
Puppeteer 是什么?


puppeteer 官网的介绍如下:
Puppeteer is a Node library which provides a high-level API to control Chrome or Chromium over the DevTools Protocol. Puppeteer runs headless by default, but can be configured to run full (non-headless) Chrome or Chromium.
通俗描述就是:Puppeteer 可以将 Chrome 或者 Chromium 以无界面的方式运行(当然也可以运行在有界面的服务器上),然后可以通过代码控制浏览器的行为,即使是非界面的模式运行,Chrome 或 Chromium 也可以在内存中正确渲染网页的内容。
那么 Puppeteer 能做什么呢?其实有很多地方都可以受用 Puppeteer,比如:
- 生成网页截图或者 PDF
- 抓取 SPA(Single-Page Application) 进行服务器渲染(SSR)
- 高级爬虫,可以爬取大量异步渲染内容的网页
- 模拟键盘输入、表单自动提交、登录网页等,实现 UI 自动化测试
- 捕获站点的时间线,以便追踪你的网站,帮助分析网站性能问题
本文选择截图场景作为演示。
如何快速部署一个分布式 Puppeteer Web 应用?
为了快速部署分布式 Puppeteer Web 应用,这里我们选择函数计算服务。
函数计算(Function Compute): 函数计算是一个事件驱动的服务,通过函数计算,用户无需管理服务器等运行情况,只需编写代码并上传。函数计算准备计算资源,并以弹性伸缩的方式运行用户代码,而用户只需根据实际代码运行所消耗的资源进行付费。函数计算更多信息参考。
有了函数计算服务,我们这里目标是搭建一个分布式应用,但做的事情其实很简单,那就是写好业务代码,部署到函数计算,仅此而已。
使用函数计算后,我们的系统架构图如下:

搭建步骤步骤:
整体流程如下图所示:

其中,需要我们操作的只有 Fun Init、Fun Install 以及 Fun Deploy 命令,每个的步骤内容都会由这三个命令自动完成。
1. 工具安装
安装 Fun 工具:
建议直接从这里下载二进制可执行程序,解压后即可直接使用。下载地址。
安装 Docker:
可以按照这里介绍的方法进行安装。
2. 初始化项目:
通过 Fun 工具,使用下面的命令可以快速初始化一个 Puppeteer Web 应用的脚手架:
fun init -n puppeteer-test http-trigger-node-puppeteer
其中 -n puppeteer-test 表示初始化项目的目录名称, http-trigger-node-puppeteer 表示要使用的模板名称,可以省略该名称,省略后,可以从终端提示的列表中自行选择需要的模板。
执行完毕后,可以看到如下的目录结构:
.
├── index.js
├── package.json
└── template.yml
相比较于传统的 puppeteer 应用,这里仅仅多了一个 template.yml 文件,用于描述函数计算的资源。
而 index.js 就是我们的业务代码了,可以按照 Puppeteer 官方帮助文档的要求书写自己的业务代码,这里不再重复阐述,核心代码如下:
const browser = await puppeteer.launch({
headless: true,
args: [
'--no-sandbox',
'--disable-setuid-sandbox',
]
});
const page = await browser.newPage();
await page.emulateTimezone('Asia/Shanghai');
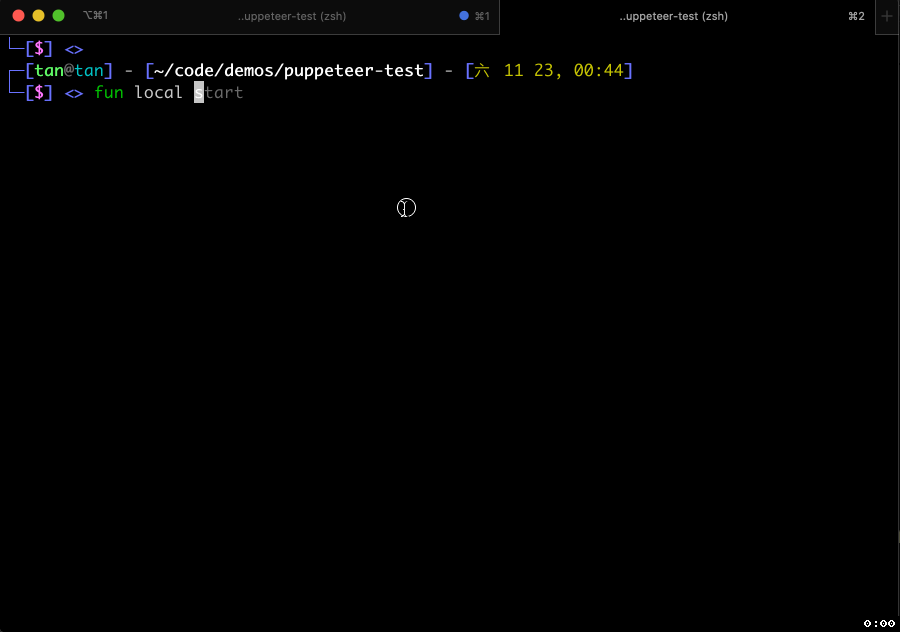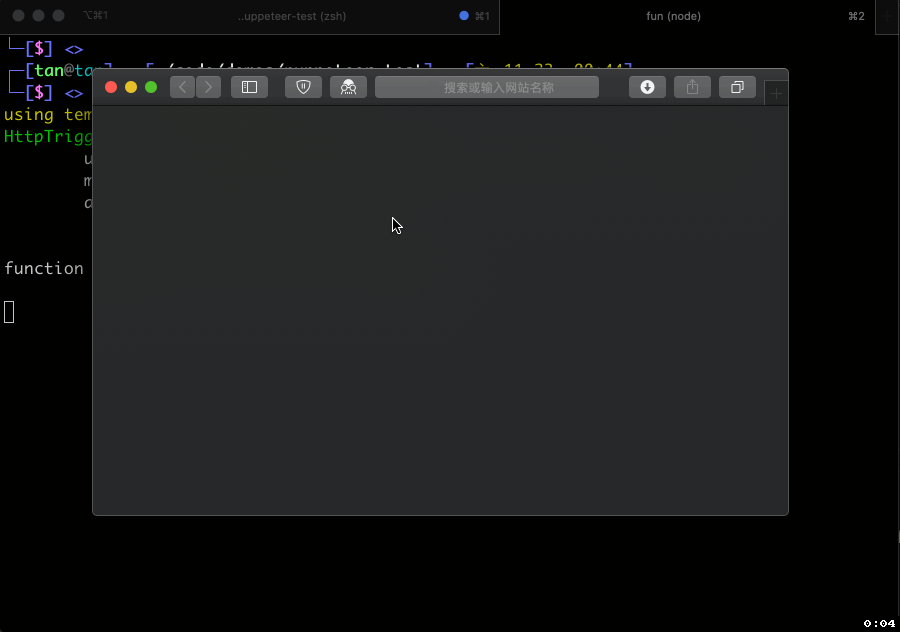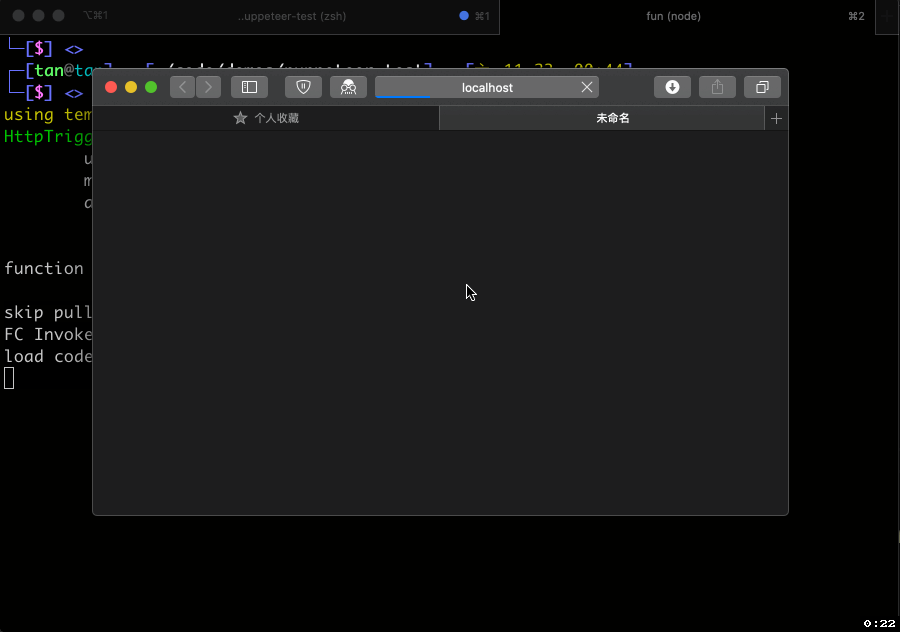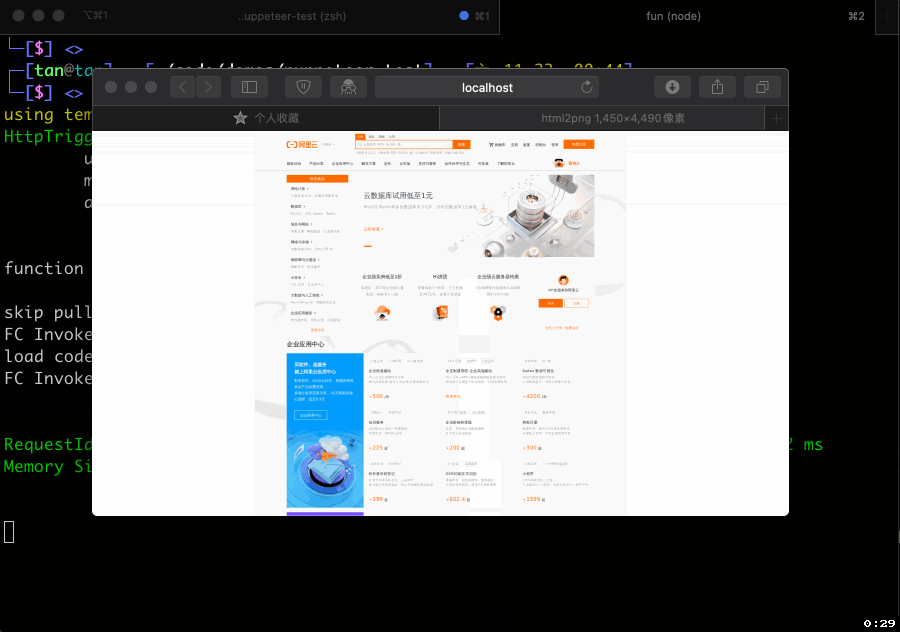
await page.goto('https://www.baidu.com', {
'waitUntil': 'networkidle2'
});
await page.screenshot({ path: '/tmp/example', fullPage: true, type: 'png' });
await browser.close();
package.json 内容如下:
{
... ...
"dependencies": {
"puppeteer": "^2.0.0"
},
... ...
}
可以看到,在 package.json 中声明了 puppeteer 的依赖。这个也是我们使用 node 开发时的标准做法,并无特别之处。
3. 一键安装依赖
puppeteer 的安装,即使是在传统的 linux 机器上,也不是那么的轻松。因为 puppeteer 本身依赖了非常多的系统库,要安装哪些系统库、如何安装这些系统库成了一个比较头痛的问题。
