
1 TPU分类和收费标准
1.1 分类和计费说明
| 地区 | 抢占式TPU | Cloud TPU |
|---|---|---|
| 美国 | $1.35/hour | $4.5/hour |
| 欧洲 | $1.485/hour | $4.95/hour |
| 亚太区地区 | $1.566/hour | $5.22/hour |
- 抢占式 TPU 是 Cloud TPU 在需要将资源分配给另一项任务时,可以随时终止(抢占)的 TPU。抢占式 TPU 的费用要比普通 TPU 低廉得多。
- TPU 以 1 秒钟为增量单位进行计费。
为了连接到 TPU,我们必须配置一台虚拟机(单独结算)。要注意的是虚拟机和TPU是分别计费的。
也就是说仅在启动 TPU 之后,Cloud TPU 的计费才会开始;在停止或删除 TPU 之后,计费随即停止。运行 ctpu pause 或 gcloud compute tpus stop 即可停止 TPU。同样,只有在虚拟机激活之后,我们才会向您收取虚拟机费用。
如果虚拟机已停止,而 Cloud TPU 未停止,您需要继续为 Cloud TPU 付费。如果 Cloud TPU已停止或删除,而虚拟机未停止,则您需要继续为虚拟机付费。
1.2 实用查询链接
1.3 价格计算实例
以下示例解释了如何计算一项训练作业的总费用,该作业使用美国区域的 TPU 资源和 Compute Engine 实例。
一家机器学习研究机构通过创建 Compute Engine 实例预配了一台虚拟机,他们选择的是 n1-standard-2 机器类型。他们还创建了一项 TPU 资源,其 Compute Engine 实例和 TPU 资源的累计使用时间都是 10 小时。为了计算该训练作业的总费用,这家机器学习研究机构必须将以下几项相加在一起:
- 所有 Compute Engine 实例的总费用
- 所有 Cloud TPU 资源的总费用
| 资源 | 每小时每台机器的价格(美元 | ) 机器数量 | 计费小时数 | 各资源总费用 | 训练作业总费用 |
|---|---|---|---|---|---|
| Compute Engine n1-standard-2 实例 | $0.095 | 1 | 10 | $0.95 | _ |
| Cloud TPU 资源 | $4.50 | 1 | 10 | $45.00 | _ |
| $45.95 |
使用抢占式 TPU 的价格示例
在以下示例中,使用的资源和时长与上例相同,但这一次该研究机构决定使用抢占式 TPU 来节省成本。抢占式 TPU 的费用是每小时 $1.35,而非普通 TPU 的每小时 $4.50。
| 资源 | 每小时每台机器的价格(美元 | ) 机器数量 | 计费小时数 | 各资源总费用 | 训练作业总费用 |
|---|---|---|---|---|---|
| Compute Engine n1-standard-2 实例 | $0.095 | 1 | 10 | $0.95 | - |
| 抢占式 TPU | $1.35 | 1 | 10 | $13.50 | - |
| $14.45 |
2 使用步骤
2.1 创建GCP project
点击链接Google Cloud Platform之后会进入这样一个界面:
点击创建项目,输入项目名,等一会项目就会创建成功,有时可能需要刷新一下网页项目才会出现。

