

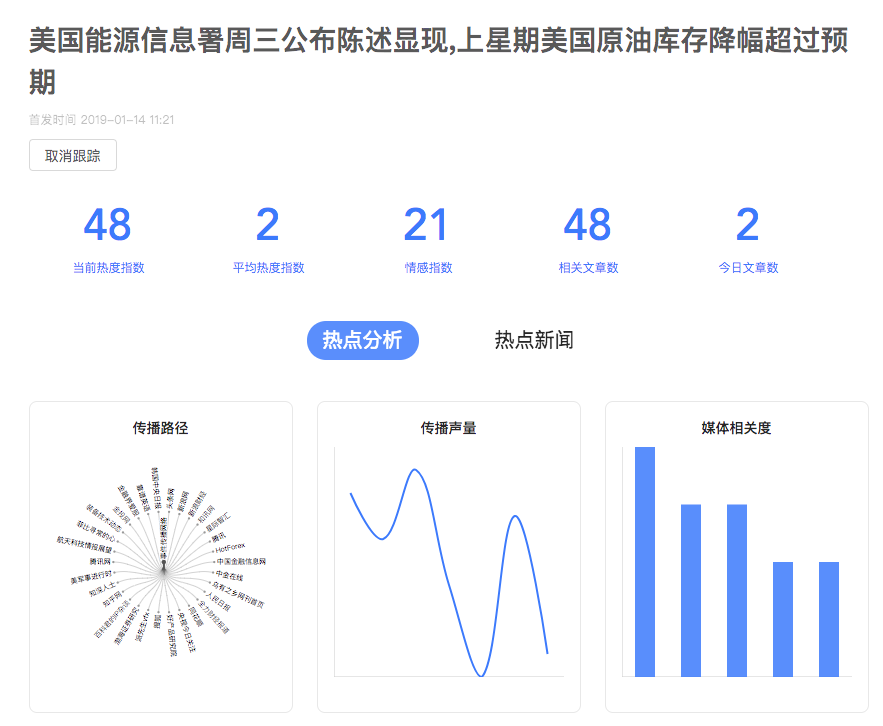
新华智云是一家致力于通过大数据技术驱动媒体变革的公司,数芯是新华智云推出的实时舆情分析平台,旨在满足用户一系列舆情分析需求。包括:对事件、新闻、媒体、人物、地域、机构、行业,甚至关键词、热门话题等的抓取、识别、聚合、热度分析以及可视化展示等。
- 总览

- 事件跟踪

新华智云是一家致力于通过大数据技术驱动媒体变革的公司,数芯是新华智云推出的实时舆情分析平台,旨在满足用户一系列舆情分析需求。包括:对事件、新闻、媒体、人物、地域、机构、行业,甚至关键词、热门话题等的抓取、识别、聚合、热度分析以及可视化展示等。
- 总览
- 事件跟踪

系统设计
网络舆情是社会舆论的一种表现形式,通俗的说是人们通过网络表达对某些社会事件的看法和态度。网络舆情以事件为载体,以事件为核心,是广大网民情感、态度、观点的表达、传播、互动以及后续影响力的总和。
一个舆情分析分析系统,主要解决的问题包括:发现事件、跟踪事件、发掘观点、评估影响力等。
- 系统挑战
- 舆情分析系统需要对接多个上下游
- 数据上游:爬虫数据和采购数据。爬虫采集不同数据结构类型的平台数据。
- 数据下游:写入不同的存储系统。如统计结果写入RDS,清洗后数据写到OTS中,文章存储到ES中做索引等等。
如果设计不合理,多上下游将会极大影响系统复杂度。
- 数据处理过程包括数据清洗和数据统计
- 清洗过程既有基于规则的信息抽取,又有基于算法的实体识别。
- 统计过程需要先把数据结构化拼装,然后按照各种维度进行灵活的统计。
具有自我迭代的能力
设计良好的舆情分析系统应该具有自我迭代的能力,能够根据历史数据进行优化,不断提供系统效能。
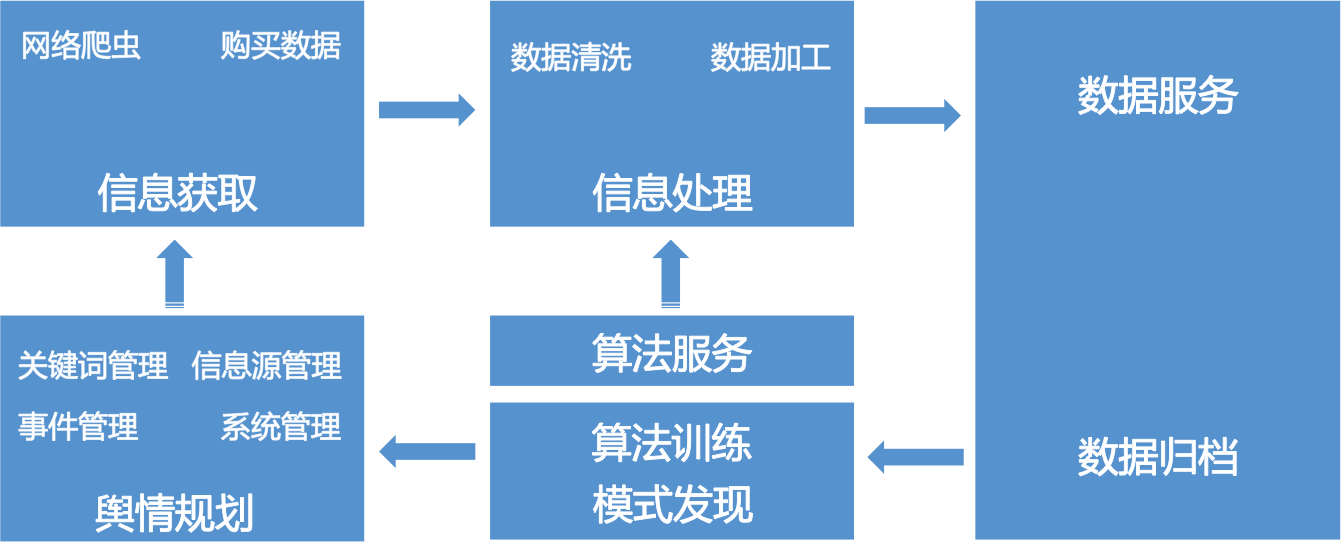
- 系统架构
大数据舆情分析系统架构图如下。

- 舆情规划是整个系统的控制器,控制着舆情发现的目标、信息源等;
- 信息获取是舆情分析的基础,能够快速、准确的获取足量信息是系统成功的前提;
