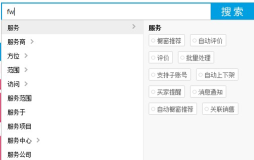
今天来说说拼音检索,这个功能其实还是用来提升用户体验的,别的不说,最起码避免了用户切换输入法,如果能支持中文汉语拼音简拼,那用户搜索时输入的字符更简便了,用户输入次数少了就是为了给用户使用时带来便利。来看看一些拼音搜索的经典案例:




看了上面几张图的功能演示,我想大家也应该知道了拼音检索的作用以及为什么要使用拼音检索了。那接下来就来说说如何实现:
首先我们我们需要把分词器分出来的中文词语转换为汉语拼音,Java中汉字转拼音可以使用pinyin4j这个类库,当然icu4j也可以,但icu4j不支持多音字且类库jar包体积有10M多,所以我选择了pinyin4j,但pinyin4j支持多音字并不是说它能根据词语自动判断汉字读音,比如:重庆,pinyin4j会返回chongqing zhongqing,最终还是需要用户去人工选择正确的拼音的。pinyin4j也支持简拼的,所以拼音转换这方面没什么问题了。
接下来要做的就是要把转换得到的拼音进行NGram处理,比如:王杰的汉语拼音是wangjie,如果要用户完整正确的输入wangjie才能搜到有关“王杰”的结果,那未免有点在考用户的汉语拼音基础知识,万一用户前鼻音和后鼻音不分怎么办,所以我们需要考虑前缀查询或模糊匹配,即用户只需要输入wan就能匹配到"王"字,这样做的目的其实还是为了减少用户操作步骤,用最少的操作步骤达到同样的目的,那必然是最讨人喜欢的。再比如“孙燕姿”汉语拼音是“sunyanzi”,如果我期望输入“yanz”也能搜到呢?这时候NGram就起作用啦,我们可以对“sunyanzi”进行NGram处理,假如NGram按2-4个长度进行切分,那得到的结果就是:su un ny
ya an nz zi sun uny nya yan anz nzi suny unya nyan yanz anzi,这样用户输入yanz就能搜到了。但NGram只适合用户输入的搜索关键字比较短的情况下,因为如果用户输入的搜索关键字全是汉字且长度为20-30个,再转换为拼音,个数又要翻个5-6倍,再进行NGram又差不多翻了个10倍甚至更多,因为我们都知道BooleanQuery最多只能链接1024个Query,所以你懂的。 分出来的Gram段会通过CharTermAttribute记录在原始Term的相同位置,跟同义词实现原理差不多。所以拼音搜索至关重要的是分词,即在分词阶段就把拼音进行NGram处理然后当作同义词存入CharTermAttribute中(这无疑也会增加索引体积,索引体积增大除了会额外多占点硬盘空间外,还会对索引重建性能以及搜索性能有所影响),搜索阶段跟普通查询没什么区别。如果你不想因为NGram后Term数量太多影响搜索性能,你可以试试EdgeNGramTokenFilter进行前缀NGram,即NGram时永远从第一个字符开始切分,比如sunyanzi,按2-8个长度进行EdgeNGramTokenFilter处理后结果就是:su sun suny sunya sunyan sunyanz sunyanzi。这样处理可以减少Term数量,但弊端就是你输入yanzi就没法搜索到了(匹配粒度变粗了,没有NGram匹配粒度精确),你懂的。
下面给出一个拼音搜索的示例程序,代码如下:

- package com.yida.framework.lucene5.pinyin;
- import java.io.IOException;
- import net.sourceforge.pinyin4j.PinyinHelper;
- import net.sourceforge.pinyin4j.format.HanyuPinyinCaseType;
- import net.sourceforge.pinyin4j.format.HanyuPinyinOutputFormat;
- import net.sourceforge.pinyin4j.format.HanyuPinyinToneType;
- import net.sourceforge.pinyin4j.format.exception.BadHanyuPinyinOutputFormatCombination;
- import org.apache.lucene.analysis.TokenFilter;
- import org.apache.lucene.analysis.TokenStream;
- import org.apache.lucene.analysis.tokenattributes.CharTermAttribute;
- /**
- * 拼音过滤器[负责将汉字转换为拼音]
- * @author Lanxiaowei
- *
- */
- public class PinyinTokenFilter extends TokenFilter {
- private final CharTermAttribute termAtt;
- /**汉语拼音输出转换器[基于Pinyin4j]*/
- private HanyuPinyinOutputFormat outputFormat;
- /**对于多音字会有多个拼音,firstChar即表示只取第一个,否则会取多个拼音*/
- private boolean firstChar;
- /**Term最小长度[小于这个最小长度的不进行拼音转换]*/
- private int minTermLength;
- private char[] curTermBuffer;
- private int curTermLength;
- private boolean outChinese;
- public PinyinTokenFilter(TokenStream input) {
- this(input, Constant.DEFAULT_FIRST_CHAR, Constant.DEFAULT_MIN_TERM_LRNGTH);
- }
- public PinyinTokenFilter(TokenStream input, boolean firstChar) {
- this(input, firstChar, Constant.DEFAULT_MIN_TERM_LRNGTH);
- }
- public PinyinTokenFilter(TokenStream input, boolean firstChar,
- int minTermLenght) {
- this(input, firstChar, minTermLenght, Constant.DEFAULT_NGRAM_CHINESE);
- }
- public PinyinTokenFilter(TokenStream input, boolean firstChar,
- int minTermLenght, boolean outChinese) {