好在函数计算命令行工具 Fun 已经集成了 Puppeteer 的解决方案,只要 package.json 中包含了 puppeteer 依赖,然后使用 fun install -d 即可一键安装所有系统依赖。
fun install -d
4. 本地运行、调试函数
Puppeteer 的本地运行、调试方法与这里介绍的完全一致,我们就不再重复介绍。我们这里只演示下运行效果:
5. 一键部署应用
基本上所有的 FaaS 平台为了减小应用的冷启动,都会设置代码包的限制,函数计算也不例外。而 puppeteer 自身已经达到了 350M 左右,连同其系统依赖已经达到了 450M。如何将 450M 体积的函数部署到 FaaS 平台是一个比较头痛而且繁琐的问题。
函数计算的命令行工具 Fun 现在原生支持了这种大依赖部署(3.1.1 版本仅支持 node runtime)。不需要任何额外操作,仅仅执行 fun deploy:
$ fun deploy
fun 会自动完成依赖的部署。而当检测到打包的依赖超过了平台的限制时,会进入到配置向导,帮助用户自动化地配置。
我们这里推荐的路径是当提示是否由 Fun 自动帮助 NAS 管理是,输入 yes,然后提示提示是否使用 NasConfig: Auto 自动处理 NAS 时,也选择是,之后就不需要做其他的事情,等待函数部署成功即可。

如果有其他的需求,比如想使用自己已经存在的 NAS 服务,可以在提示使用 NasConfig: Auto 时,输入 no,这样就会进入到相应的流程。更详细的说明,请参考下面的 FAQ。
FAQ
在安装 puppeteer 时,Fun 都做了哪些事情?
puppeteer 本身是一个 npm 包,它的安装是非常简单的,通过 npm install 即可。这里的问题在于,puppeteer 依赖了 chromium,而 chromium 又依赖一些系统库。所以 npm install 后,还会触发下载 chromium 的操作。这里用户经常遇到的问题,主要是:
- 由于 chromium 的体积比较大,所以经常遇到网络问题导致下载失败。
- npm 仅仅只下载 chromium,chromium 依赖的系统库并不会自动安装。用户还需要自行查找缺失的依赖进行安装。
Fun 做的优化主要是:
- 通过检测网络环境,对于国内用户,会帮助配置淘宝 NPM 镜像实现加速下载的效果。
- 自动为用户安装 chromium 所缺失的依赖库。
Fun 是如何把大依赖部署到函数计算的?不是有代码包大小的限制吗?
