
一 背景:
不同于web search,在电商搜索中,个性化起着更为重要的作用。这是因为一个用户来到淘宝、淘宝搜索,并不是在找一个确定的信息或者答案,而是在‘逛街’。因此从海量的不同风格、品牌、颜色的商品中,让用户看到他更想看到的,会极大的提升用户的购物体验。
近年,大量的文献都在研究在推荐、搜索、广告中的推荐方法,并成功的应用到了很多实际场景中。绝大多数的的推荐算法都是使用的矩阵分解(matrix factorization)以及近邻算法(neighborhood methods)。而更近期,深度学习(DNN)和递归神经网络(RNN)也被引入以提升推荐效率。这些工作中,用户一般被表示成他有过行为的商品集合(或序列)以及画像信息,目标则是各类准确率,例如RMSE、AUC。
不同于以往的工作,我们这篇文章更专注的是用户的理解与表达,目标是产出一个通用的、鲁棒的用户表达,以提升我们模型中任务的效果,并希望能辅助提升模型外任务的效果。简单来说,我们使用一个向量去从复杂用户的行为中抽取有效信息,该向量被多个任务共享并共同学习。同时这样的一个向量在淘宝这样的大型电商平台中是非常重要的,因为在非常多的个性化场景中和个性化算法中(各种搜索,推荐,广告;Personalized LETOR,RL,Contextual MAB),都需要一个好的用户表达。一个号的用户表达能有多种好处:1)我们不再需要为每个场景都去建立一个复杂的模型,时间和计算成本都很高;而是可以时间简洁高效的模型;2)对比直接使用用户序列和模型画像,各个模型的效果都能提升;3)在线流程能更快,同时节省计算资源。我们的工作更像是使用CNN去抽图像特征,从ImagrNet上抽取到的特征,往往可以用到非常多的其他场景;也会比较类似于Deep Mind的elastic weight consolidation工作,希望训练一个通用的玩游戏的智能。
主要参考文献,是使用DNN、RNN的推荐工作,以及Multi-task Representation Learning的工作。我们算法的名字叫做Deep User Perception Network(DUPN)。
二 系统总览:

在我们的搜索引擎中,排序策略并不只是依赖商品与当前query的相关程度,用户信息和商品质量也会起到很大影响。如图所示,用户信息会分层次的从三方面影响最终的排序。首先,我们会根据用户的行为去预测用户的一些隐藏信息,例如用户的购买力、偏好店铺和品牌等。然后预测出的信息和原始用户行为一起,会帮助预估一些排序中使用的个性化feature,例如CTR预估,价格匹配分等等。最后,各种商品的排序feature会通过个性化的learning to rank(LETOR)方法融合,决定最终的排序。部分的排序feature,可以见下表。
