欢迎来到深入学习Kubernetes API Server的系列文章,在本系列文章中我们将深入的探究Kubernetes API Server的相关实现。如果你对Kubernetes的内部实现机制比较感兴趣或者正在进行Kubernetes项目的相关开发工作,那么本系列文章能够为你提供一些帮助。了解学习过go语言,会在某些方面帮助你更好的理解本系列文章。
在本期文章中,我们首先会对Kubernetes API Server进行一个总体的大致说明,然后对API的技术术语及请求流作说明。在下几期的文章中则主要对API Server与etcd存储的交互以及对API Server进行相关扩展进行探讨,说明。
API Server的总体说明
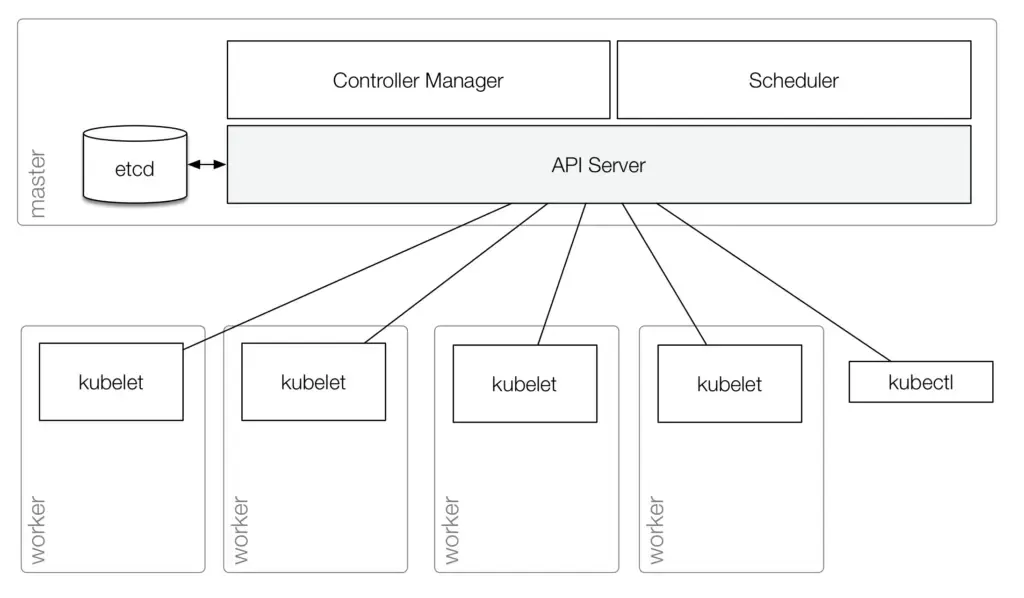
从理论上来说,Kubernetes 是由一些具有不同角色的节点组成的。作为控制面的主节点主要部署有API Server, Controller Manager 和 Scheduler(s)等组件。API Server作为Kubernetes 中的管理中心,是唯一能够与存储etcd交互通信的组件。它主要能够提供如下服务:
1.作为Kubernetes API的服务端,为集群内的节点以及kubectl工具提供API服务。
2.作为集群组件的代理,例如Kubernetes UI
3.通过API Server能够对Kubernetes的API对象比如pods,services进行增删查改等操作。
4.保证在分布式存储系统(etcd)中的Kubernetes API对象的状态一致。
Kubernetes API是一个HTTP形式的API,JSON格式是它主要的序列化架构。同时它也支持协议缓冲区(Protocol Buffers)的形式,这种形式主要是用在集群内通信中。出于可扩展性原因考虑,Kubernetes可支持多个API版本,通过不同的API路径的方式区分。比如/api/v1 和 /apis/extensions/v1beta1,不同的API版本代表了这个API处于不同的版本稳定性阶段。
1.Alpha 阶段,比如v1alpha1,在默认状态下为关闭状态。只在某个分支中支持使用,在将来可能会2.Beta阶段,比如v2beta3,在默认状态下为开启状态。表示这部分代码已经经过测试,基本功能已经通过验证。但是这个状态的API对象将来还是有可能发生不可兼容的改动以过度到stable稳定阶段。
3.Stable阶段,比如v1,是一个稳定的软件发布阶段,API对象一般之后不会有太大改动。
接下去,我们介绍一下HTTP API主要结构。首先我们需要区分三种不同的API形式:core group API(在/api/v1路径下,由于某些历史原因而并没有在/apis/core/v1路径下)和named groups API(在对应的/apis/$NAME/$VERSION路径下)及system-wide API(比如/metrics,/healthz)。
一个HTTP API的主要结构如下所示:

接下去我们主要列举batch group下的两个API例子来讲解说明。在Kubernetes 1.5版本中,batch群组下有/apis/batch/v1 和 /apis/batch/v2alpha1两个API版本来供开发者使用。我们来看一下API的整体实现(下面列举的API例子我们是通过proxy 命令kubectl proxy --port=8080直接访问API获得)。
$ curl http://127.0.0.1:8080/apis/batch/v1
{
"kind": "APIResourceList",
"apiVersion": "v1",
"groupVersion": "batch/v1",
"resources": [
{
"name": "jobs",
"namespaced": true,
"kind": "Job"
},
{
"name": "jobs/status",
"namespaced": true,
"kind": "Job"
}
]
}
在将来,将会使用更新的alpha版本:
$ curl http://127.0.0.1:8080/apis/batch/v2alpha1