基本上所有的 FaaS 为了优化函数冷启动,都会加入函数代码包大小的限制。函数计算也不例外。但是,Fun 通过内置 NAS(阿里云文件存储) 解决方案,可以一键帮用户创建、配置 NAS,并上传依赖到 NAS 上。而函数计算在运行时,可以自动从 NAS 读取到函数依赖。
为了帮助用户自动化地完成这些操作,Fun 内置了一个向导(3.1.1 版本仅支持 node,后续会支持更多,欢迎 github issue 提需求),在检测到代码体积大小超过平台限制时,会提示是否由 Fun 将其改造成 NAS 的方案,整个向导的逻辑如下:
- 询问是否使用 Fun 来自动化的配置 NAS 管理依赖?(如果回答是,则进入向导,回答否,则继续发布流程)
- 检测用户的 yml 中是否已经配置了 NAS
- 如果已经配置,则提示用户选择已经配置的 NAS 存储函数依赖
- 如果没有配置,则提示用户是否使用 NasConfig: Auto 自动创建 NAS 配置
- 如果选择了是,则帮助用户自动配置 nas、vpc 资源。
- 如果选择了否,则列出用户当前 NAS 控制台上已经有的 NAS 资源,让用户选择
- 无论上面使用哪种方式,最终都会在 template.yml 生成 NAS 以及 VPC 相关的配置
- 根据语言检测,比如 node runtime,会将 node_modules 以及 .fun/root 目录映射到 nas 目录(通过 .nas.yml 实现)
- 自动执行 fun nas sync 帮用户把本地的依赖上传到 NAS 服务
- 自动执行 fun deploy,帮用户把代码上传到函数计算
- 提示帮助信息,对于 HTTP Trigger 的,提示函数的 Endpoint,直接打开浏览器访问即可看到效果
是否可以指定 puppeteer 的版本?
可以的,只需要修改 package.json 中的 puppeteer 的版本,重新安装即可。
函数计算实例中的时区采用的 UTC,是否有办法改为北京时间?
某些网页的显示效果是和时区挂钩的,时区不同,可能会导致显示的内容有差异。使用本文介绍的方法,可以非常容易的使用 puppeteer 的最新版本,而在 puppeteer 的最新版本 2.0 提供了一个新的 API page.emulateTimezone(timezoneId) , 可以非常容易的修改时区。
如果 Puppeteer 后续版本更新后,依赖更多的系统依赖,本文介绍的方法还适用吗?
Fun 内置了 .so 缺失检测机制,当在本地调试运行时,会智能地根据报错识别出缺失的依赖库,然后精准地给出安装命令,可以做到一键安装。
如果添加了新的依赖,如何更新?
如果添加了新的依赖,比如 node_modules 目录添加了新的依赖库,只需要重新执行 fun nas sync 进行同步即可。
如果修改了代码,只需要使用 fun deploy 重新部署即可。由于大依赖和代码通过 NAS 进行了分离,依赖通常不需要频繁变化,所以调用的频率比较低,而 fun deploy 的由于没有了大依赖,部署速度也会非常的快。
除了本文介绍的方法还有哪些方法可以一键安装 puppeteer?
Fun 提供了非常多的依赖安装方式,除了本文介绍的将依赖直接声明在 package.json 中,然后通过 fun install -d 的方式安装外,还有很多其他方法,他们均有各自适用的场景:
- 命令式安装。比如
fun install -f functionName -p npm puppeteer。这种安装方式的好处是即使对 fun 不了解的用户也可以傻瓜式的使用。 - 声明式安装。这种安装方式的好处是提供了类 Dockerfile 的体验,Dockerfile 的大部分指令在这里都是可以直接使用的。通过这种方式声明的依赖,可以通过直接提交到版本仓库。他人拉取代码后,也可以一键安装所有依赖。
- 交互环境安装。这种安装方式的好处是提供了类似传统物理机的安装体验。在交互环境中,大部分 linux 命令都是可以使用的,而且可以不断试错。
总结
本文介绍了一种比较简单易行地从零开始搭建分布式 Puppeteer Web 服务的方法。利用该方法,可以做到不需要关心如何安装依赖、也不需要关系如何上传依赖,顺滑地完成部署。
部署完成后,即可享受函数计算带来的优势,即:
- 无需采购和管理服务器等基础设施,只需专注业务逻辑的开发,可以大幅缩短项目交付时间和人力成本
- 提供日志查询、性能监控、报警等功能快速排查故障
- 免运维,毫秒级别弹性伸缩,快速实现底层扩容以应对峰值压力,性能优异
- 成本极具竞争力

