随着JDK的发展,一些设计缺陷或者性能不足的类库难免会被淘汰,最常见的就是Vector、Stack、HashTable和Enumeration了。
Vector(@since 1.0)
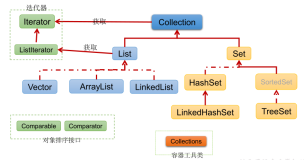
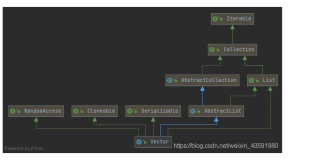
首先看看Vector的UML类图,可以看出,他是一个与ArrayList有着相同继承体系的类,大致功能也和ArrayList一样。Vector与ArrayList最大的不同点在于它是线程安全的,因为其内部几乎所有方法都用了synchronized来修饰。但是,Synchronized是重量级锁,读写操作也没有做适当的并发优化,已经被并发性更好的CopyOnWriteArrayList取代了。所以,当不要求线程安全时,自然会选择ArrayList,如果要求线程安全,往往也会选择CopyOnWriteArrayList或者Collections.synchronizedList()。

Stack(@since 1.0)
Stack是Vector的子类,其内部的方法也都是通过无脑加synchronized来实现的,所以虽然线程安全,但是并发性不高。当不要求线程安全时,会选择LinkedList或者ArrayList(LinkedList的API更接近栈的操作,所以最佳选择是LinkedList),当要求线程安全时,我们会用java.util.concurrent包下的某些类。
再多句嘴,虽然LinkedList的API比较接近栈的操作,但是暴露了许多用不着的方法,这会带来危险。解决方法是编写一个LinkedList的包装类,只暴露与栈相关的方法。
**
* 包装{@code LinkedList},使其仅暴露与栈相关的方法
*/
public class Stack<T> {
private LinkedList<T> list;
public Stack() {
list = new LinkedList<>();
}
public void push(T item) {
list.push(item);
}
public T pop() {
return list.pop();
}
public T peek() {
return list.peek();
}
public boolean isEmpty() {
return list.isEmpty();
}
@Override
public String toString() {
return list.toString();
}
}Hashtable(@since JDK1.0)
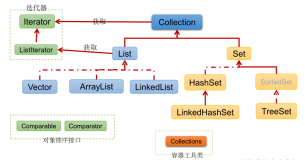
首先看看Hashtable的UML类图,关键点是其实现了Map接口,所以它是一个存储键值对的容器。通过查看源码,我们知道,其是一个线程安全的类,而且还是用synchronized来实现的,所以并发性不高。所以,当面对不要求线程安全的应用场景时我们会用HashMap代替,要求线程安全的应用场景我们往往也会用ConcurrentHashMap或者Collections.synchronizedMap()来代替。 
再再多句嘴,它与HashMap还有一个比较出名的不同点,就是它的散列表实现算法是用线性探测法实现的,该算法要求key不能为null,不然删除键值对时会出问题。另外还要求value不能为null。具体见源码。
public synchronized V put(K key, V value) {
// Make sure the value is not null
if (value == null) { //value不能为null
throw new NullPointerException();
}
// Makes sure the key is not already in the hashtable.
Entry<?,?> tab[] = table;
int hash = key.hashCode(); //key不可以为null
int index = (hash & 0x7FFFFFFF) % tab.length;
@SuppressWarnings("unchecked")
Entry<K,V> entry = (Entry<K,V>)tab[index];
for(; entry != null ; entry = entry.next) {
if ((entry.hash == hash) && entry.key.equals(key)) {
V old = entry.value;
entry.value = value;
return old;
}
}
addEntry(hash, key, value, index);
return null;
}
public synchronized boolean contains(Object value) {
if (value == null) {
throw new NullPointerException();//value不能为null
}
Entry<?,?> tab[] = table;
for (int i = tab.length ; i-- > 0 ;) {
for (Entry<?,?> e = tab[i] ; e != null ; e = e.next) {
if (e.value.equals(value)) {
return true;
}
}
}
return false;
}Enumeration(@since JDK1.0)
Enumeration是否是JDK的“弃儿”其实是有争论的,有人认为,有了Iterator的存在,Enumeration存在的意义就仅仅是兼容老API(比如Vector、Hashtable)了;又有人认为,Enumeration提供了比Iterator更明确的语义(明确不希望对象被执行移除操作)。
1 * NOTE: The functionality of this interface is duplicated by the Iterator
2 * interface. In addition, Iterator adds an optional remove operation, and
3 * has shorter method names. New implementations should consider using
4 * Iterator in preference to Enumeration.
5 这个接口的功能与Iterator接口重复了。此外,Iteraotr还有一个可选的remove()方法和更短的名字,新应用应该优先考虑Iterator。总之,根据API的说明,我们得知,新应用应优先考虑Iterator接口。
再再再多句嘴,万一要面对Enumeration,又想有个关于迭代的统一接口,可以使用适配器模式来处理Enumeration。
**
* 把Enumeration接口转换成Iterator接口的适配器
* 适配器模式中的角色 - adaptor
*/
public class EnumerationIterator<E> implements Iterator<E> {
/**
* 被适配的接口
* 适配器模式中的角色 - adaptee
*/
private Enumeration<E> enums;
public EnumerationIterator(Enumeration<E> enums) {
this.enums = enums;
}
@Override
public boolean hasNext() {
return enums.hasMoreElements();
}
@Override
public E next() {
return enums.nextElement();
}
/**
* 因为Enumeration接口不支持remove操作,所以这里简单地抛出异常
*/
@Override
public void remove() {
throw new UnsupportedOperationException();
}
}总结
Vector、Stack、Hashtable由于其自身的设计不足而且又有替代的工具,所以在新项目中已难寻其踪。Iterator的强大功能也使Enumeration处境尴尬,也已经很少见到了。