| 特征类别 | 特证名 | 特征描述 |
| 个性化特征 | 个性化 CTR预估 |
使用logistic regression预估商品的点击率,使用用户,商品,以及他们组的特征。 |
| 价格偏好 | 如果商品价格越贴近用户购买力,分数越高;反之越低。 | |
| 商品特征 | 销量分 | 商品的销量。 |
| 售后分 | 综合反映商品的售后情况,包括用户评价,打分等。 |
三 模型结构:
下图展示了DUPN网络的整体结构。模型的输入是用户的点击序列,每次点击是一个商品,对应到多个稀疏ID,每个ID会映射到一个稠密的向量上;然后我们使用LSTM和attention-base pooling将向量序列编码到一个用户表达上。LSTM帮助建模用户的行为序列,而attention网络帮助从行为中辨别有效信息和无效信息。用户的表达向量会被多个任务共享并共同学习,以希望该向量能保留尽量多的用户有用信息。我们下面将以此讨论网络的各个部分。
1)Input Layer & Item Embedding Layer
每条样本的输入是一个用户的行为序列,x={x1,x2,…,xN},其中xi表示用户点击的第i个商品。每个xi本身是一个稀疏ID的集合,包括item id,shop,brand,category和tags,其中tags可以是0个或者多个商品的标签,其他都是单个ID。每种稀疏ID都会embedding成一个稠密向量,然后多种ID的稠密向量拼接成一个商品的表达向量。
不同的ID特征从不同规模上刻画了一个商品。shop,brand属于比较泛华的特征,描述了商品的一般特征;而商品ID属于非常个性化的特征,描述了商品的独特性。那么对于热门商品,商品的ID特征往往会体现出重要作用;而对于新上架商品或者冷门的商品,他的店铺和品牌会起到更重要的价值。
输入层和embedding层的结构如下图所示。在我们的网络中,各种ID都会被hash到一定的范围中。商品ID的hash范围是1G,embedding大小是16维的浮点数;品牌ID的hash范围是1M,embedding大小事12维浮点数;店铺ID,类目和tag标签对应的hash范围分别是100M、1M和100K,对应的维度分别是12、8和8。总体下来,一个商品会得到一个56维的向量,我们将xi对应的embedding结果记为ei。

2)RNN & Attention Based Pooling
当用户在平台上成交一个商品的时候,总会存在一个明显的浏览和点击序列,序列中的商品会比较相似或者相关。因此我们可以看到用户的行为时有比较强的规律性的,这也让使用用户的行为序列去预测用户的未来行为变得可能。考虑到用户在淘宝上行为天然的序列性,我们使用RNN对用户的行为序列进行建模,即将{e1,e2,…,eN}作为输入导入到LSTM中,得到输出是{h1,h2,…,hN},其中N表示的是用户行为的长度。
