掌握 NumPy 常用函数 II
斐波那契数的第 n 项
import numpy as np
phi = (1 + np.sqrt(5))/2
print("Phi", phi)
n = np.log(4 * 10 ** 6 * np.sqrt(5) + 0.5)/np.log(phi)
print(n)
n = np.arange(1, n)
print(n)
fib = (phi**n - (-1/phi)**n)/np.sqrt(5)
print("First 9 Fibonacci Numbers", fib[:9])
fib = fib.astype(int)
print("Integers", fib)
'''
Integers [ 1 1 2 3 5 8 13 21 34
... snip ... snip ...
317811 514229 832040 1346269 2178309 3524578]
'''
eventerms = fib[fib % 2 == 0]
print(eventerms)
print(eventerms.sum())
寻找质因数
from __future__ import print_function
import numpy as np
N = 600851475143
LIM = 10 ** 6
def factor(n):
a = np.ceil(np.sqrt(n))
lim = min(n, LIM)
a = np.arange(a, a + lim)
b2 = a ** 2 - n
fractions = np.modf(np.sqrt(b2))[0]
indices = np.where(fractions == 0)
a = np.ravel(np.take(a, indices))[0]
a = int(a)
b = np.sqrt(a ** 2 - n)
b = int(b)
c = a + b
d = a - b
if c == 1 or d == 1:
return
print(c, d)
factor(c)
factor(d)
factor(N)
'''
1234169 486847
1471 839
6857 71
'''
寻找回文数
# 来源:NumPy Cookbook 2e Ch3.3
# 回文数正着读还是反着读都一样
# 由两个两位数的乘积构成的最大回文数是 9009 = 91 x 99
# 寻找两个三位数乘积构成的最大回文数
# 1. 创建三位数的数组
a = np.arange(100, 1000)
np.testing.assert_equal(100, a[0]) np.testing.assert_equal(999, a[-1])
# 2. 创建两个数组中元素的乘积
# outer 计算数组的外积,也就是 a[i] x a[j] 的矩阵
# ravel 将其展开之后,就是每个元素乘积的数组了
numbers = np.outer(a, a)
numbers = np.ravel(numbers)
numbers.sort()
np.testing.assert_equal(810000, len(numbers))
np.testing.assert_equal(10000, numbers[0])
np.testing.assert_equal(998001, numbers[-1])
#3. 寻找最大的回文数
for number in numbers[::-1]:
s = str(numbers[i])
if s == s[::-1]:
print(s)
break
稳态向量
from __future__ import print_function
from matplotlib.finance import quotes_historical_yahoo
from datetime import date
import numpy as np
today = date.today()
start = (today.year - 1, today.month, today.day)
quotes = quotes_historical_yahoo('AAPL', start, today)
close = [q[4] for q in quotes]
states = np.sign(np.diff(close))
NDIM = 3
SM = np.zeros((NDIM, NDIM))
signs = [-1, 0, 1]
k = 1
for i, signi in enumerate(signs):