- super(input);
- this.termAtt = ((CharTermAttribute) addAttribute(CharTermAttribute.class));
- this.outputFormat = new HanyuPinyinOutputFormat();
- this.firstChar = false;
- this.minTermLength = Constant.DEFAULT_MIN_TERM_LRNGTH;
- this.outChinese = Constant.DEFAULT_OUT_CHINESE;
- this.firstChar = firstChar;
- this.minTermLength = minTermLenght;
- if (this.minTermLength < 1) {
- this.minTermLength = 1;
- }
- this.outputFormat.setCaseType(HanyuPinyinCaseType.LOWERCASE);
- this.outputFormat.setToneType(HanyuPinyinToneType.WITHOUT_TONE);
- }
- public static boolean containsChinese(String s) {
- if ((s == null) || ("".equals(s.trim())))
- return false;
- for (int i = 0; i < s.length(); i++) {
- if (isChinese(s.charAt(i)))
- return true;
- }
- return false;
- }
- public static boolean isChinese(char a) {
- int v = a;
- return (v >= 19968) && (v <= 171941);
- }
- public final boolean incrementToken() throws IOException {
- while (true) {
- if (this.curTermBuffer == null) {
- if (!this.input.incrementToken()) {
- return false;
- }
- this.curTermBuffer = ((char[]) this.termAtt.buffer().clone());
- this.curTermLength = this.termAtt.length();
- }
- if (this.outChinese) {
- this.outChinese = false;
- this.termAtt.copyBuffer(this.curTermBuffer, 0,
- this.curTermLength);
- return true;
- }
- this.outChinese = true;
- String chinese = this.termAtt.toString();
- if (containsChinese(chinese)) {
- this.outChinese = true;
- if (chinese.length() >= this.minTermLength) {
- try {
- String chineseTerm = getPinyinString(chinese);
- this.termAtt.copyBuffer(chineseTerm.toCharArray(), 0,
- chineseTerm.length());
- } catch (BadHanyuPinyinOutputFormatCombination badHanyuPinyinOutputFormatCombination) {
- badHanyuPinyinOutputFormatCombination.printStackTrace();
- }
- this.curTermBuffer = null;
- return true;
- }
- }
- this.curTermBuffer = null;
- }
- }
- public void reset() throws IOException {
- super.reset();
- }
- private String getPinyinString(String chinese)
- throws BadHanyuPinyinOutputFormatCombination {
- String chineseTerm = null;
- if (this.firstChar) {
- StringBuilder sb = new StringBuilder();
- for (int i = 0; i < chinese.length(); i++) {
- String[] array = PinyinHelper.toHanyuPinyinStringArray(
- chinese.charAt(i), this.outputFormat);
- if ((array != null) && (array.length != 0)) {
- String s = array[0];
- char c = s.charAt(0);
- sb.append(c);
- }
- }
- chineseTerm = sb.toString();
- } else {
- chineseTerm = PinyinHelper.toHanyuPinyinString(chinese,
- this.outputFormat, "");
- }
- return chineseTerm;
- }
- }
- package com.yida.framework.lucene5.pinyin;
- import java.io.IOException;
- import org.apache.lucene.analysis.TokenFilter;
- import org.apache.lucene.analysis.TokenStream;
- import org.apache.lucene.analysis.tokenattributes.CharTermAttribute;
- import org.apache.lucene.analysis.tokenattributes.OffsetAttribute;
- /**
- * 对转换后的拼音进行NGram处理的TokenFilter
- * @author Lanxiaowei
- *
- */
- public class PinyinNGramTokenFilter extends TokenFilter {
