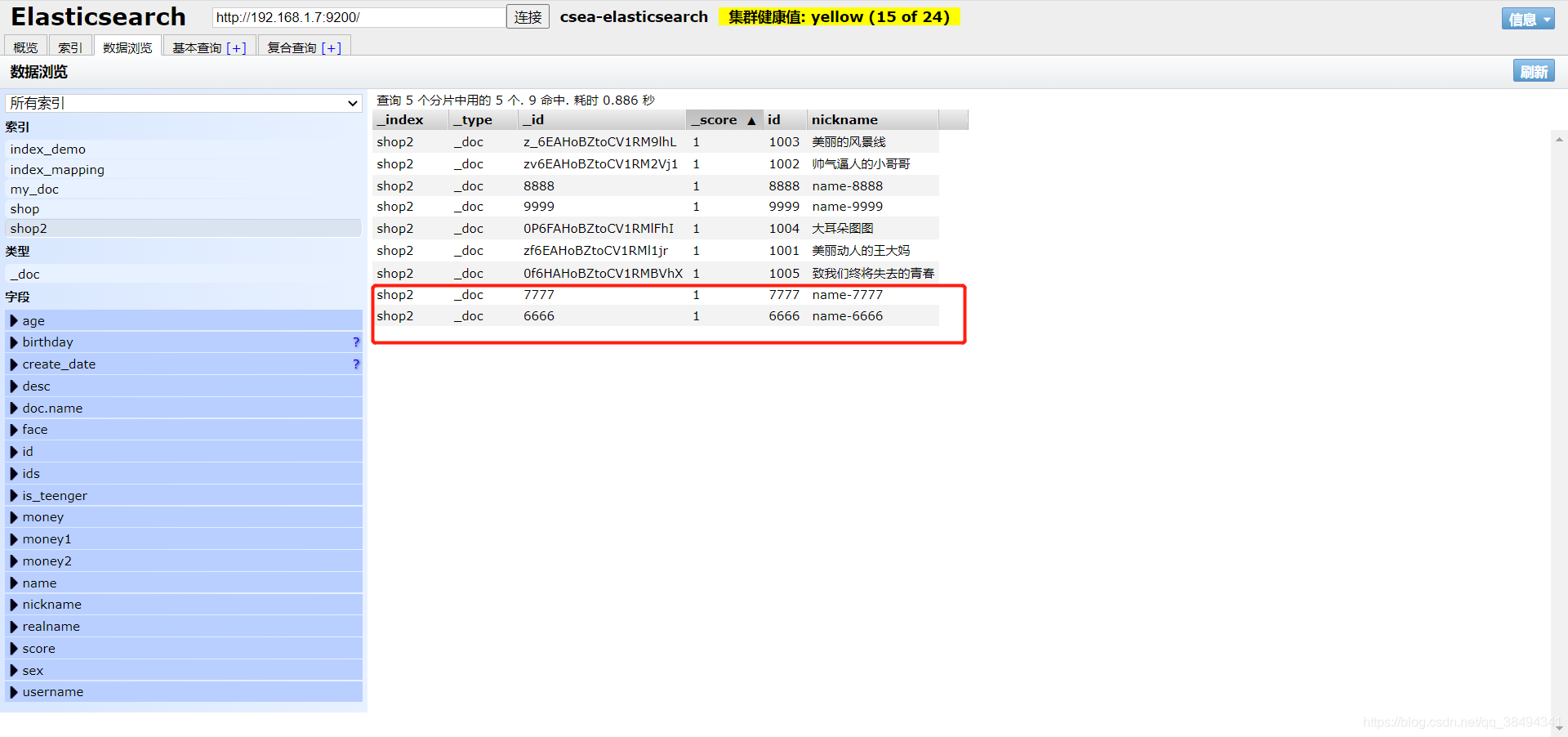
index
POST:http://{IP}:{port}/{索引名称}/_doc/_bulk
{"index":{"_id":"6666"}}
{"id":"6666","nickname":"name-6666"}
{"index":{"_id":"7777"}}
