云栖号资讯:【 点击查看更多行业资讯】
在这里您可以找到不同行业的第一手的上云资讯,还在等什么,快来!
前言
当您第一次接触 Serverless 的时候,有一个不那么明显的新使用方式:与传统的基于服务器的方法相比,Serverless 服务平台可以使您的应用快速水平扩展,并行处理的工作更加有效。这主要是因为 Serverless 可以不必为闲置的资源付费,不用担心预留的资源不够。而在传统的使用范式中,用户必须预留成百上千的服务器来做一些高度并行化但执行时长较短的任务,而且必须为每一台服务器买单,即使有的服务器已经不再工作了。
以阿里云 Serverless 产品——函数计算为例,便可以完美解决您上述所有顾虑:
- 如果您的任务本身计算量不是很大,但是有大量的并发任务请求需要并行处理, 比如多媒体文件处理、文档转换等;
- 一个任务本身计算量很大,要求单个任务很快处理完,并且还能支持并行处理多个任务。
在这种场景下,用户唯一关注的就是:您的任务是可以分治拆解并且子任务是可以并行处理的,一个需要一个小时才能处理完的长任务,可以分解成 360 个独立的 10 秒长的子任务并行处理,这样,以前您要花一个小时才能处理完的任务,现在只需要 10 秒就可以搞定。由于采用的是按量计费的模型,完成的计算量和成本是大致相当的,而传统模型则因为预留资源肯定会存在浪费,浪费的费用也是需要您去承担的。
接下来,将详细阐述 Serverless 在大规模数据处理上的实践。
极致弹性扩缩容应对计算波动
在介绍相关的大规模数据处理示例之前, 这里先简单介绍一下函数计算。
1. 函数计算简介

- 开发者使用编程语言编写应用和服务,函数计算支持的开发语言请参见开发语言列表;
- 开发者上传应用到函数计算;
- 触发函数执行:触发方式包括 OSS、API 网关、日志服务、表格存储以及函数计算 API、SDK 等;
- 动态扩容以响应请求:函数计算可以根据用户请求量自动扩容,该过程对您和您的用户均透明无感知;
- 根据函数的实际执行时间按量计费:函数执行结束后,可以通过账单来查看执行费用,收费粒度精确到 100 毫秒。
至此,您大约可以简单理解到函数计算是怎么运作的,接下来以大量视频并行转码的案例来阐述:假设一家在家教育或娱乐相关的企业,老师授课视频或者新的片源一般是集中式产生,而您希望这些视频被快速转码处理完以便能让客户快速看到视频回放。比如在当下疫情中,在线教育产生的课程激增,而出课高峰一般是 10 点、12 点、16 点、18 点等明显的峰值段,特定的时间内(比如半个小时)处理完所有新上传的视频是一个通用而且普遍的需求。
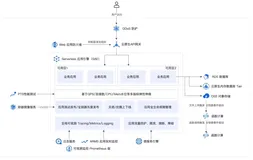
2. 弹性高可用的音视频处理系统
- OSS 触发器

如上图所示,用户上传一个视频到 OSS,OSS 触发器自动触发函数执行,函数计算自动扩容,执行环境内的函数逻辑调用 FFmpeg 进行视频转码,并且将转码后的视频保存回 OSS。
- 消息触发器

如上图所示,应用只需要发一个消息,自动触发函数执行音视频处理的任务即可,函数计算自动扩容,执行环境内的函数逻辑调用 FFmpeg 进行视频转码, 并且将转码后的视频保存回 OSS。
- 直接手动调用 SDK 执行音视频处理任务
以 python 为例,大致如下:
python # -*- coding: utf-8 -*-
import fc2
import json
client = fc2.Client(endpoint="http://123456.cn-hangzhou.fc.aliyuncs.com",accessKeyID="xxxxxxxx",accessKeySecret="yyyyyy")
# 可选择同步/异步调用
resp = client.invoke_function("FcOssFFmpeg", "transcode", payload=json.dumps(
{
"bucket_name" : "test-bucket",
"object_key" : "video/inputs/a.flv",
"output_dir" : "video/output/a_out.mp4"
})).data
print(resp)从上面我们也可以看出,触发函数执行的方式也很多,同时简单配置下 SLS 日志,就可以很快实现一个弹性高可用、按量付费的音视频处理系统,同时能提供免运维、具体业务数据可视化、强大自定义监控报警等超强功能的 dashboard。