接下来最直接方法是使用LSTM的最后一个输出hN作为用户表达,理论上hN可以抽取序列中所有我们需要的信息。然而这样会导致长依赖的问题——最后一个状态需要被迫记下很久以前的信息,但是在搜索场景下,并不是用户的全部行为都是需要被记住的。对于不同的用户,在不同的query下,被记住的内容是不同的。例如一个用户在搜‘连衣裙’时,他行为序列中服饰相关的内容是需要被关注的;而当用户搜索‘iphone’时,我们更应该关注他行为中的数码产品。因此我们设计了如图所示的attention机制,attention网络会为每一个商品的hN学习一个对应的权重,该对应的权重会由商品本身hN,当前的query以及user共同决定;多个attention的权重会通过一个softmax层进行归一。
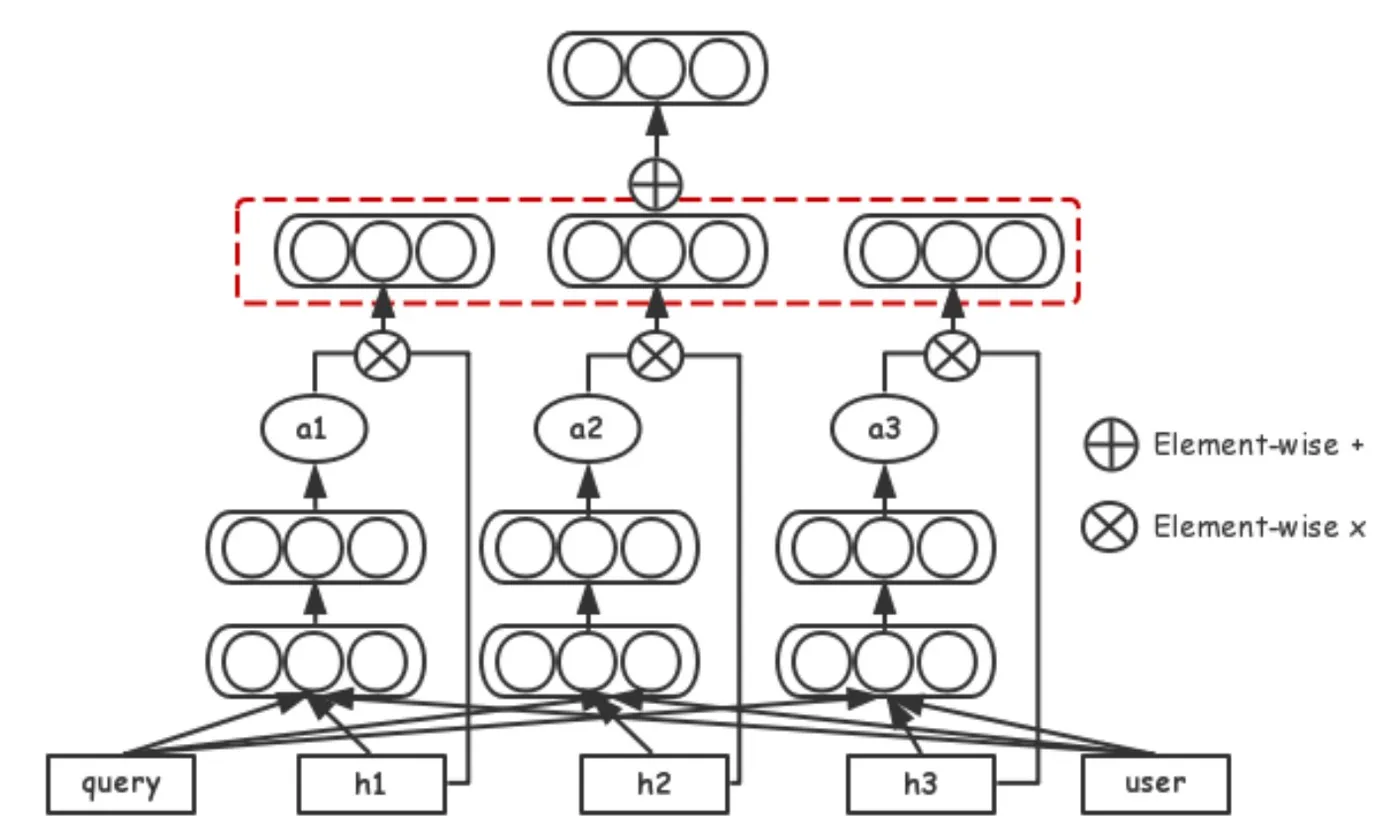
通过attention机制,网络能自动的区分用户序列中商品的重要性,着重关注当前query下相关的商品,丢弃掉无用的点击。最终得到的用户表达,我们记为u。
3)多目标学习
我们工作最关注的部分是学习得到一个基础的、通用的用户表达(而不是某一个任务专用的)。因此,在经过embedding层,RNN层以及attention网络层之后,用户的representation会被多个任务共享并共同学习。这里我们选了3个相关的,在搜索中处于不同层次的任务作为学习的目标,分别是:a,用户的购买力预估;b,用户-商品的CTR预估;c,基于商品全部特征的learning to rank(LETOR)。下面我们会更详细的的介绍3个目标。
a,CTR预估
CTR预估任务是预测每个商品的点击率,输入是用户向量u,以及商品的embedding(ei),经过一个2个隐层的浅层神经网络,使用的loss函数是Cross Entropy With Logits。
b,LETOR
LEarning TO Rank任务是与CTR任务的目标是非常类似的,主要的不同在于,商品的特征不再是商品的embedding本身,而是更多的商品特征。CTR任务学习得到的是一个商品的feature,而LETOR任务则是基于这个feature以及更多的其他feature,做一个stacking,得到商品的最终排序分。CTR任务一般是point-wise的,关注当个商品;而LETOR则可以是point-wise,pair-wise或者page-wise,关注的是最终ranking的序关系。为了简单,我们这里仍然使用point-wise的LETOR。