- public static final boolean DEFAULT_NGRAM_CHINESE = false;
- private final int minGram;
- private final int maxGram;
- /**是否需要对中文进行NGram[默认为false]*/
- private final boolean nGramChinese;
- private final CharTermAttribute termAtt;
- private final OffsetAttribute offsetAtt;
- private char[] curTermBuffer;
- private int curTermLength;
- private int curGramSize;
- private int tokStart;
- public PinyinNGramTokenFilter(TokenStream input) {
- this(input, Constant.DEFAULT_MIN_GRAM, Constant.DEFAULT_MAX_GRAM, DEFAULT_NGRAM_CHINESE);
- }
- public PinyinNGramTokenFilter(TokenStream input, int maxGram) {
- this(input, Constant.DEFAULT_MIN_GRAM, maxGram, DEFAULT_NGRAM_CHINESE);
- }
- public PinyinNGramTokenFilter(TokenStream input, int minGram, int maxGram) {
- this(input, minGram, maxGram, DEFAULT_NGRAM_CHINESE);
- }
- public PinyinNGramTokenFilter(TokenStream input, int minGram, int maxGram,
- boolean nGramChinese) {
- super(input);
- this.termAtt = ((CharTermAttribute) addAttribute(CharTermAttribute.class));
- this.offsetAtt = ((OffsetAttribute) addAttribute(OffsetAttribute.class));
- if (minGram < 1) {
- throw new IllegalArgumentException(
- "minGram must be greater than zero");
- }
- if (minGram > maxGram) {
- throw new IllegalArgumentException(
- "minGram must not be greater than maxGram");
- }
- this.minGram = minGram;
- this.maxGram = maxGram;
- this.nGramChinese = nGramChinese;
- }
- public static boolean containsChinese(String s) {
- if ((s == null) || ("".equals(s.trim())))
- return false;
- for (int i = 0; i < s.length(); i++) {
- if (isChinese(s.charAt(i)))
- return true;
- }
- return false;
- }
- public static boolean isChinese(char a) {
- int v = a;
- return (v >= 19968) && (v <= 171941);
- }
- public final boolean incrementToken() throws IOException {
- while (true) {
- if (this.curTermBuffer == null) {
- if (!this.input.incrementToken()) {
- return false;
- }
- if ((!this.nGramChinese)
- && (containsChinese(this.termAtt.toString()))) {
- return true;
- }
- this.curTermBuffer = ((char[]) this.termAtt.buffer().clone());
- this.curTermLength = this.termAtt.length();
- this.curGramSize = this.minGram;
- this.tokStart = this.offsetAtt.startOffset();
- }
- if (this.curGramSize <= this.maxGram) {
- if (this.curGramSize >= this.curTermLength) {
- clearAttributes();
- this.offsetAtt.setOffset(this.tokStart + 0, this.tokStart
- + this.curTermLength);
- this.termAtt.copyBuffer(this.curTermBuffer, 0,
- this.curTermLength);
- this.curTermBuffer = null;
- return true;
- }
- int start = 0;
- int end = start + this.curGramSize;
- clearAttributes();
- this.offsetAtt.setOffset(this.tokStart + start, this.tokStart
- + end);
- this.termAtt.copyBuffer(this.curTermBuffer, start,
- this.curGramSize);
- this.curGramSize += 1;
- return true;
- }
- this.curTermBuffer = null;
- }
- }
- public void reset() throws IOException {
- super.reset();
- this.curTermBuffer = null;
- }
- }
- package com.yida.framework.lucene5.pinyin;
- import java.io.BufferedReader;
- import java.io.Reader;