2.2 创建Cloud Storage bucket
Cloud Storage 简单来说就是用来存储模型训练数据和训练结果的。官方的解释是它是适用于非结构化对象的一种功能强大且经济有效的存储解决方案,非常适合托管实时网页内容、存储用于分析的数据、归档和备份等各种服务。
注意:要想使用Cloud Storage,需要启用结算功能。
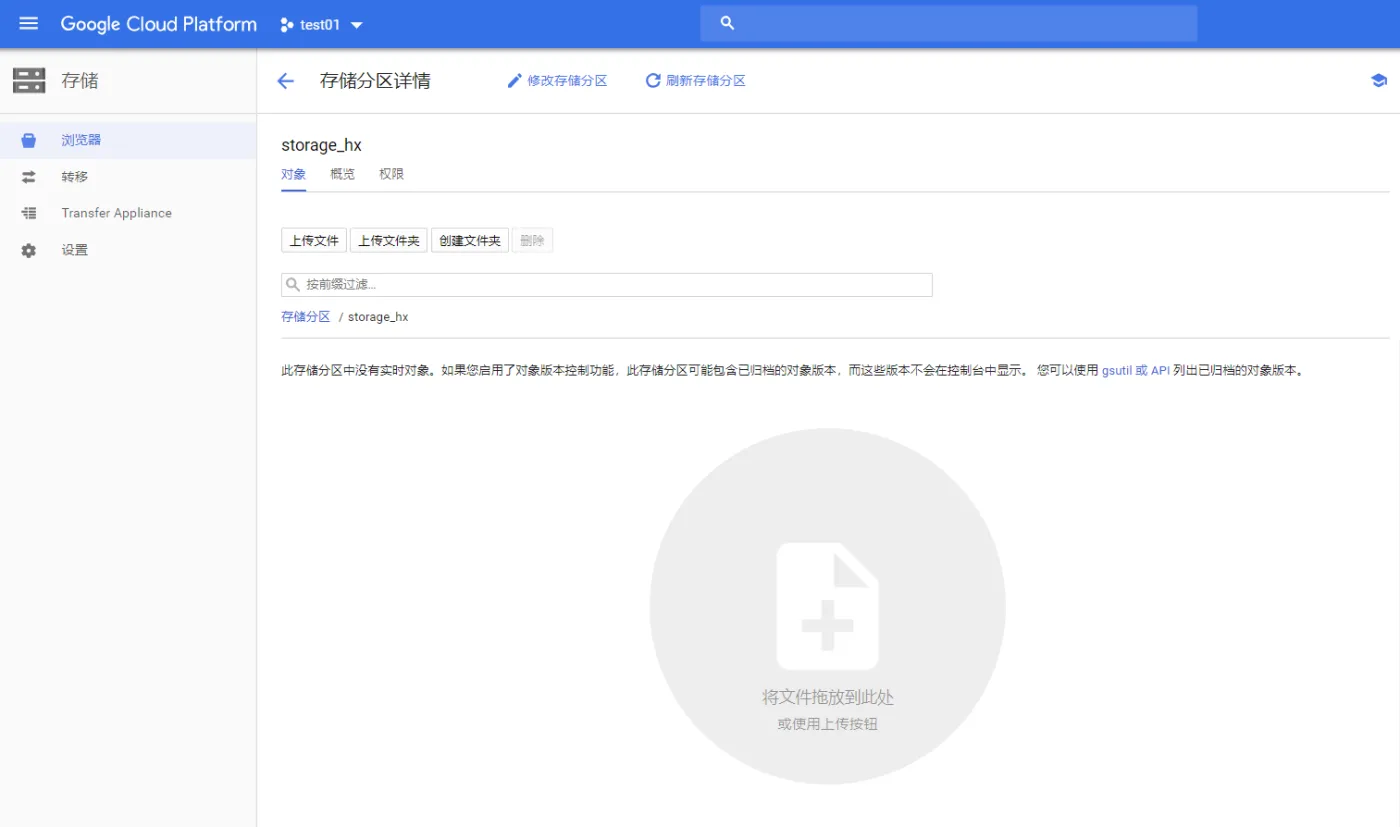
2.2.1 创建存储分区
存储分区用于保存您要在 Cloud Storage中存储的对象(任何类型的文件)。
- 首先在控制台左侧选择 【存储】(如下图示(中英文))就能进入Cloud Storage页面了,


-
之后点击 【创建存储分区】

输入storage名即可创建完成,注意名称需要是unique的,否则无法创建成功。
2.2.2 上传和共享对象
要开始使用您的存储分区,只需上传对象并开放其访问权限即可。
2.2.3 清理
在最后一步中,您将删除之前为本教程创建的存储分区和对象。
2.3 打开Cloud Shell,使用ctpu工具
Shell在控制台右上角,如下图示:

输入ctpu print-config可以查看配置信息。我的输入结果是这样的:
ctpu configuration:
name: hkbuautoml
project: test01-219602
zone: us-central1-b
If you would like to change the configuration for a single command invocation, please use the command line flags.
2.3.1 创建Computer Engine VM和TPU
命令为:ctpu up [optional: --name --zone]
注意: name只能用小写字母和数字组成,大写字母或者其他字符都会报错。
这里我创建了一个名为tputest的tpu。输入y确认创建。
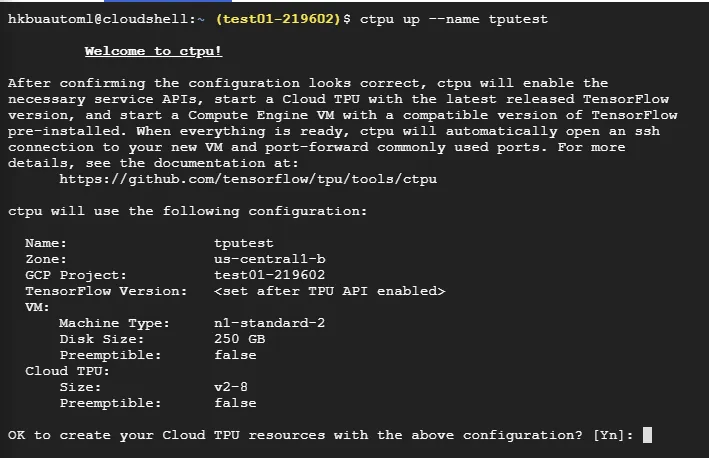
上面的ctpu up命令主要做了如下几件事:
- 开启Computer Engine和Cloud TPU服务
- 创建预装有最新稳定版本TensorFlow的Computer Engine VM。其中默认的Zone是
us-central1-b。 - 使用TensorFlow的相应版本创建Cloud TPU,并将Cloud TPU的名称作为环境变量(
TPU _ NAME)传递给Computer Engine VM。 - 通过向Cloud TPU服务帐户授予特定的IAM角色(见下图),确保您的Cloud TPU可以从GCP项目中获得所需的资源。
- 执行其他的检查。
- 将您登录到新的Compute Engine VM。
2.3.2 检查是否登录成功
当成功登录VM后,我们可以看到shell prompt已经由username@project 转变成username@tpuname。

2.3.3 运行一个TensorFlow程序
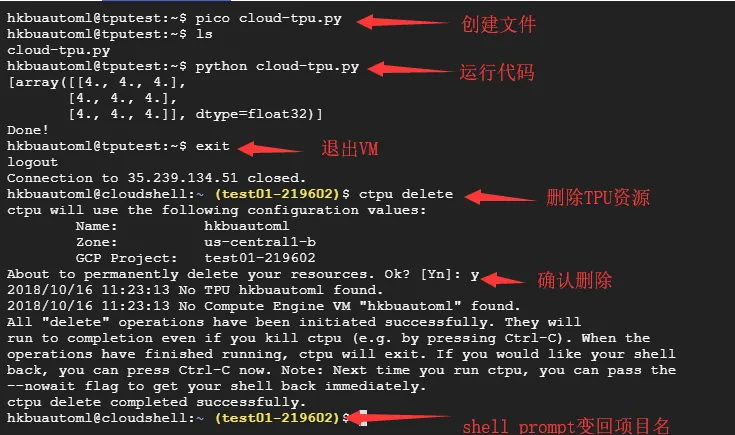
- 创建代码文件
pico cloud-tpu.py
示例代码如下
import os
import tensorflow as tf
from tensorflow.contrib import tpu
from tensorflow.contrib.cluster_resolver import TPUClusterResolver
def axy_computation(a, x, y):
return a * x + y
inputs = [
3.0,
tf.ones([3, 3], tf.float32),
tf.ones([3, 3], tf.float32),
]
tpu_computation = tpu.rewrite(axy_computation, inputs)
tpu_grpc_url = TPUClusterResolver(
tpu=[os.environ['TPU_NAME']]).get_master()
with tf.Session(tpu_grpc_url) as sess:
sess.run(tpu.initialize_system())
sess.run(tf.global_variables_initializer())
output = sess.run(tpu_computation)
print(output)
sess.run(tpu.shutdown_system())
print('Done!')运行代码,结果如下:
[array([[4., 4., 4.],
[4., 4., 4.],
[4., 4., 4.]], dtype=float32)]
Done!2.3.4 释放资源
代码跑完后切记要释放资源,否则系统会继续计费。释放资源方法如下:
1. 断开与Computer Engine VM的连接:
(vm)$ exit成功断开之后shell prompt会变成项目名而不是VM名。
2. 删除Computer Engine VM和Cloud TPU
$ ctpu delete!!!特别注意:如果在创建VM的时候指定了name,name在删除的时候同业也要指定name。我在删除的时候没有加name,虽然命令行结果显示删除成功,但是后面我在控制台查看资源使用情况,发现VM实例依旧存在。所以最保险的办法是命令输完后,去控制台看看实例是否还存在。

3. 删除Storage
命令为:gsutil rm -r gs://Your-storage-name

更详细的资料可参考官方文档。
MARSGGBO原创
2018-10-16