start_indices = np.where(states[:-1] == signi)[0]
N = len(start_indices) + k * NDIM
if N == 0:
continue
end_values = states[start_indices + 1]
for j, signj in enumerate(signs):
occurrences = len(end_values[end_values == signj])
SM[i][j] = (occurrences + k)/float(N)
print(SM)
'''
[[ 0.5047619 0.00952381 0.48571429]
[ 0.33333333 0.33333333 0.33333333]
[ 0.33774834 0.00662252 0.65562914]]
'''
eig_out = np.linalg.eig(SM)
print(eig_out)
'''
(array([ 1. , 0.16709381, 0.32663057]),
array([[ 5.77350269e-01, 7.31108409e-01, 7.90138877e-04],
[ 5.77350269e-01, -4.65117036e-01, -9.99813147e-01],
[ 5.77350269e-01, -4.99145907e-01, 1.93144030e-02]]))
'''
idx_vec = np.where(np.abs(eig_out[0] - 1) < 0.1)
print("Index eigenvalue 1", idx_vec)
x = eig_out[1][:,idx_vec].flatten()
print("Steady state vector", x)
print("Check", np.dot(SM, x))
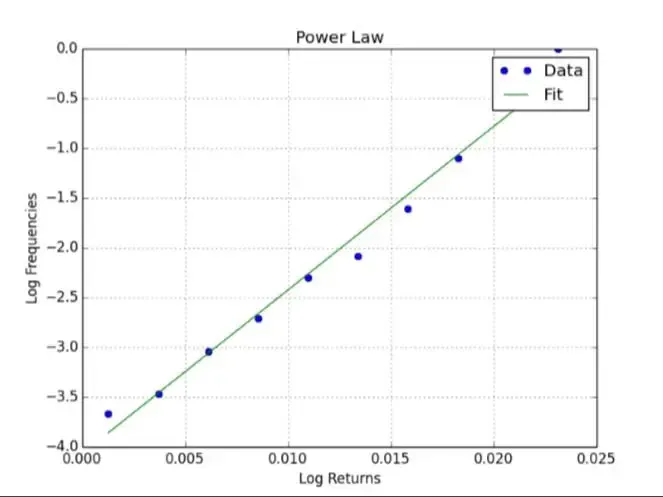
探索幂率
# 来源:NumPy Cookbook 2e Ch3.5
# 幂律就是 y = c * x ** k 的函数关系
from matplotlib.finance import quotes_historical_yahoo
from datetime import date
import numpy as np
import matplotlib.pyplot as plt
# 1. 获取收盘价
today = date.today()
start = (today.year - 1, today.month, today.day)
quotes = quotes_historical_yahoo('IBM', start, today)
close = np.array([q[4] for q in quotes])
# 2. 获取正的对数收益
logreturns = np.diff(np.log(close))
pos = logreturns[logreturns > 0]
# 3. 获取收益频率
# histogram 默认将输入数据分为 10 个组
# 返回一个元组,第一项是每个组的频数
# 第二项是每个组的范围
counts, rets = np.histogram(pos)
# 取每个组的中间值
rets = rets[:-1] + (rets[1] - rets[0])/2
# 计算频数非 0 的位置
indices0 = np.where(counts != 0)
# 过滤掉频数为 0 的数据点
counts = np.take(counts, indices0)[0]
rets = np.take(rets, indices0)[0]
# 计算对数周期
freqs = 1.0/counts
freqs = np.log(freqs)
# 4. 将周期和收益拟合为直线
p = np.polyfit(rets,freqs, 1)
# 5. 绘制结果
plt.title('Power Law')
plt.plot(rets, freqs, 'o', label='Data')
plt.plot(rets, p[0] * rets + p[1], label='Fit')
plt.xlabel('Log Returns')
plt.ylabel('Log Frequencies')
plt.legend()
plt.grid()
plt.show()
# log(T) = k * log(R) + c
# T = exp(c) * R ** k
# 满足幂率关系
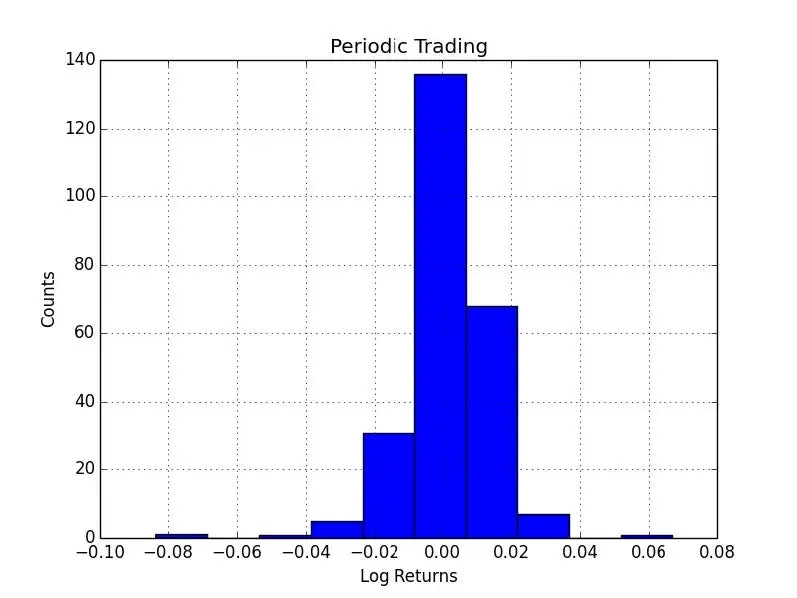