{"id":"7777","nickname":"name-7777"}
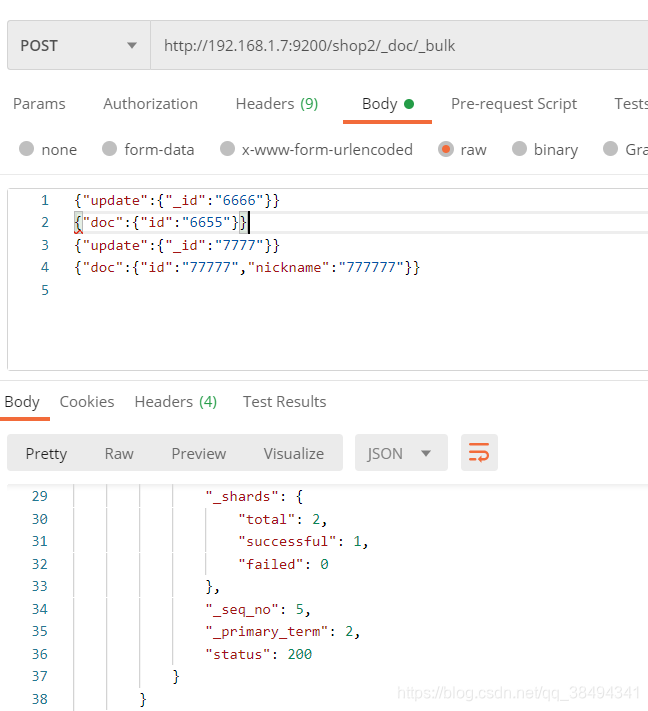
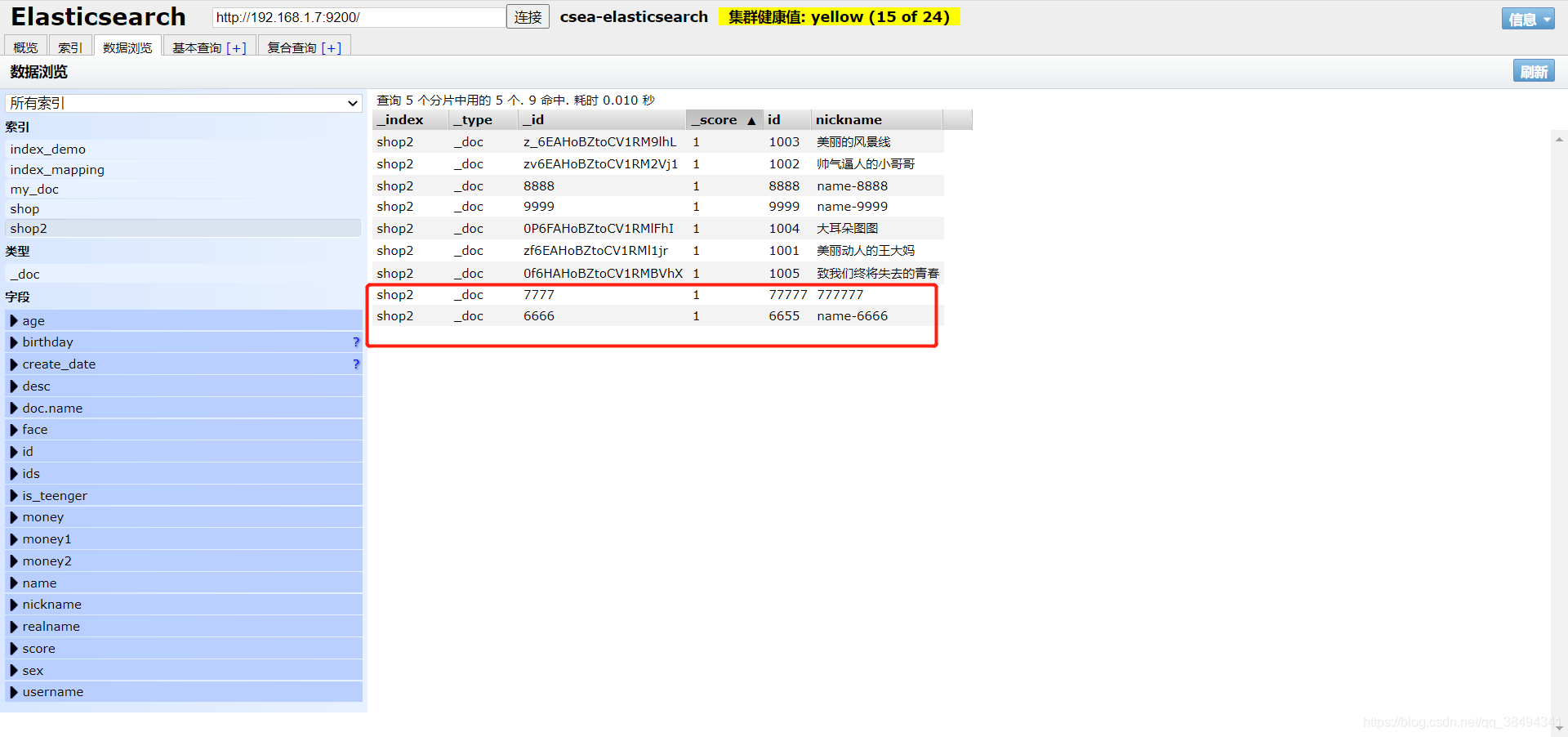
update
POST:http://{IP}:{port}/{索引名称}/_doc/_bulk
{"update":{"_id":"6666"}}