在LETOR任务中,u会单独经过一个2层的神经网络,得到一组ranking 的权重w,w与商品的feature(f)点乘,得到最终的ranking分数,我们注意到,最终的ranking仍然是线性的,是为了方便排序的解释性与可分析。
c,购买力预估
购买力预估,实际是预测用户会点击、成交的商品的价格范围,一直以来都是个性化中最重要的特征之一。在我们的任务中,我们将用户的购买力分成了7档,分别用p1到p7表示,p1表示最低的购买力,p7表示购买力最高,因此任务变成了一个7分类的问题。该任务的目标与商品无关,只与用户的表达u相关,因此输入是u,输出是一个softmax后的分类。
四 实验设置:
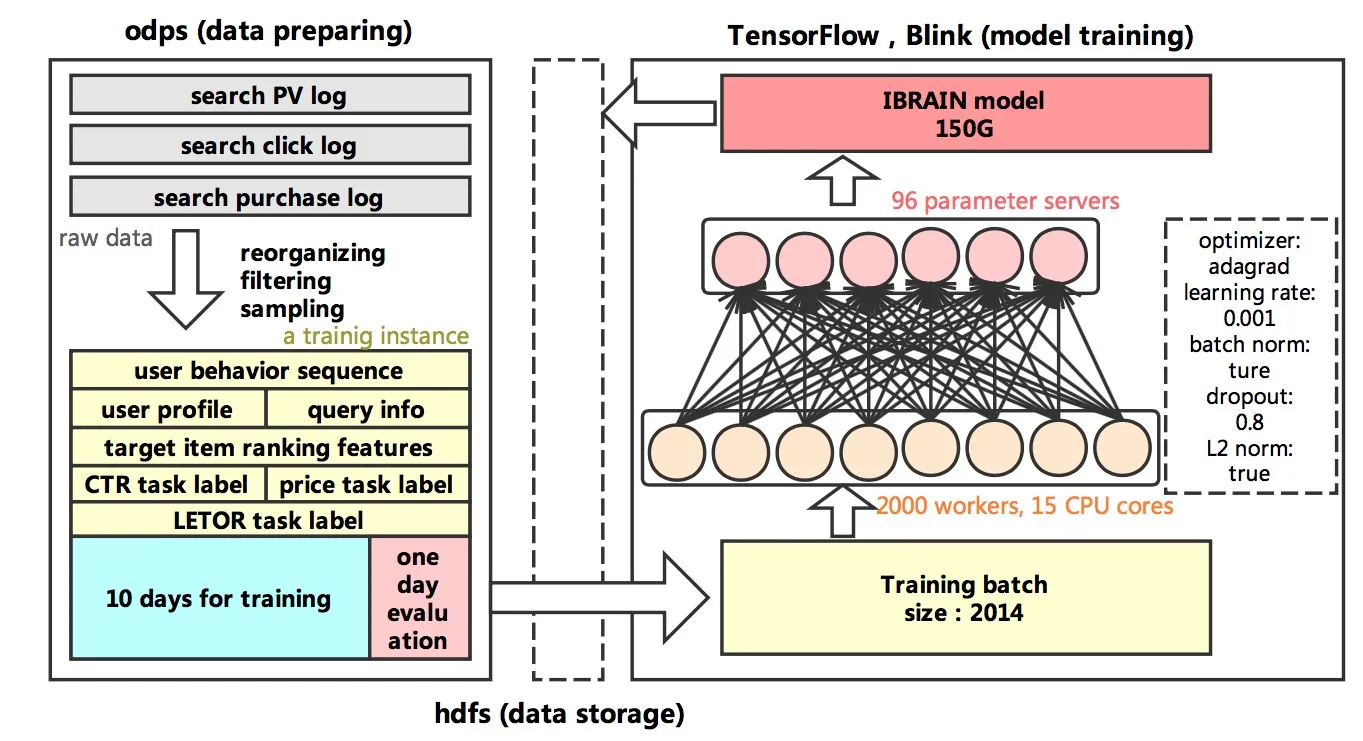
为了验证DUPN算法的性能,以及学习得到的用户representation的作用,我们产出一个基于搜索日志的数据集。同时这一小节会给出我们实验室的一些参数设置。
1)数据集说明:
数据集主要来源是搜索上的PV、点击以及成交日志。每条样本记录的是一次搜索PV下的用户名,query,展示商品列表以及有行为(点击或成交)的商品。在CTR和LETOR的任务中,一个正样本表示用户在商品上有点击或成交,否则是负样本。对于CTR和LETOR的正样本,商品会有一个额外的label从1到7,表示行为商品的价格档。同时为了LETOR任务,我们会记录每个PV下,所有商品的排序特征分。
每一天,我们的样本量大致是60亿,训练使用10天的样本,下一天的样本用作测试集。在训练中,我们会将集合分为小的batch,每个batch的样本为1024个。
2)实验设置:
网络学习过程中,我们的超参数设置如下。所有的网络 参数都是以0为均值1位方差做随机初始化;所有的全连接层都是使用dropout,dropout rate设置为0.8;同时我们加了L2正则项;模型的optimizer是Adagrad,以保证不同稀疏度参数的学习,learning rate是0.001。每条样本,在训练中过2轮。
我们使用一个大型的分布式TensorFlow进行模型的训练,基于TF1.2版本,同时工程同学做了很多优化。系统中有2000个worker,每个worker15核,进行纯CPU计算;使用了96个parameter server保存并更新模型。模型的训练速度大约是每秒400个batch,整个训练过程大约是4天。
五 实验结果及分析:
1)不同的序列建模方式对比(DNN/CNN/RNN)
在用户序列的每个商品都embedding好之后,我们可以使用多种不同的网络结构将多个embedding编码到一个用户表达中,这里我们比较了DNN、CNN以及RNN的效果。对于CTR以及LETOR任务,我们使用AUC作为评价指标,对于价格档预估,我们则使用准确率。
| LETOR | CTR | Price Precision | |