收益的分布
from __future__ import print_function
from matplotlib.finance
import quotes_historical_yahoo
from datetime import date
import numpy as np
import scipy.stats
import matplotlib.pyplot as plt
today = date.today()
start = (today.year - 1, today.month, today.day)
quotes = quotes_historical_yahoo('AAPL', start, today)
close = np.array([q[4] for q in quotes])
logreturns = np.diff(np.log(close))
freq = 0.02
breakout = scipy.stats.scoreatpercentile(logreturns, 100 * (1 - freq) )
pullback = scipy.stats.scoreatpercentile(logreturns, 100 * freq)
buys = np.compress(logreturns < pullback, close)
sells = np.compress(logreturns > breakout, close)
print(buys)
print(sells)
print(len(buys), len(sells))
print(sells.sum() - buys.sum())
plt.title('Periodic Trading')
plt.hist(logreturns)
plt.grid()
plt.xlabel('Log Returns')
plt.ylabel('Counts')
plt.show()
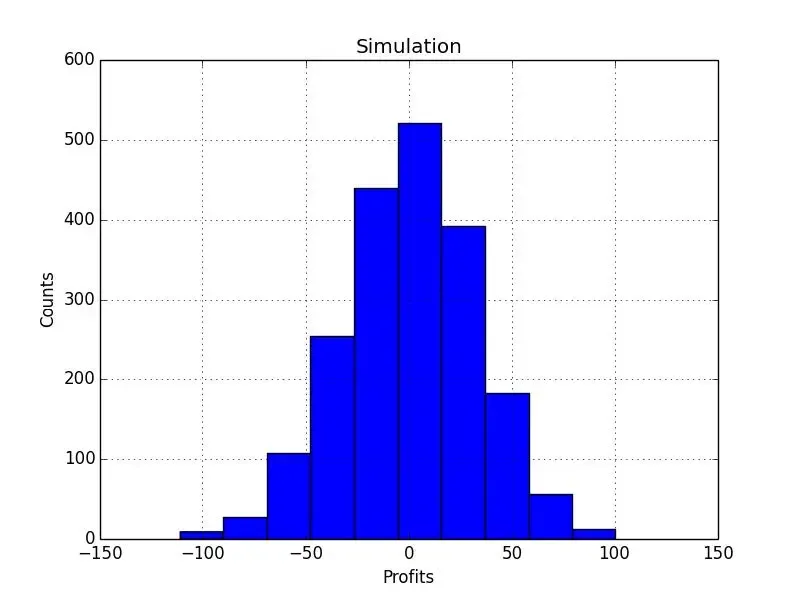
模拟随机交易
from __future__ import print_function
from matplotlib.finance import quotes_historical_yahoo
from datetime import date
import numpy as np
import matplotlib.pyplot as plt
def get_indices(high, size):
return np.random.randint(0, high, size)
today = date.today()
start = (today.year - 1, today.month, today.day)
quotes = quotes_historical_yahoo('AAPL', start, today)
close = np.array([q[4] for q in quotes])
nbuys = 5
N = 2000
profits = np.zeros(N)
for i in xrange(N):
buys = np.take(close, get_indices(len(close), nbuys))
sells = np.take(close, get_indices(len(close), nbuys))
profits[i] = sells.sum() - buys.sum()
print("Mean", profits.mean())
print("Std", profits.std())
plt.title('Simulation')
plt.hist(profits)
plt.xlabel('Profits')
plt.ylabel('Counts')
plt.grid()
plt.show()
埃拉托色尼筛选法
from __future__ import print_function
import numpy as np
LIM = 10 ** 6
N = 10 ** 9
P = 10001
primes = []
p = 2
def sieve_primes(a, p):
a = a[a % p != 0]
return a
for i in xrange(3, N, LIM):
a = np.arange(i, i + LIM, 2)
while len(primes) < P:
a = sieve_primes(a, p)
primes.append(p)
p = a[0]
print(len(primes), primes[P-1])

