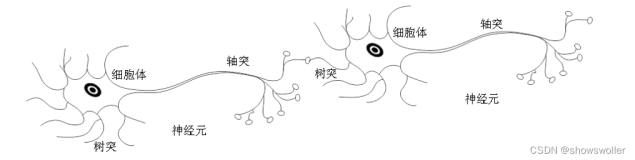
概念
加权算术均值:

众数:集合中出现最频繁的值。一般具有两个或更多众数的数据集是多峰(multimodal)的。
中列数:是数据集的最大值和最小值得平均值。可以用min()和max()计算。

极差: 数据最大值与最小值之差
四分位:

四分位极差(IQR): IQR=Q3-Q1
五数概括:由中位数Q2,四分位数Q1和Q3,最小和最大观测值组成。

方差与标准差
方差与标准差都是数据散步度量,它们支出数据分布的散布程度。低标准差意味着数据趋近于均值,而高标准差表示数据散步在一个大的值域中


数据清理(data cleaning):通过填写缺失的值,光滑噪声数据,识别或者删除离群点,并解决不一致来清理数据。 如同一概念的字段在不同的表中命名不同。
数据集成(data integration): 多个数据库中的数据集中起来
数据规约(data reduction):数据集是巨大的,为了降低数据集的规模而不损害数据挖掘的结果,数据规约得到数据集的简化表示,它小的多,但几乎能产生同样的分析结果。数据规约策略包括维规约和数值规约。
维规约:使用数据编码方案,一遍得到原始数据的简化或者压缩表示。包括数据压缩技术(如小波变化和主成分分析),以及属性子集选择(如去掉不相关的属性)和属性构造(从原来的属性集导出更有用的小属性集)
数值归约,使用参数模型(如回归和对数线性模型)或非线性模型(直方图、聚类、抽样或者数据聚集)用较小的表示取代数据。
数据变换(Data transformation):规范化、离散化和概念分层产生都是某种形式的数据变换。

噪声,是被测量的变量的随机误差或者方差
ETL工具(extraction/Transformation/loading)提取变换装入工具
Potter’s Wheel是一种公开的数据清理工具,集成了偏差检测和数据变换
偏差检测和数据变换
有些冗余会被相关分析检测到。对于标称数据,我们使用卡方检测(x2), 对于数值属相,使用相关系数和协方差,他们都是评估一个属性如何随另一个变化