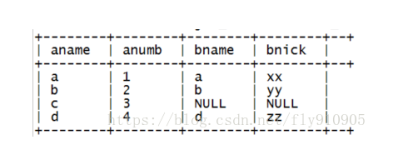
hive0.11之前,默认的join方式是reduce端join,即shuffle join(hive.auto.convert.join默认为false),其原理是map的输出数据通过hash进行partition,然后shuffle至对应的reduce端,执行join.如果join key分布不均匀,则会造成一定的数据倾斜,比较明显的现象就是某一个reduce会一直运行在99%,在join运行完毕后,可以通过job的counter看到,reduce处理的数据量相差很大。
join中还有一个方式是map join,即在map 端进行join,其原理是broadcast join,即把小表作为一个完整的驱动表来进行join操作。这种方式比较适合表中有一个小表的情况(比如过比较大,可能会出现oom的情况),hive是rbo的方法来执行操作的,所以需要把小表放在前面,不过也可以手动指定hint,比如/*+ mapjoin(a)*/。
hive 0.11之后,在表的大小符合设置时(hive.auto.convert.join.noconditionaltask=true ,hive.auto.convert.join.noconditionaltask.size=10000,hive.mapjoin.smalltable.filesize=25000000),默认会把join转换为map join(认 hive.ignore.mapjoin.hint为true,hive.auto.convert.join为true),不过hive0.11的map join bug比较多,可以通过在默认关闭map join convert,在需要时再设置hint:
hive.auto.convert.join=false
hive.auto.convert.join=false
hive.ignore.mapjoin.hint=false.
还有另外的一些join方式,以后再说。。。
本文转自菜菜光 51CTO博客,原文链接:http://blog.51cto.com/caiguangguang/1376183,如需转载请自行联系原作者