| DNN | 0.71991 | 0.69266 | 36.404% |
| CNN | 0.70557 | 0.67643 | 35.461% |
| LSTM | 0.70569 | 0.67542 | 35.940% |
| Pretrain-DUPN | 0.73091 | 0.70127 | 38.079% |
| E2E-DUPN | 0.75005 | 0.72519 | 44.011% |
表2记录了不同算法在不同任务上的实验结果。前4行的算法中,我们没有end-to-end的去训练每个ID的embedding,而是使用word2vec做了一个pre training。最后E2E-DUPN才对整个网络进行end-to-end的学习。从前3行的算法对比,我们可以看到CNN的RNN的效果反而不如直接使用DNN,这主要是因为RNN和CNN在学习的时候pool都没考虑不同商品的重要性不同,使用max pooling或者average pooling都没看到很好的效果;而DNN直接使用全连接,反而可以把握这种区别,因此效果看起来会更好一些。然后我们在RNN(LSTM)上加上query attention机制后,各个任务的指标都有较大的提升,由此可以看到使用用户序列在做预估的时候,一定要对序列中的商品给以不同的注意力。最后一行中,我们进一步的使用了end-to-end training,这样的训练速度会慢很多,同时参数的个数会上升到百亿级别,对样本量也有了跟高的要求。但是它同时带来的,则是各个任务上指标的大幅提升,尤其是购买力预估的任务,准确率达到了44%。
2)单目标对比多目标
我们的DUPN模型中,3个任务可以单独的学习,也可以同时学习。本小节主要是阐明多目标学习与单目标相比的不同与优势。在下图中,我们给出了3个任务在独自学习和共同学习上的效果对比,所有数据都是基于测试集上的。
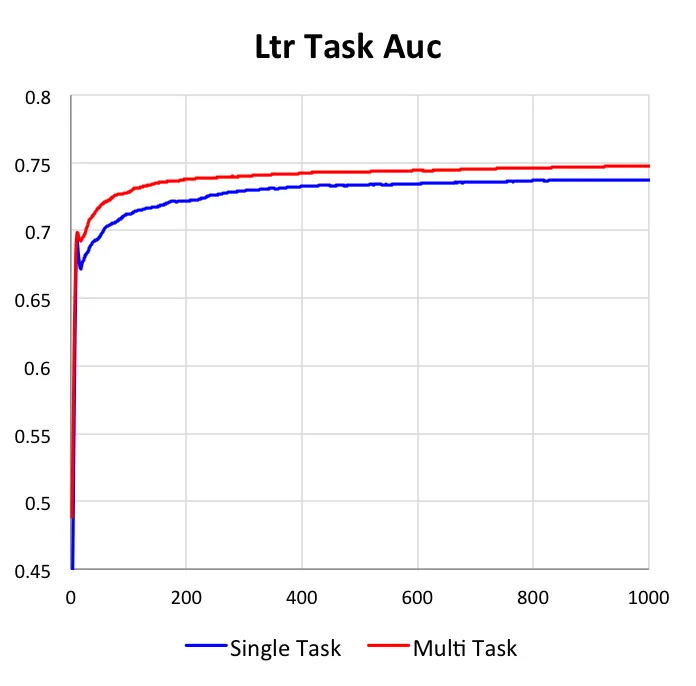
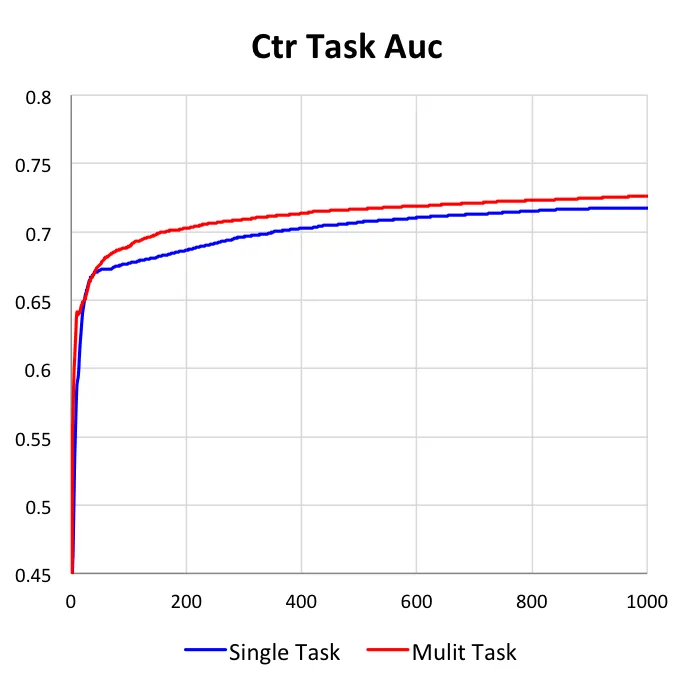
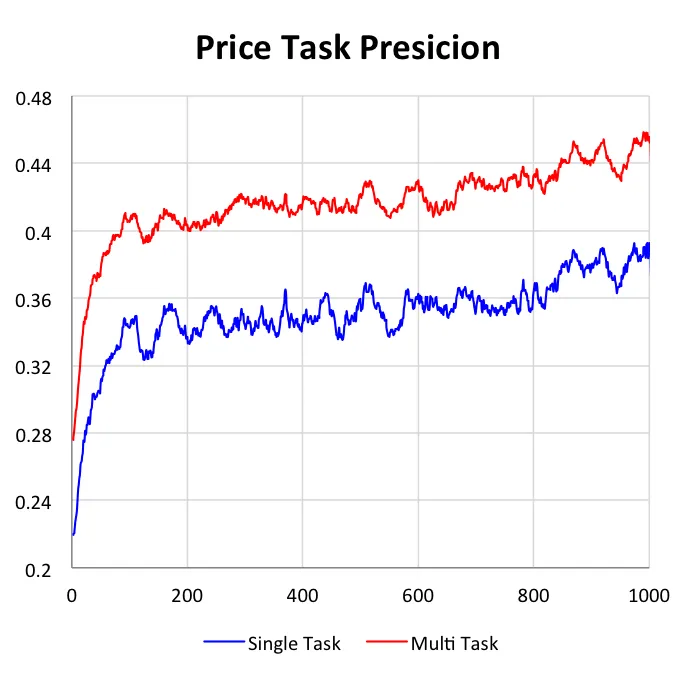
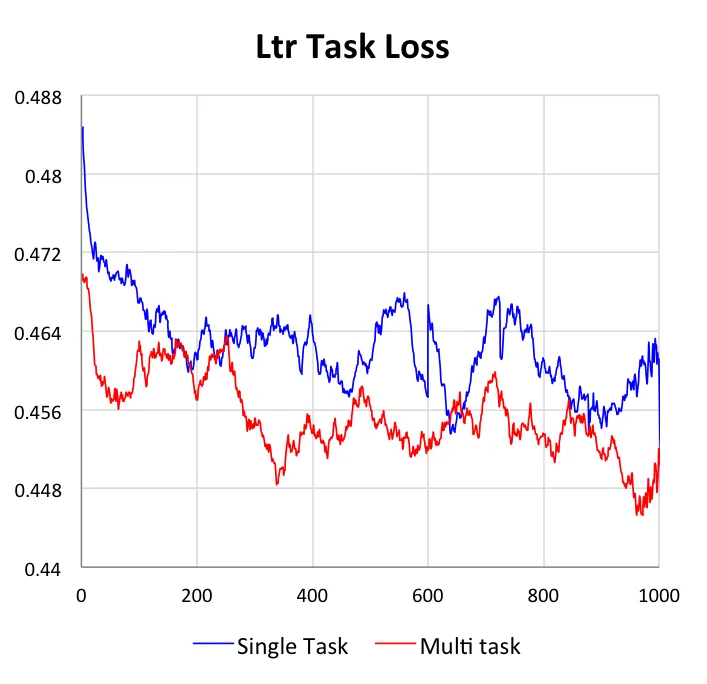
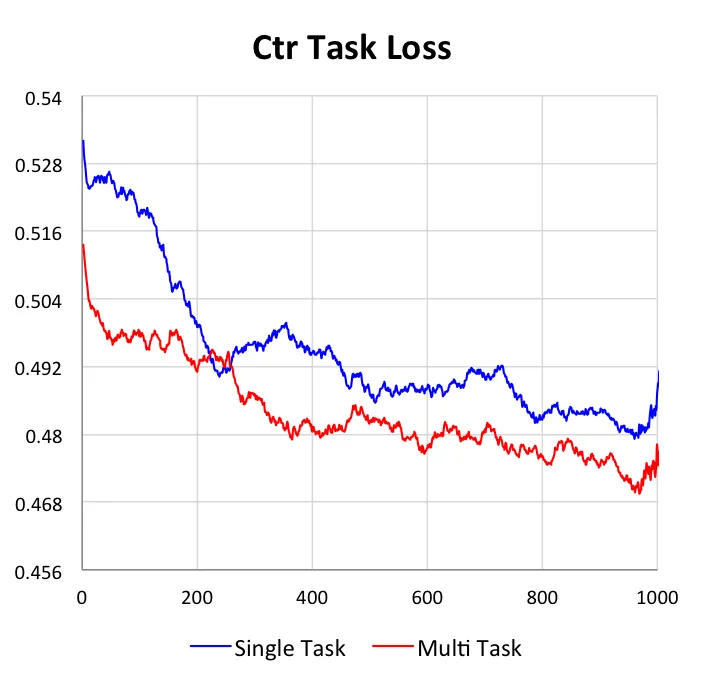
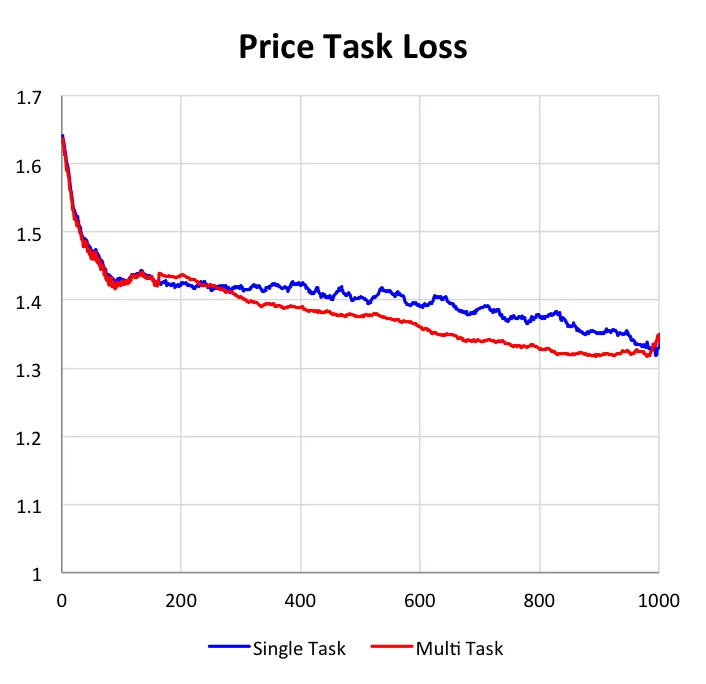
第二点,更重要的是我们可以看到多目标学习的效果均优于单目标学习。对于CTR任务和LETOR任务,AUC能提升1%,而对于价格档预估任务,准确率能提升4%。我们认为带来这种提升主要是因为在多任务学习中,目标之间可以互为正则,因此可以学到更加鲁棒的网络结构;同时因为目标之前是有关联的,因此其他目标中的信息是可以通过梯度更新影响当前目标,将有用的信息传递给当前任务。