{"doc":{"id":"6655"}}
{"update":{"_id":"7777"}}
{"doc":{"id":"77777","nickname":"777777"}}
delete
{"delete":{"_id":"6666"}}
{"delete":{"_id":"7777"}}
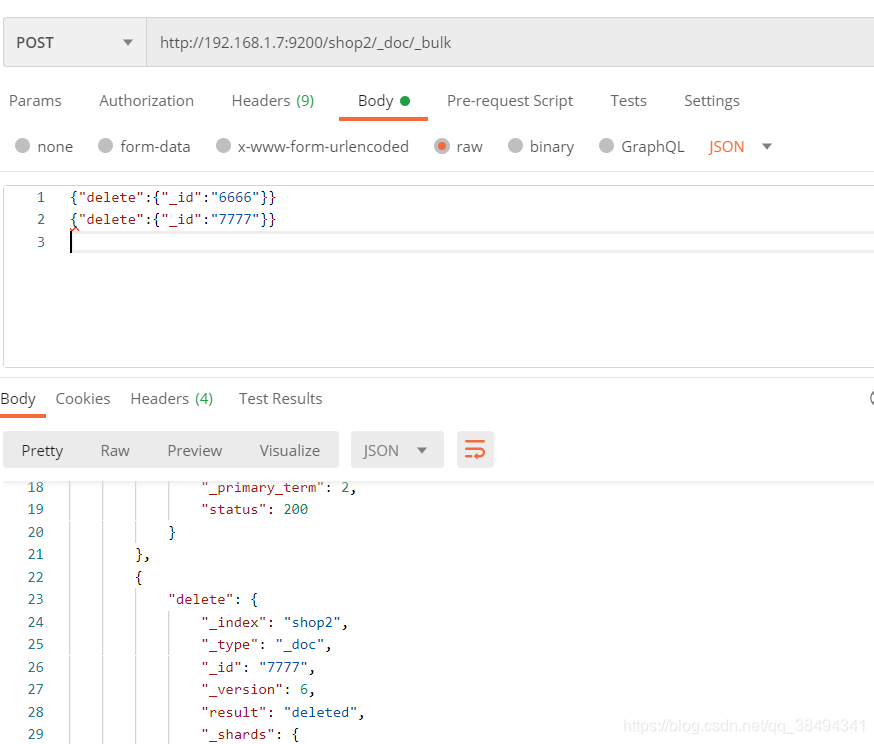
数据就已经被删除了