- import java.io.StringReader;
- import org.apache.lucene.analysis.Analyzer;
- import org.apache.lucene.analysis.TokenStream;
- import org.apache.lucene.analysis.Tokenizer;
- import org.apache.lucene.analysis.core.LowerCaseFilter;
- import org.apache.lucene.analysis.core.StopAnalyzer;
- import org.apache.lucene.analysis.core.StopFilter;
- import org.wltea.analyzer.lucene.IKTokenizer;
- /**
- * 自定义拼音分词器
- * @author Lanxiaowei
- *
- */
- public class PinyinAnalyzer extends Analyzer {
- private int minGram;
- private int maxGram;
- private boolean useSmart;
- public PinyinAnalyzer() {
- super();
- this.maxGram = Constant.DEFAULT_MAX_GRAM;
- this.minGram = Constant.DEFAULT_MIN_GRAM;
- this.useSmart = Constant.DEFAULT_IK_USE_SMART;
- }
- public PinyinAnalyzer(boolean useSmart) {
- super();
- this.maxGram = Constant.DEFAULT_MAX_GRAM;
- this.minGram = Constant.DEFAULT_MIN_GRAM;
- this.useSmart = useSmart;
- }
- public PinyinAnalyzer(int maxGram) {
- super();
- this.maxGram = maxGram;
- this.minGram = Constant.DEFAULT_MIN_GRAM;
- this.useSmart = Constant.DEFAULT_IK_USE_SMART;
- }
- public PinyinAnalyzer(int maxGram,boolean useSmart) {
- super();
- this.maxGram = maxGram;
- this.minGram = Constant.DEFAULT_MIN_GRAM;
- this.useSmart = useSmart;
- }
- public PinyinAnalyzer(int minGram, int maxGram,boolean useSmart) {
- super();
- this.minGram = minGram;
- this.maxGram = maxGram;
- this.useSmart = useSmart;
- }
- @Override
- protected TokenStreamComponents createComponents(String fieldName) {
- Reader reader = new BufferedReader(new StringReader(fieldName));
- Tokenizer tokenizer = new IKTokenizer(reader, useSmart);
- //转拼音
- TokenStream tokenStream = new PinyinTokenFilter(tokenizer,
- Constant.DEFAULT_FIRST_CHAR, Constant.DEFAULT_MIN_TERM_LRNGTH);
- //对拼音进行NGram处理
- tokenStream = new PinyinNGramTokenFilter(tokenStream, this.minGram, this.maxGram);
- tokenStream = new LowerCaseFilter(tokenStream);
- tokenStream = new StopFilter(tokenStream,StopAnalyzer.ENGLISH_STOP_WORDS_SET);
- return new Analyzer.TokenStreamComponents(tokenizer, tokenStream);
- }
- }
- package com.yida.framework.lucene5.pinyin.test;
- import java.io.IOException;
- import org.apache.lucene.analysis.Analyzer;
- import com.yida.framework.lucene5.pinyin.PinyinAnalyzer;
- import com.yida.framework.lucene5.util.AnalyzerUtils;
- /**
- * 拼音分词器测试
- * @author Lanxiaowei
- *
- */
- public class PinyinAnalyzerTest {
- public static void main(String[] args) throws IOException {
- String text = "2011年3月31日,孙燕姿与相恋5年多的男友纳迪姆在新加坡登记结婚";
- Analyzer analyzer = new PinyinAnalyzer(20);
- AnalyzerUtils.displayTokens(analyzer, text);
- }
- }
- package com.yida.framework.lucene5.pinyin.test;
- import org.apache.lucene.analysis.Analyzer;
- import org.apache.lucene.document.Document;
- import org.apache.lucene.document.Field.Store;
- import org.apache.lucene.document.TextField;
- import org.apache.lucene.index.DirectoryReader;
- import org.apache.lucene.index.IndexReader;
- import org.apache.lucene.index.IndexWriter;