- 信息处理与算法部分是舆情分析的关键,担负着把原始数据加工成信息与知识的重任,并且对归档后的数据进一步分析能够发现系统问题、发现新的事件和新的模型,能够进一步提升系统效果;
- 最终的信息要服务的形式的暴露出来,为人所用;
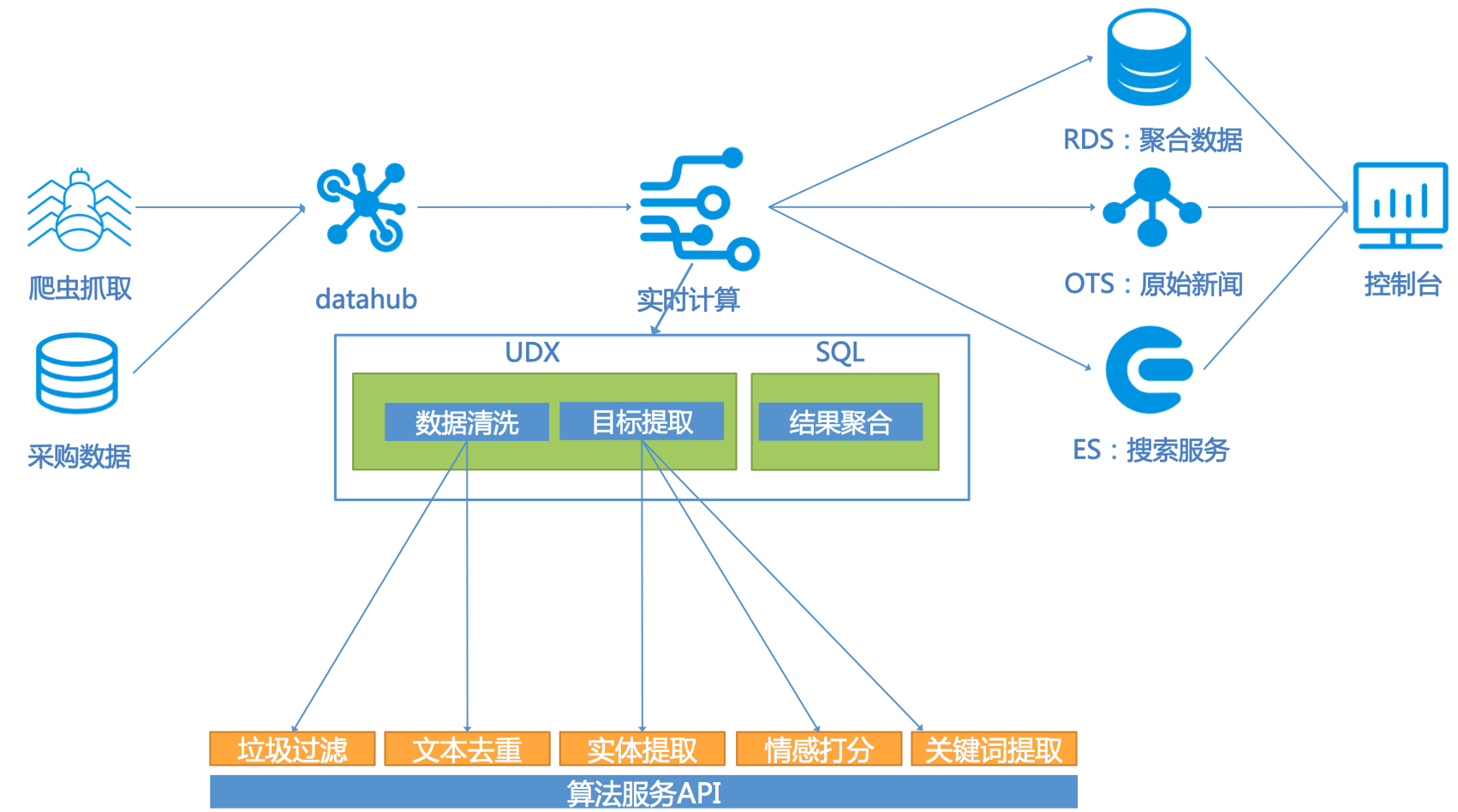
- 信息处理
数芯平台的信息处理部分如下图所示。

- 数据来源(注:数据采集成功后统一发布到DataHub中)
- 爬虫:实时的去各大网站、微博、微信等内容平台抓取数据。
- 从其他机构采集数据。
- 数据处理
实时计算订阅DataHub然后进行数据处理。数据处理包括两个重要的部分:实时数据流和算法服务API。
- 实时数据流
通过实时计算串起整个实时数据流,总体包括对数据进行清洗、提取目标,整理成结构化的数据,然后按照所需维度对结构化的数据进行聚合。并且要把原始数据、结构化的数据、汇总的结果都发布到下游存储系统中。
- 数据清洗:对爬虫抓取的数据进行清洗,比如垃圾过滤、文本去重等。这一步通过实时计算提供的UDX(自定义函数)来调用算法服务API来完成;
- 目标提取:从已经完成清洗的数据中抽取出感兴趣的目标,比如抽取实体(人物、地点、事件等),对内容的情感评分,抽取文章关键词等,这一步的目标是从非结构化的文本中抽取结构化的信息;
- 结果聚合:对已经结构化的数据按维度聚合,比如某事件的按天计数,某新闻的传播热度等。最终把这些聚合信息联合原始信息分别写到下游存储中去。
- 算法服务API
预先训练好模型,把垃圾过滤、文本去重、实体提取、情感打分、关键词提取等暴露成API服务,供实时计算调用。
- 数据存储与服务
RDS保存聚合数据,OTS保存原始新闻,ES对新闻建立索引,提供搜索服务,这三个数据存储直接为最终产品服务。
网络舆情是社会舆论的一种表现形式,通俗的说是人们通过网络表达对某些社会事件的看法和态度。网络舆情以事件为载体,以事件为核心,是广大网民情感、态度、观点的表达、传播、互动以及后续影响力的总和。