目前已经落地的音视频案例有 UC、语雀、躺平设计之家、虎扑以及几家在线教育的头部客户等,其中有些客户高峰期间,弹性使用到了万核以上 CPU 计算资源,并行处理的视频达到 1700+,同时提供了极高的性价比。
任务分治,并行加速
这种将任务分而治之的思想应用在函数计算上是一件有趣的事情,在这里举一个例子,比如您有一个超大的 20G 的 1080P 高清视频需要转码,即使您使用一台高配机器,需要的时间可能还是要按小时计,如果中途出问题中断转码,您只能重新开始再重复一遍转码的过程,如果您使用分治的思想+函数计算,转码的过程衍变为 分片-> 并行转码分片-> 合并分片,这样就可以解决您上述的两个痛点:
- 分片和合成分片是内存级别的拷贝,需要的计算量极小,真正消耗计算量的转码,拆分成了很多子任务并行处理,在这个模型中,分片转码的最大时间基本等同于整个大视频的转码时间;
- 即使中途某个分片转码出现异常,只需要重试这个分片的转码即可,不需要整个大任务推倒重来。
通过将大任务合理的分解,配合使用函数计算,编写一点 code,就可以快速完成一个弹性高可用、并行加速、按量付费的大型数据处理系统。
在介绍这个方案之前,我们先简单介绍一下 Serverless 工作流,Serverless 工作流可以很好地将函数和其他云服务和自建服务有组织地编排起来。
1. Serverless 工作流简介
Serverless 工作流(Serverless Workflow)是一个用来协调多个分布式任务执行的全托管云服务。在 Serverless 工作流中,您可以用顺序、分支、并行等方式来编排分布式任务,Serverless 工作流会按照设定好的步骤可靠地协调任务执行,跟踪每个任务的状态转换,并在必要时执行用户定义的重试逻辑,以确保工作流顺利完成。Serverless 工作流简化了开发和运行业务流程所需要的任务协调、状态管理以及错误处理等繁琐工作,让您聚焦业务逻辑开发。
接下来以一个大视频快速转码的案例来阐述 Serverless 工作编排函数,实现大计算任务的分解,并行处理子任务,最终达到快速完成单个大任务的目的。
2. 大视频的快速多目标格式转码

如上图所示,假设用户上传一个 mov 格式的视频到 OSS,OSS 触发器自动触发函数执行,函数调用 FnF 执行,FnF 同时进行 1 种或者多种格式的转码(由 template.yml 中的 DST_FORMATS 参数控制),假设配置的是同时进行 mp4 和 flv 格式的转码。
- 一个视频文件可以同时被转码成各种格式以及其他各种自定义处理,比如增加水印处理或者在 after-process 更新信息到数据库等;
- 当有多个文件同时上传到 OSS,函数计算会自动伸缩,并行处理多个文件,同时每次文件转码成多种格式也是并行;
- 结合 NAS + 视频切片,可以解决超大视频的转码,对于每一个视频,先进行切片处理,然后并行转码切片,最后合成,通过设置合理的切片时间,可以大大加快较大视频的转码速度;
- fnf 可以跟踪每一步执行情况,并且可以自定义每一个步骤的重试,提高任务系统的鲁棒性,如:retry-example
在任务分治,并行加速具体的案例中,上面分享的是 CPU 密集型任务分解,但也可以进行 IO 密集型任务分解,比如这个需求:上海的 region 的 OSS bucket 中的一个 20G 大文件,秒级转存回杭州的 OSS Bucket 中。这里也可以采用分治的思路,Master 函数在接到转存任务之后,将超大文件进行分片的 range 分配给每个 Worker 子函数,Worker 子函数并行转存属于自己那部分的分片,Master 函数待所有子 Worker 运行完毕之后,提交合并分片请求,完成整个转存任务。

总结
本文探讨了 Serverless 服务平台可以使您的应用快速水平扩展,并行处理的工作更加有效,并给出了具体的实践案例,无论在 CPU 密集型还是 IO 密集型场景,函数计算 + Serverless 都能完美解决您以下顾虑:
- 不必为闲置的资源付费
- 不用担心计算资源预留不够
- 大计算量的任务需要快速处理完毕
- 更好的任务流程跟踪
- 完善的监控报警、免运维、业务数据可视化等
- ....
本文中对于 Serverless 音视频处理只是一个示例,它展示的是函数计算配合 Serverless 工作流在离线计算场景中的能力和独一无二的优势。我们可以用发散的方式去拓展 Serverless 在大规模数据处理实践的边界,比如AI、基因计算、科学仿真等。希望本篇文章能吸引您,开启您的 Serverless 奇妙之旅。
【云栖号在线课堂】每天都有产品技术专家分享!
课程地址: https://yqh.aliyun.com/live立即加入社群,与专家面对面,及时了解课程最新动态!
【云栖号在线课堂 社群】https://c.tb.cn/F3.Z8gvnK