- import org.apache.lucene.index.IndexWriterConfig;
- import org.apache.lucene.index.Term;
- import org.apache.lucene.search.IndexSearcher;
- import org.apache.lucene.search.Query;
- import org.apache.lucene.search.ScoreDoc;
- import org.apache.lucene.search.TermQuery;
- import org.apache.lucene.search.TopDocs;
- import org.apache.lucene.store.Directory;
- import org.apache.lucene.store.RAMDirectory;
- import com.yida.framework.lucene5.pinyin.PinyinAnalyzer;
- /**
- * 拼音搜索测试
- * @author Lanxiaowei
- *
- */
- public class PinyinSearchTest {
- public static void main(String[] args) throws Exception {
- String fieldName = "content";
- String queryString = "sunyanzi";
- Directory directory = new RAMDirectory();
- Analyzer analyzer = new PinyinAnalyzer();
- IndexWriterConfig config = new IndexWriterConfig(analyzer);
- IndexWriter writer = new IndexWriter(directory, config);
- /****************创建测试索引begin********************/
- Document doc1 = new Document();
- doc1.add(new TextField(fieldName, "孙燕姿,新加坡籍华语流行音乐女歌手,刚出道便被誉为华语“四小天后”之一。", Store.YES));
- writer.addDocument(doc1);
- Document doc2 = new Document();
- doc2.add(new TextField(fieldName, "1978年7月23日,孙燕姿出生于新加坡,祖籍中国广东省潮州市,父亲孙耀宏是新加坡南洋理工大学电机系教授,母亲是一名教师。姐姐孙燕嘉比燕姿大三岁,任职新加坡巴克莱投资银行副总裁,妹妹孙燕美小六岁,是新加坡国立大学医学硕士,燕姿作为家中的第二个女儿,次+女=姿,故取名“燕姿”", Store.YES));
- writer.addDocument(doc2);
- Document doc3 = new Document();
- doc3.add(new TextField(fieldName, "孙燕姿毕业于新加坡南洋理工大学,父亲是燕姿音乐的启蒙者,燕姿从小热爱音乐,五岁开始学钢琴,十岁第一次在舞台上唱歌,十八岁写下第一首自己作词作曲的歌《Someone》。", Store.YES));
- writer.addDocument(doc3);
- Document doc4 = new Document();
- doc4.add(new TextField(fieldName, "华纳音乐于2000年6月9日推出孙燕姿的首张音乐专辑《孙燕姿同名专辑》,孙燕姿由此开始了她的音乐之旅。", Store.YES));
- writer.addDocument(doc4);
- Document doc5 = new Document();
- doc5.add(new TextField(fieldName, "2000年,孙燕姿的首张专辑《孙燕姿同名专辑》获得台湾地区年度专辑销售冠军,在台湾卖出30余万张的好成绩,同年底,发行第二张专辑《我要的幸福》", Store.YES));
- writer.addDocument(doc5);
- Document doc6 = new Document();
- doc6.add(new TextField(fieldName, "2011年3月31日,孙燕姿与相恋5年多的男友纳迪姆在新加坡登记结婚", Store.YES));
- writer.addDocument(doc6);
- //强制合并为1个段
- writer.forceMerge(1);
- writer.close();
- /****************创建测试索引end********************/
- IndexReader reader = DirectoryReader.open(directory);
- IndexSearcher searcher = new IndexSearcher(reader);
- Query query = new TermQuery(new Term(fieldName,queryString));
- TopDocs topDocs = searcher.search(query,Integer.MAX_VALUE);
- ScoreDoc[] docs = topDocs.scoreDocs;
- if(null == docs || docs.length <= 0) {
- System.out.println("No results.");
- return;
- }
- //打印查询结果
- System.out.println("ID[Score]\tcontent");
- for (ScoreDoc scoreDoc : docs) {
- int docID = scoreDoc.doc;
- Document document = searcher.doc(docID);
- String content = document.get(fieldName);
- float score = scoreDoc.score;
- System.out.println(docID + "[" + score + "]\t" + content);
- }
- }
- }
我只贴出了比较核心的几个类,至于关联的其他类,请你们下载底下的附件再详细的看吧。拼音搜索就说这么多了,如果你还有什么问题,请QQ上联系我(QQ:7-3-6-0-3-1-3-0-5),或者加我的Java技术群跟我们一起交流学习,我会非常的欢迎的。群号:

转载:http://iamyida.iteye.com/blog/2207080