一个舆情分析分析系统,主要解决的问题包括:发现事件、跟踪事件、发掘观点、评估影响力等。
- 系统挑战
- 舆情分析系统需要对接多个上下游
- 数据上游:爬虫数据和采购数据。爬虫采集不同数据结构类型的平台数据。
- 数据下游:写入不同的存储系统。如统计结果写入RDS,清洗后数据写到OTS中,文章存储到ES中做索引等等。
- 数据处理过程包括数据清洗和数据统计
- 清洗过程既有基于规则的信息抽取,又有基于算法的实体识别。
- 统计过程需要先把数据结构化拼装,然后按照各种维度进行灵活的统计。
具有自我迭代的能力
设计良好的舆情分析系统应该具有自我迭代的能力,能够根据历史数据进行优化,不断提供系统效能。
- 舆情分析系统需要对接多个上下游
- 系统架构
大数据舆情分析系统架构图如下。
- 舆情规划是整个系统的控制器,控制着舆情发现的目标、信息源等;
- 信息获取是舆情分析的基础,能够快速、准确的获取足量信息是系统成功的前提;
- 信息处理与算法部分是舆情分析的关键,担负着把原始数据加工成信息与知识的重任,并且对归档后的数据进一步分析能够发现系统问题、发现新的事件和新的模型,能够进一步提升系统效果;
- 最终的信息要服务的形式的暴露出来,为人所用;
- 信息处理
数芯平台的信息处理部分如下图所示。
- 数据来源(注:数据采集成功后统一发布到DataHub中)
- 爬虫:实时的去各大网站、微博、微信等内容平台抓取数据。
- 从其他机构采集数据。
- 数据处理
实时计算订阅DataHub然后进行数据处理。数据处理包括两个重要的部分:实时数据流和算法服务API。
- 实时数据流
通过实时计算串起整个实时数据流,总体包括对数据进行清洗、提取目标,整理成结构化的数据,然后按照所需维度对结构化的数据进行聚合。并且要把原始数据、结构化的数据、汇总的结果都发布到下游存储系统中。
- 数据清洗:对爬虫抓取的数据进行清洗,比如垃圾过滤、文本去重等。这一步通过实时计算提供的UDX(自定义函数)来调用算法服务API来完成;