{
"kind": "APIResourceList",
"apiVersion": "v1",
"groupVersion": "batch/v2alpha1",
"resources": [
{
"name": "cronjobs",
"namespaced": true,
"kind": "CronJob"
},
{
"name": "cronjobs/status",
"namespaced": true,
"kind": "CronJob"
},
{
"name": "jobs",
"namespaced": true,
"kind": "Job"
},
{
"name": "jobs/status",
"namespaced": true,
"kind": "Job"
},
{
"name": "scheduledjobs",
"namespaced": true,
"kind": "ScheduledJob"
},
{
"name": "scheduledjobs/status",
"namespaced": true,
"kind": "ScheduledJob"
}
]
}
总体上来说Kubernetes API支持对API对象的增删查改( create, update, delete, retrieve)通过使用JSON作为默认格式的HTTP (POST, PUT, DELETE, GET)方式来实现。
大多数API对象会区分对象想要达到的预期状态以及当前对象所处的实际状态。所以一个规范的API描述应该对于这两种状态都有完整的描述说明并在储存(etcd)中记录。
API Server的术语说明
在对API Server以及HTTP API结构进行总体说明后,接下去我们对一些术语来进行说明解释。Kubernetes 的主要API对象主要有pods, services, endpoints, deployment等。一个API对象主要由以下条目
Kind:是一个API对象的类型。它告诉了client(比如kubectl)这种API对象所代表的实体类型。比如一个pod
apiVersion: v1
kind: Pod
metadata:
name: webserver
spec:
containers:
- name: nginx
image: nginx:1.9
ports:
- containerPort: 80
目前API中有三种Kinds类型:
1.Object对象代表了系统中持久存在的实体,一个object对象可能具有多个resources资源能让客户端来执行一些特定的操作。比如Pod和namespace.
2.Lists 代表了一些resources资源或者object实体对象的集合。比如PodLists和 NodeLists.
3.代表了一个对实体对象的操作或一个非实体存在的状态过程。比如binding或者status等。
API Group :是一组相关的Kind的集合。比如在Kind:Job以及Kind:ScheduleJob都属于batch的API Group.
Version:每个API Group下面都能存在有多个version版本。比如在一个group群组中最早有第一个v1alpha1版本,后来中间发展到了v1beta1版本,最终发展到v1的稳定版本。如果在系统创建了一个v1beta1 版本的对象,那么它能过被Group任一支持的版本(比如v1)检索到。这是由于API server能够支持不同版本对象之间的无损耗转换。
Resource :代表以JSON格式通过HTTP发送或检索的资源实体。它既可以使一个单独的resource资源(比如.../namespaces/default)也可以是一组resource 资源(比如.../jobs)
一个API Group群组,一个Version版本,一个Resource(GVR)资源就能过定义一个唯一的HTTP路径。

实际上,一个job对象的API路径为/apis/batch/v1/namespaces/$NAMESPACE/jobs,因为jobs并不是cluster侧的资源,所以需要有namespace字段。与之相对node作为cluster侧的资源,它的API路径就没有$NAMESPACE的部分。