3)表达迁移
这一节中,我们主要研究的是学习得到的用户表达是不是一个通用、基础的表达,为了验证这一点,我们研究学习得到表达的迁移能力——是否能直接应用到其他相关任务上。为了对比,我们引入了3中不同的方法,选用的任务是预估用户的店铺偏好。
a)新任务完全重新学习(RRI)。使用完全一样的DUPN网络结构和参数,重新学习新任务。
b)直接使用用户表达(RT),学习一个非常浅层的DNN模型。
c)在之前模型的基础上做fine-tuning(FT)。
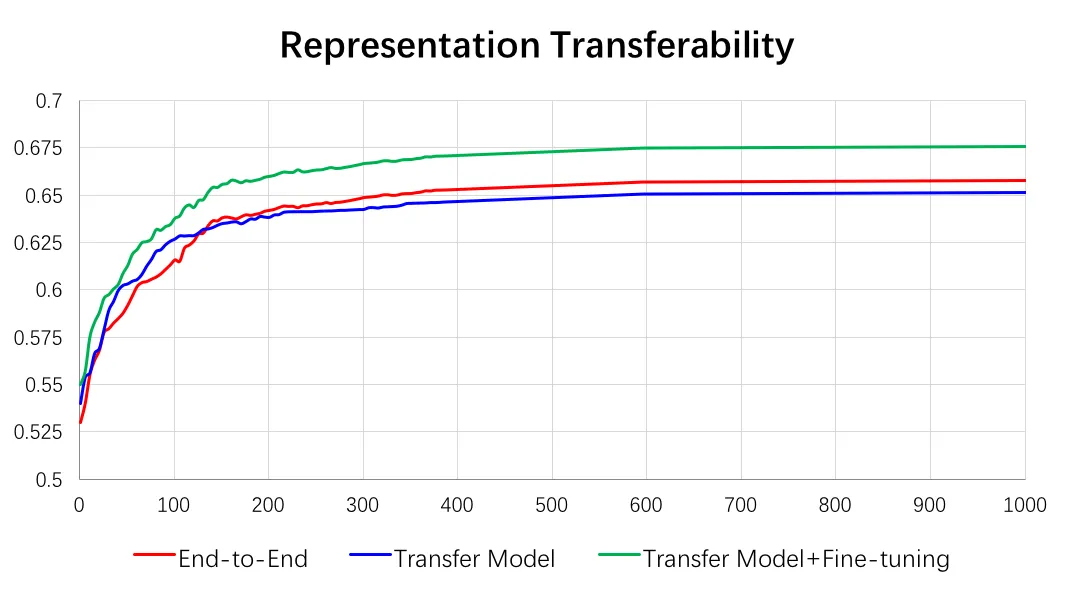
对比RRI,RT能在一开始收敛快很多,这是因为RT的模型非常简洁,参数空间非常小。而随着模型的不断迭代,RRI的AUC会逐渐超越RT,但是即使在训练4天后,AUC的差距也只有0.5%。这组对比反映了我们学到的用户representation有很好的迁移能力,能较好的应用于其他相关任务中,也证明了用户表达的通用。除此以外,RT是一个非常简洁的模型,而且对原来的大DUPN没有任务更新,因此在线应用会更加简洁,对计算性能的开销也会非常小。
4)Attention机制的示例
从第2小节中,我们看到加入attention后,模型的效果有了很大的提升,本章我们会给出一些具体的例子,表明为什么会带来这样的提升。

我们随机的从在线用户中选了一个行为比较丰富的用户,最下面一行图片表示的是该用户的历史行为序列;上面4行颜色块表示的是在不同query下的attention,颜色越深表示attention的权重越大。
图中的用户,行为是多样的,行为的商品中有连衣裙、夹克、遮阳帽和阳伞。当用户搜‘裙子’的时候,我们看到行为序列中的连衣裙被给予了更大的attention,其次是同为服饰的夹克;类似的,但用户搜‘帽子’的时候,遮阳帽的attention高于其他商品,同时阳伞的权重略低于遮阳帽。而在用户搜‘背包’这类看起来跟用户序列关系都不大的query时,仍有部分类别的商品因为一些并不那么明显的原因得到更大的attention。
这个例子说明了attention确实能从用户序列中抽取与用户、query更相关的信息。
(这是我们随机找到的一个比较好例子,类似的例子比较多,但也有很多看起来难以解释的例子。同时还有一些其他的发现:1,商品的attention大小与商品本身的质量有很大关系,高销量、质量好的商品往往attention较大;2,近期的行为attention一般都远高于很久之前的行为)
5)在线测试