- 目标提取:从已经完成清洗的数据中抽取出感兴趣的目标,比如抽取实体(人物、地点、事件等),对内容的情感评分,抽取文章关键词等,这一步的目标是从非结构化的文本中抽取结构化的信息;
- 结果聚合:对已经结构化的数据按维度聚合,比如某事件的按天计数,某新闻的传播热度等。最终把这些聚合信息联合原始信息分别写到下游存储中去。
- 算法服务API
预先训练好模型,把垃圾过滤、文本去重、实体提取、情感打分、关键词提取等暴露成API服务,供实时计算调用。
- 实时数据流
- 数据存储与服务
RDS保存聚合数据,OTS保存原始新闻,ES对新闻建立索引,提供搜索服务,这三个数据存储直接为最终产品服务。
- 数据来源(注:数据采集成功后统一发布到DataHub中)
总结
数芯之前数据处理部分使用的是自建的spark,需要自行运维和对接各种上下游系统,迁移到了阿里云实时计算平台,整体收益包括:
- 运维成本:免运维,阿里云提供高保障。
- 对接上下游:直接注册,免开发。
- 开发成本:SQL开发,效率高,门槛低。
- 数据流:一个产品串起整个数据流,ETL用UDX,统计用SQL。
从更高的维度上看,这个案例属于实时ETL场景,实时ETL的目标把数据从a投递到b,中间进行清洗、格式转化、信息抽取等。如果对吞吐、实时性有一定要求,可以在方案阶段优先考虑实时计算产品。
数芯之前数据处理部分使用的是自建的spark,需要自行运维和对接各种上下游系统,迁移到了阿里云实时计算平台,整体收益包括:
- 运维成本:免运维,阿里云提供高保障。
- 对接上下游:直接注册,免开发。
- 开发成本:SQL开发,效率高,门槛低。
- 数据流:一个产品串起整个数据流,ETL用UDX,统计用SQL。
从更高的维度上看,这个案例属于实时ETL场景,实时ETL的目标把数据从a投递到b,中间进行清洗、格式转化、信息抽取等。如果对吞吐、实时性有一定要求,可以在方案阶段优先考虑实时计算产品。
注:本文部分内容来自新华智云工程师杨丛聿的分享,特此感谢。
如果您有需求,欢迎联系付空。






