目录
- 前言
- GPU架构
- GPU处理单元
- 概念GPU
- GPU线程与SM
- GPU线程
- SM
- 加法
- 统一内存
- 乘法
- 最后
前言
在实际CUDA编程之前, 先来了解下GPU的结构. 和CPU相比显得粗暴又强大(手动滑稽).


GPU架构
GPU处理单元

从这张GPU概念内核图开始讲起, 会发现和CPU内核是不同的, 少了三级缓存, 分支预测等等. 但是增加了ALU的数量, 扩大了上下文存储池(Pool of context storge).
可以看到, 上下文存储池分成4份, 也就是说, 可以执行4条指令流, 比方说指令1阻塞, 立马切换指令2, 指令2阻塞切换指令3, 这就起到了隐藏延迟的效果. 当然数量到底是多少是很讲究的, 不是越多越好.
总的来看, 内核含8个ALU, 4组执行环境(Execution context), 每组有8个Ctx. 这样, 一个这样的内核可以并发(concurrent but interleaved)执行4条指令流(instruction streams), 32个并发程序片元(fragment).
概念GPU
复制16个上述的处理单元, 得到一个GPU. 实际肯定没有这么简单的, 所以说是概念GPU.

这个GPU含16个处理单元, 128个ALU, 64组执行环境(Execution context), 512个并发程序片元(fragment).
祭出n多年前的卡皇GTX 480, 有480个CUDA核(也就是ALU), 内存带宽177.4GB/s. 而GTX 980 Ti有2816个CUDA核, 内存带宽336.5GB/s.
但是带宽依旧是瓶颈, 虽然比CPU带宽高了一个数量级, 但是可以看到, GTX 980 Ti的带宽也就是多年前GTX 480的两倍左右.
GPU线程与SM
由于目前还没有完全依靠GPU运行得机器, 一般来说, 都是异构的, CPU+GPU. 这一点是要特别注意的, 也就是Host与Device.

GPU线程
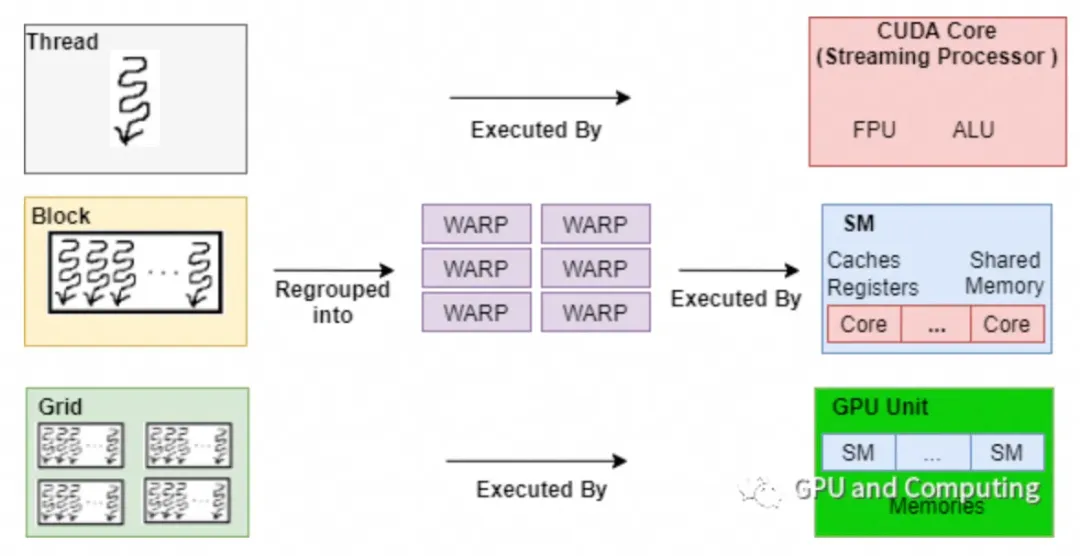
在CUDA架构下, 显示芯片执行时的最小单位是thread. 数个thread可以组成一个block. 一个block中的thread能存取同一块共享的内存, 而且可以快速进行同步的动作. 不同block中的thread无法存取同一个共享的内存, 因此无法直接互通或进行同步. 因此, 不同block中的thread能合作的程度是比较低的. 上图:


然后依据thread, block和grid, 有着不同的存储. 核心就是thread. 可以结合下图进行理解:

- 每个处理器上有一组本地32位寄存器(Registers);
- 并行数据缓存或共享存储器(Shared Memory), 由所有标量处理器核心共享, 共享存储器空间就位于此处;
- 只读固定缓存(Constant Cache), 由所有标量处理器核心共享, 可加速从固定存储器空间进行的读取操作(这是设备存储器的一个只读区域);
- 一个只读纹理缓存(Texture Cache), 由所有标量处理器核心共享, 加速从纹理存储器空间进行的读取操作(这是设备存储器的一个只读区域), 每个多处理器都会通过实现不同寻址模型和数据过滤的纹理单元访问纹理缓存.

SM

看到上图, GPU硬件的一个核心组件是SM, SM是英文名是Streaming Multiprocessor, 翻译过来就是流式多处理器. SM的核心组件包括CUDA核心, (其实就是ALU, 如上图绿色小块就是一个CUDA核心)共享内存, 寄存器等, SM可以并发地执行数百个线程, 并发能力就取决于SM所拥有的资源数. 当一个kernel被执行时, 它的gird中的线程块被分配到SM上, 一个线程块只能在一个SM上被调度. SM一般可以调度多个线程块, 这要看SM本身的能力. 那么有可能一个kernel的各个线程块被分配多个SM, 所以grid只是逻辑层, 而SM才是执行的物理层.
下图是我GT 750M的显卡信息:

SM采用的是SIMT(Single-Instruction, Multiple-Thread, 单指令多线程)架构, 基本的执行单元是线程束(wraps), 线程束包含32个线程, 这些线程同时执行相同的指令, 但是每个线程都包含自己的指令地址计数器和寄存器状态,也有自己独立的执行路径.
加法
试着用CUDA编程做一个矩阵加法:
#include <stdio.h>
__global__ void add(float * x, float *y, float * z, int n){
int index = threadIdx.x + blockIdx.x * blockDim.x;
int stride = blockDim.x * gridDim.x;
for (int i = index; i < n; i += stride){
z[i] = x[i] + y[i];
}
}
int main(){
int N = 1 << 20;
int nBytes = N * sizeof (float);
float *x, *y, *z;
x = (float*)malloc(nBytes);
y = (float*)malloc(nBytes);
z = (float*)malloc(nBytes);
for (int i = 0; i < N; i++){
x[i] = 10.0;
y[i] = 20.0;
}
float *d_x, *d_y, *d_z;
cudaMalloc((void**)&d_x, nBytes);
cudaMalloc((void**)&d_y, nBytes);
cudaMalloc((void**)&d_z, nBytes);
cudaMemcpy((void*)d_x, (void*)x, nBytes, cudaMemcpyHostToDevice);
cudaMemcpy((void*)d_y, (void*)y, nBytes, cudaMemcpyHostToDevice);
dim3 blockSize(256);
// 4096
dim3 gridSize((N + blockSize.x - 1) / blockSize.x);
add << < gridSize, blockSize >> >(d_x, d_y, d_z, N);
cudaMemcpy((void*)z, (void*)d_z, nBytes, cudaMemcpyDeviceToHost);
float maxError = 0.0;
for (int i = 0; i < N; i++){
maxError = fmax(maxError, (float)(fabs(z[i] - 30.0)));
}
printf ("max default: %.4f\n", maxError);
cudaFree(d_x);
cudaFree(d_y);
cudaFree(d_z);
free(x);
free(y);
free(z);
return 0;
}
由于我是用mac ssh访问linux主机的, 所以看中文都是乱码的, 就没打注释. 简单说下.
- 逻辑部分:
申请1M的float, 放入10.0. 申请1M的float, 放入20.0, 然后加起来. 但是我们不存在直接看结果的. 就循环计算误差值, 输出最大的那个误差值. 最后看到是0就代表全部计算正确了.- CUDA部分:
cudaMalloc((void**)&d_x, nBytes);是很抢眼的, 意思也很简单, 在GPU中申请空间, 而不是CPU.用
cudaMemcpy((void*)d_x, (void*)x, nBytes, cudaMemcpyHostToDevice);将CPU中的数据放入到GPU, 注意第二个是源数据, 第三个是方向.dim3 blockSize(256);猜猜也知道了, 就是申请256个block.dim3 gridSize()同理.
最后cudaMemcpy((void*)z, (void*)d_z, nBytes, cudaMemcpyDeviceToHost);从GPU中把结果拷贝回CPU, 注意第三个参数和之前的不同.
记得释放申请的空间.
统一内存
时不我待. 在高版本的CUDA中, 升级了申请空间的操作. CUDA 6.x引入统一内存(Unified Memory). 具体内容建议查阅我给出的链接, 说的非常细致. 简单来说, 就是申请一次就好, 不用先CPU后GPU, 再拷贝来拷贝去, 太傻.
#include <stdio.h>
__global__ void add(float * x, float *y, float * z, int n){
// 同之前, 略
}
int main()
{
int N = 1 << 20;
int nBytes = N * sizeof(float);
float *x, *y, *z;
cudaMallocManaged((void**)&x, nBytes);
cudaMallocManaged((void**)&y, nBytes);
cudaMallocManaged((void**)&z, nBytes);
for (int i = 0; i < N; ++i)
{
x[i] = 10.0;
y[i] = 20.0;
}
dim3 blockSize(256);
// 4096
dim3 gridSize((N + blockSize.x - 1) / blockSize.x);
add << < gridSize, blockSize >> >(x, y, z, N);
cudaDeviceSynchronize();
float maxError = 0.0;
for (int i = 0; i < N; i++){
maxError = fmax(maxError, (float)(fabs(z[i] - 30.0)));
}
printf ("max default: %.4f\n", maxError);
cudaFree(x);
cudaFree(y);
cudaFree(z);
return 0;
}
之前看起来有多蠢, 现在就有多简洁(手动滑稽). 注意到
cudaMallocManaged((void**)&x, nBytes);, 这样的申请就无需再拷贝操作了.cudaDeviceSynchronize();同步device, 保证结果能正确访问. 具体原理请参看之前链接.
乘法
学过线性代数的都知道矩阵乘法是那种不难单头疼的工作, 原来可能用MATLAB偷懒, 现在可以考虑CUDA了(手动滑稽).
先定义一个Matrix:
struct Matrix
{
int width;
int height;
float *elements;
};定义矩阵操作函数和乘法函数:
__device__ float getElement(Matrix *A, int row, int col)
{
return A->elements[row * A->width + col];
}
__device__ void setElement(Matrix *A, int row, int col, float value)
{
A->elements[row * A->width + col] = value;
}
__global__ void matMulKernel(Matrix *A, Matrix *B, Matrix *C)
{
float Cvalue = 0.0;
int row = threadIdx.y + blockIdx.y * blockDim.y;
int col = threadIdx.x + blockIdx.x * blockDim.x;
for (int i = 0; i < A->width; ++i)
{
Cvalue += getElement(A, row, i) * getElement(B, i, col);
}
setElement(C, row, col, Cvalue);
}主函数并不难写, 主要是理解调度原理:
int main()
{
int width = 1 << 10;
int height = 1 << 10;
Matrix *A, *B, *C;
cudaMallocManaged((void**)&A, sizeof(Matrix));
cudaMallocManaged((void**)&B, sizeof(Matrix));
cudaMallocManaged((void**)&C, sizeof(Matrix));
int nBytes = width * height * sizeof(float);
cudaMallocManaged((void**)&A->elements, nBytes);
cudaMallocManaged((void**)&B->elements, nBytes);
cudaMallocManaged((void**)&C->elements, nBytes);
A->height = height;
A->width = width;
B->height = height;
B->width = width;
C->height = height;
C->width = width;
for (int i = 0; i < width * height; ++i)
{
A->elements[i] = 1.0;
B->elements[i] = 2.0;
}
dim3 blockSize(32, 32);
dim3 gridSize((width + blockSize.x - 1) / blockSize.x,
(height + blockSize.y - 1) / blockSize.y);
matMulKernel << < gridSize, blockSize >> >(A, B, C);
cudaDeviceSynchronize();
float maxError = 0.0;
for (int i = 0; i < width * height; ++i)
maxError = fmax(maxError, fabs(C->elements[i] - 2 * width));
printf ("max fault: %f\n", maxError);
return 0;
}和加法差不多, 就是多些矩阵操作. 不多说了~
然后矩阵计算代码参考这篇文章.
最后
CUDA近期就先更到这里, 下次一更新应该是内核必须懂部分的. 喜欢记得点赞哦, 有意见或者建议评论区见~