最终我们将模型运用在线上,进行A/B测试。我们选用了大致3%的流量,配上了DUPN算法。DUPN在3方面作用于线上。首先我们使用DUPN的购买力预估代替了之前线上的购买力预估;其次,我们计算了一个新的CTR预估分,作为排序的一个feature;最后,我们在LETOR的时候,使用了DUPN。
| 天数 | 模型 | CTR提升 | 销量提升 | 购买力准确率 |
| 1 | DUPN | 1.21% | 1.97% | 34.4%/43.5% |
| 2 | DUPN | 1.32% | 2.10% | 32.6%/44.2% |
| 3 | DUPN | 1.36% | 2.24% | 32.9%/44.7% |
| 4 | DUPN | 1.20% | 1.86% | 33.3%/45.1% |
| 5 | DUPN | 1.15% | 1.82% | 33.0%/43.7% |
| 6 | DUPN | 1.23% | 1.99% | 32.3%/43.9% |
| 7 | DUPN | 1.30% | 2.39% | 34.8%/44.6% |
| Average | DUPN | 1.25% | 2.05% | 33.2%/44.2% |
我们记录了一周的在线实验结果,并计算了平均值。从表中我们看到,在上线DUPN之后,CTR能有1.25%的提升,成交量能有2.05%的提升,同时购买力预估的准确率能从之前线上的33.2%(MaxEnt模型)提升到44.2%。同时,我们统计了不同的档位上的购买力预估的准确率与召回率,如下图。
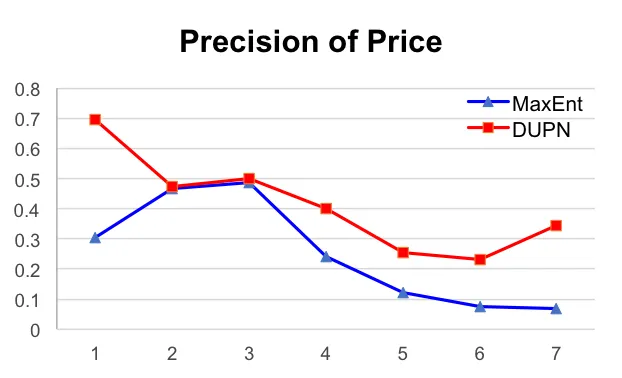
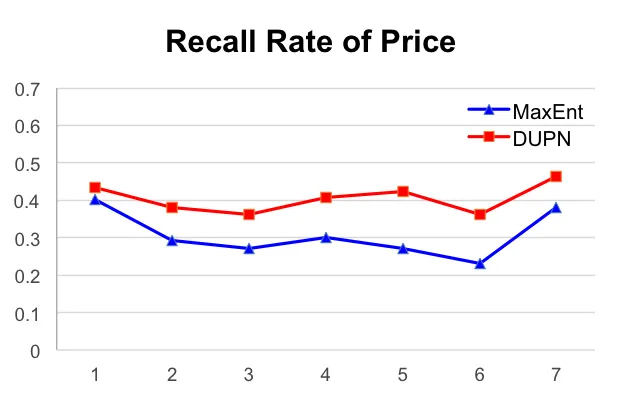
六 实用技巧:
本小节是另一个重点,会给出我们使用超大规模深度学习上的一些问题以及解决经验。
1)模型更新
在我们的模型中,使用了非常多的稀疏ID特征,它们的好处是能够从数据中学习得到非常细节的信息,然而也会带来一些问题。首先,模型需要高频的更新,因为这些ID特征的属性是经常变化的(商品会变得流行或不流行,风格会随着季节的变换变化……),因此embedding也需要随着一起变化。实际我们如果不更新模型,我们发现模型的效果会一天天明显的变差。其次,大量的ID特征导致模型的训练非常慢,如上文所说,做一次全量的训练可能需要长达4-5天。
因此我们采用了增量学习的方式,模型只是在最开始使用10天的数据进行一次全量,之后每天使用前一天的数据做增量。一方面这样训练的时间能大幅下降,能玩一天内完成;另一方面,我们发现如果使用10天的数据训练,10天的数据一起训练结果,不如5天做一次全量然后剩下5天做5次增量。这主要是因为前者并没有没每天的数据进行区分;而后者,近期的数据后训练,会让模型能更好的贴近近期的数据。实际上在双11当天,我们使用了当天不同时段的数据更新了2次模型,因为当天的样本与日常有很大的不同,我们可以看到训练的指标提升非常明显。