值得注意的是Kinds不一定只在同一个Group群组下存在不同的Version版本,它在不同的Group群组也有可能存在不同的Version版本。比如Deployment 一开始在extensions group群组中作为alpha版本存在,但最后它发展成GA version版本时拥有了一个新的独立的Group群组apps.k8s.io。因此,如果想要区分唯一的Kinds,必须要有API Group,Version以及Kind(GVK)三部分。
API请求流过程
在对Kubernetes API中的术语有了了解之后,接下去我们将讨论API请求的处理流程。相关API主要在k8s.io/pkg/api可以看到,它既处理来自集群内的API请求也处理来自集群外的API请求。
当API Server接收到一个HTTP的Kubernetes API请求时,它主要处理流程如下所示:
1.HTTP 请求通过一组定义在DefaultBuildHandlerChain()(config.go)函数中的过滤处理函数处理,并进行相关操作(相关过滤处理函数如下图所示)。这些过滤处理函数将HTTP请求处理后存到中ctx.RequestInfo,比如用户的相关认证信息,或者相应的HTTP请求返回码。
2.接着multiplexer (container.go)基于HTTP路径会将HTTP请求发给对应的各自的处理handlers。
3.routes (在routes/*定义)路由将HTTP路径与handlers处理器关联。
4.根据每个API Group注册的处理程序获取HTTP请求相关内容对象(比如用户,权限等),并将请求的内容对象存入存储中。
完整的处理流程如下图所示
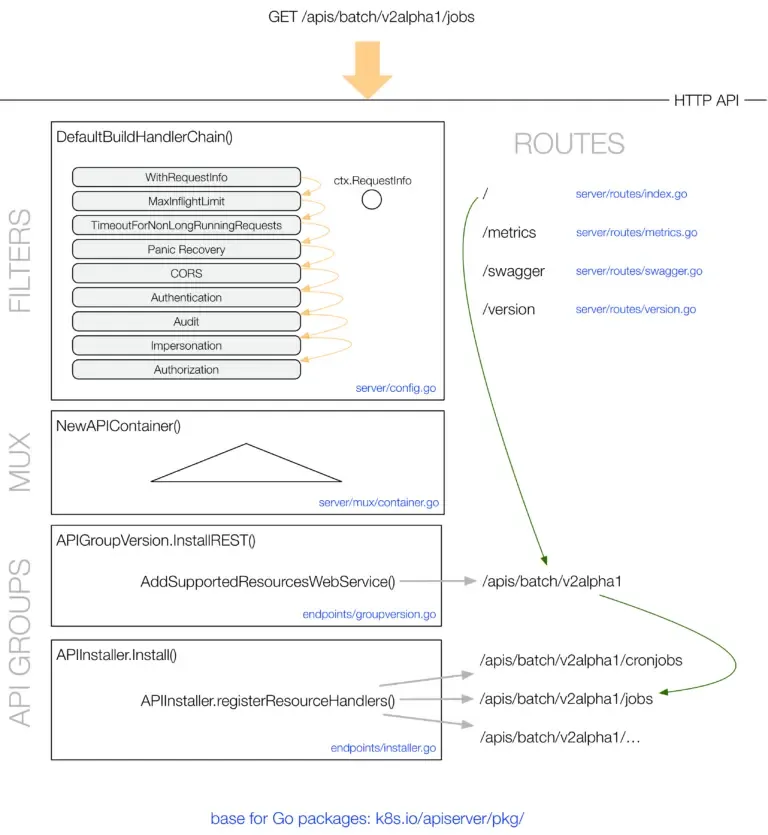
再次提醒,为简洁起见,我们省略了上图中HTTP路径的$NAMESPACE字段。
下面我们来仔细看一下定义在DefaultBuildHandlerChain()(config.go)函数中的相关filters过滤处理函数:
1.定义在requestinfo.go中的WithRequestInfo()函数主要获取HTTP请求的RequestInfo内容。
2.定义在maxinflight.go的中的WithMaxInFlightLimit()函数限制请求的in-flight数量。
3.定义在timeout.go的中的WithTimeoutForNonLongRunningRequests()函数主要定义了类似GET, PUT, POST, DELETE等non-long-running请求的超时时间。
4.定义在wrap.go 中的WithPanicRecovery()函数主要定义了当发生panic之后的相关处理。
5.定义在cors.go中的WithCORS()函数主要提供了CORS实现。CORS代表跨源资源共享,它是一种机制,允许能够处理嵌入在HTML页面中的JavaScript的XMLHttpRequests请求。
6.定义在authentication.go 中的WithAuthentication()函数主要对请求中的用户信息进行验证,并将用户信息存到相应的context中。如果认证成功,那么Authorization HTTP头将会在request请求体中移除。
7.定义在audit.go 中的WithAudit()函数主要将request的用户信息进行相关处理。然后将Request请求的源IP,用户名,用户操作及namespace等信息记入到相关审计日志中。
8.定义在impersonation.go中的WithImpersonation()函数主要处理用户模拟,通过尝试修改请求的用户(比如sudo)的方式。
9.定义在authorization.go中的WithAuthorization()函数主要请求中的用户权限就行验证,如果验证通过则发送给相应的handler进行处理,如果权限验证不通过则拒绝此次请求,返回相应错误。
本部分文章主要对API Server进行了一个总体介绍。下一部分,我们将对API资源的序列化以及如何存入到相关分布式存储中进行探究。


