1. Introduction to Speech Synthesis Technology
1.1 What is Speech Synthesis?
Speech synthesis technology enables text-to-speech conversion. It is an indispensable module for human-to-computer interaction. Speech recognition technology enables computers to "listen" to human speech and convert speech signals to words. Speech conversion technology enables computer programs to "speak" the words we input and convert them to speech output.

1.2 Application Scenarios and Research Scope of Speech Synthesis Technology
Speech synthesis technology is an indispensable module for human-to-computer interaction. It is widely used in various scenarios, from map navigation apps (such as AutoNavi's voice navigation featuring Gao Xiaosong), voice assistants (Siri, Google Assistant, Cortana), novels and news readers (Shuqi.com, Baidu Novels), smart speakers (Alexa, Tmall Genie), real-time voice interpretation, to different kinds of customer services and call centers, and even airport, subway, and bus announcements.
Apart from text-to-speech conversion, speech synthesis technology includes, without limitation: conversion of speakers (as in James Bond movies), expansion of speech bandwidth (e.g., Hatsune Miku, a Japanese pop star), whisper synthesis, dialect synthesis (dialects in Sichuan and Guangdong Provinces, articulation of ancient Chinese language), animal sound synthesis, etc.

1.3 A Typical Speech Synthesis System Flow-process Diagram
As shown in the diagram below, a typical speech synthesis system consists of two components: front-end and back-end.
The front-end component focuses on analysis of text input and extraction of information necessary for back-end modelling. This includes word breaking (judgment on word boundary), parts of speech (e.g., noun, verb, adjective) annotation, projection of rhythmic structure (whether it's a metrical phrase boundary), and disambiguation of polyphones.
The back-end component reads the front-end analysis results and combines the speech and text information for modelling. During the process of synthesis, the back end generates the output of speech signals using the text input and well-trained acoustic models.

1.4 Speech Production Process
When a human speaks, the pulmonary airflow going along the vocal cords is modulated with the shape of oral cavity and produced through lips. When a human speaks softly, the pulmonary airflow going along does not cause the vocal cords to vibrate, which is indicated as white noise signal. Conversely, when a human makes vowel and voiced consonant sounds, the vocal cords vibrate rhythmically, which is indicated as an impulse train. The frequency of vocal cord vibration is referred to as fundamental frequency (f0). The tone and sound of human speech depends on the shape of oral cavity. Put simply, the production of human speech is a process whereby a pumping signal (airflow) is modulated with a filter (shape of oral cavity) and emitted through the lips.

1.5 Three Kinds of Existing Speech Synthesis Systems
Existing speech synthesis systems are classified into three types based on the different methods and frameworks adopted:
- Parametric speech synthesis system
- Splicing speech synthesis system
- Waveform-based statistical speech synthesis system (WaveNet)
Currently, the first two are mainstream systems used by big companies, while the WaveNet method is the hottest area of the research at present. Let’s look at each of these systems in detail:
Parametric Speech Synthesis System
During the analysis stage of a parametric speech synthesis system, speech waves are converted into vocal or rhythmic parameters, such as frequency spectrum, fundamental frequency, and duration, using vocoder in accordance with the speech production characteristics. During the modelling stage, models are built for vocal parameters. During the speech synthesis stage, the speech signals in time domain are recovered from the projected vocal parameters using vocoder.
The advantage of a parametric speech synthesis system lies in smaller size of models, ease of adjustment on model parameters (conversion of speakers, rising or falling tone), and stability of speech synthesis. The shortcoming lies in the fact that there is a certain loss in the acoustic fidelity compared to the original recording after the parameterization of synthesized speech.
Splicing Speech Synthesis System
In this system, the original recording is not parameterized, but cut into and stored as basic units. During the synthesis process, the target cost and splicing cost of each unit are calculated using certain algorithms or models, and finally the synthesized speech is "spliced" using Viterbi algorithm and signal processing methods such as PSOLA (Pitch Synchronized Overlap-Add) and WSOLA (Waveform Similarity based Overlap-Add).
The advantage of splicing speech synthesis lies in the acoustic quality, without loss in the quality resulting from parameterization of speech units. For databases that are small and lack suitable speech units, glitches may exist in the synthesized speech or rhythm or sound may not be stable enough. Therefore a greater storage is required.
Waveform-based statistical speech synthesis system (WaveNet)
WaveNet was first introduced by Deep Mind, with Dilated CNN (dilated convolutional neural network) as the primary unit. Under this method, speech signals are not parameterized, while the neural network is used to predict each sampling point in time domain for synthesis of speech waveforms. The advantage lies in better acoustic fidelity than the parametric synthesis system, but the quality is slightly lower than that of splicing synthesis. However, it is more stable than the splicing synthesis system. The shortcoming lies in the fact that a greater calculation capacity is required and the synthesis process is slower as it requires projection of each sampling point. It has been proven that WaveNet can predict speech signals in time domain, which was previously not possible. At present, WaveNet is the hottest area of research.
1.6 Assessment Criteria for Speech Synthesis
Because tone quality is relatively subjective, a good or bad speech synthesis is assessed by many hearing testing staff using the MOS (Mean Opinion Score) method. The range of MOS is 1-5 points, of which 1: Bad, 2: Poor, 3: Fair, 4: Good, 5: Excellent. MOS is used to assess the acoustic quality, intelligibility, similarity, and other features of speech synthesis as well as the holistic naturalness of speech.
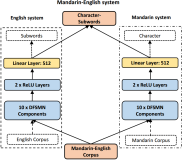
2. Introduction to Dissertations Regarding Speech Synthesis
The following is an introduction to the dissertations regarding speech synthesis presented during Interspeech 2017. There was a special session for discussion of various WaveNet applications in the event. During the conference, many big companies presented articles introducing their online speech synthesis systems, such as Siri, and this was the first time Apple presented the structure of its Siri system.
2.1 WaveNet and Novel Paradigms
This section is about what Wavenet can do. The introduction focuses on the following dissertations:

2.1.1 PAPER Tue-O-4-1-1 — Speaker-Dependent WaveNet Vocoder
This article, presented by Nagoya University of Japan, uses WaveNet as vocoder which is different from basic WaveNet, and is not conditioned on the linguistic feature but on the acoustic feature of each frame (acoustic parameters such as fundamental frequency and fundamental frequency). The speech synthesis is achieved using the acoustic feature defined for each frame and WaveNet, but without any traditional vocoder. The experiments have proven that WaveNet vocoder is better than traditional MLSA (Mel-Log S) vocoder for different sets of speakers.
However, the author also mentioned that the training and projection of WaveNet is a very slow process using single GPU TITAN X, during which, training for each speaker takes 2 days and synthesis of 3-second speech takes 6 minutes.



2.1.2 PAPER Tue-O-4-1-2 — Waveform Modeling Using Stacked Dilated Convolutional Neural Networks for Speech Bandwidth Extension
This article, presented by iFLYTEK Laboratory, aims to use WaveNet structure for prediction of broad-bandwidth speech signals from narrow-bandwidth ones. Different from basic WaveNet, this method changes the auto-regressive production into direct mapping method, and compares the non-casual CNN with casual CNN. The article concludes that the best results can be achieved by predicting only high-frequency signals at first and then combining them with low-frequency signals to produce broad-bandwidth ones.



2.1.3 PAPER Tue-O-4-1-5 — Statistical Voice Conversion with WaveNet-Based Waveform Generation
This article, also presented by Nagoya University of Japan, uses WaveNet structure to achieve human speech conversion (Voice Conversion), and concludes that it is better than the traditional GMM-based method. As a matter of fact, this article also uses WaveNet as a vocoder, and during the process of synthesis, uses the speech parameters converted as the condition for the production of speech wave. The following diagram shows the structure of WaveNet-based voice conversion.

2.2 Articles Introducing Synthesis Systems of Big Companies
2.2.1 Apple: Siri On-Device Deep Learning-Guided Unit Selection Text-to-Speech System
As the first article introducing Siri, it focuses on the progress Apple has made with respect to deep learning of TTS and how its TTS has improved. From the perspective of experimental results, the splicing speech synthesis system based on mix density network (MDN) is obviously better than the previous traditional Siri splicing synthesis systems for various language categories. Specific results are as follows:


2.2.2 Google's Next-Generation Real-Time Unit-Selection Synthesizer using Sequence-To-Sequence LSTM-based Auto-encoders

2.2.3 Nuance: Unit Selection with Hierarchical Cascaded Long Short Term Memory Bidirectional Recurrent Neural Nets
Nuance Communications also presented an article introducing its synthesis system, a splicing synthesis system based on Hierarchical LSTM. The results show that a hierarchical LSTM structure is better than any non-hierarchical LSTM structure with respect to the rhythm of synthesized speech.


2.2.4 Google: Tacotron: Towards End-to-End Speech Synthesis
This article was previously published on arXiv. Different from WaveNet, Tacotron system builds models and makes projections by frame instead of sample point, and therefore runs faster. Tacotron builds models on spectrograms, while WaveNet builds models based on waveforms. Therefore, compared with WaveNet, Tacotron loses information on phase position in the frame. Tacotron recovers waves directly from Spectrogram using Griffin-Lim algorithm.
Under the acoustic model, Tacotron further defines the nonlinear code for each embedding word using Pre-net and improves the robustness of the model using CBHG structure. During the modelling process, the author uses attention mechanism to control the condition of each frame. With this model, the input of the current frame is obtained from the feed-in of the output of the last frame.