2)模型拆分
当用户输入一次query的时候,引擎会召回数千个商品,我们需要对每个商品算一次分,这表示我们的网络需要在线的进行数千次的inference,这是非常消耗计算以及时间的。对我们的在线系统来说,也是不可接受的。
幸运的是,我们发现模型是可以拆分的。我们可以把模型分为2部分,一部分是与商品完全无关的,这部分包括从用户的序列输入,embedding,LSTM和attention,得到用户的表达向量。这块占用了模型的绝大多数计算和时间,但因为与商品无关,因此可以只进行一次计算。第二部分是与商品相关的部分,包括多任务中的CTR和LETOR,这部分只是一些浅层网络的计算,及时计算数千次,也不会有太大的开销。将模型拆分后,在线计算的效率能得到非常大的提升。
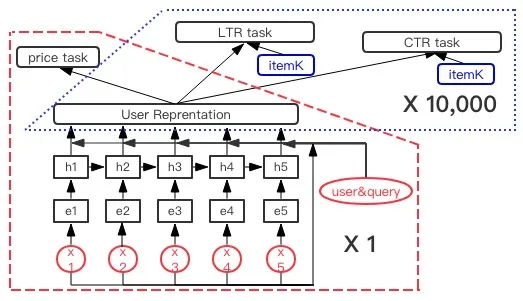
图9 在线模型计算的拆分,红色部分可以只计算一次,蓝色部分需要计算多次
3)关于batch normalization
使用batch normalization能很好的提升模型的效果,对比使用BN前和BN后,模型的AUC能有显著的提升。但是一定要需要注意的是,训练样本中BN记住的均值和方差和在线数据中一定要是尽量一致的,然而这并不总是那么容易。举例来说,在训练样本中我们会做各种过滤和采样,把点击和成交样本过采样,对负样本随机采样;那么这样导致的结果就是某些维度的均值会远远高于实际线上的均值,虽然在测试集上的AUC也能有不错的提升,但是这对在线的效果不不利的。
4)表达的迁移能力
从我们的实验上看来,用户的向量representation确实是有不错的迁移能力,即在其他任务中也能表现出不错的效果。但是这一点在很多参考文献中是不一致的,甚至矛盾的。[18]中的结论与我们的结论基本一致;但是在[37]中,实验却表明在drug discovery中,多任务学到的表达并不具备tranfer能力。应用的时候可能需要根据场景的不同,更注意这块。
5)系统的学习、更新、生效流程图。
最后,下面3张图,分别表示模型的训练流程,模型的更新流程,模型的生效流程
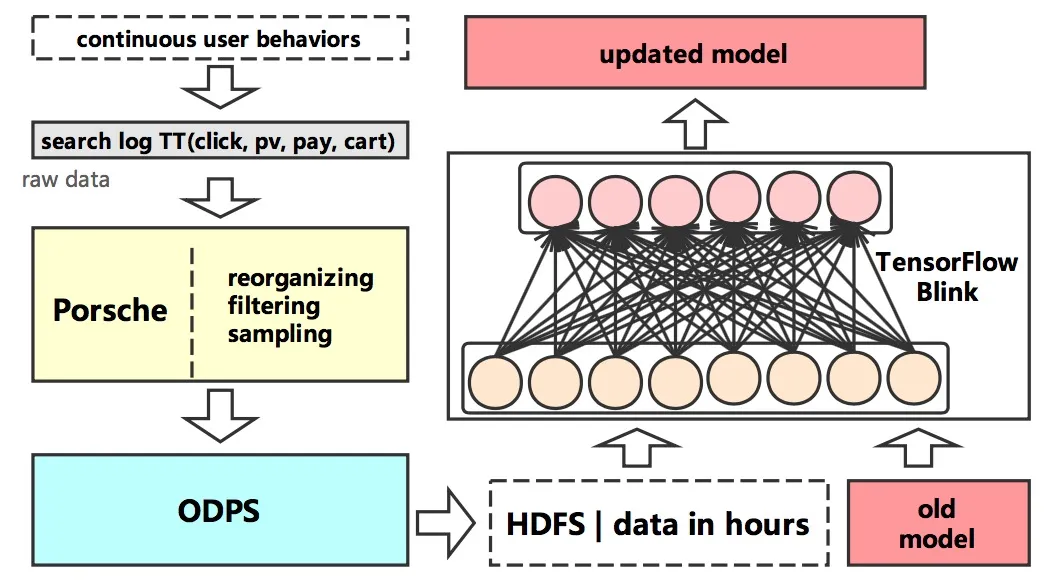
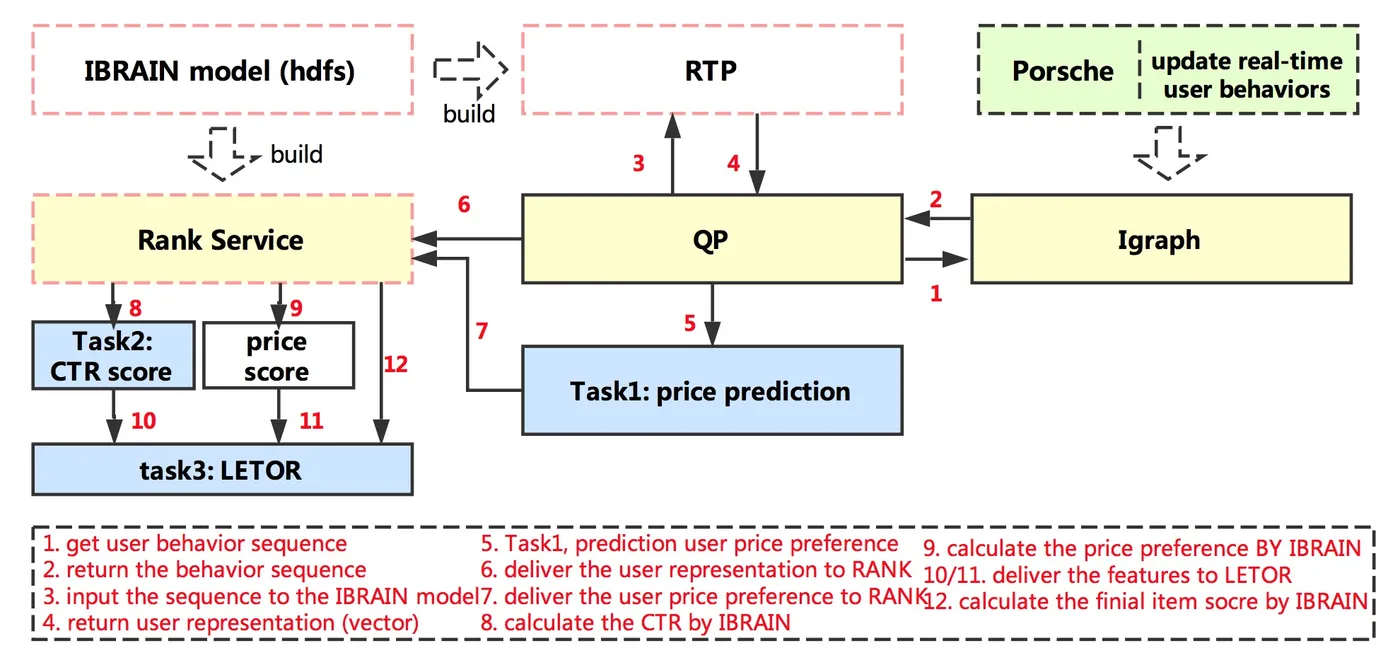
最后,我们工作最重要的部分,并不是提升某个任务,甚至不是直接提升在线的效果,而是学习的到一个希望能在淘宝上很多场景上、多种算法上都能应用的用户表达。从我们目前的实验中,可以看到这是可以实现的。这样一个表达,可以让很多的算法、模型的使用变得简单,同时得到不错的效果。

