内存屏障是一个很神奇的东西,之前翻译了linux内核文档memory-barriers.txt,对内存屏障有了一定有理解。现在用自己的方式来整理一下。
在我看来,内存屏障主要解决了两个问题:单处理器下的乱序问题和多处理器下的内存同步问题。
为什么会乱序
现在的CPU一般采用流水线来执行指令。一个指令的执行被分成:取指、译码、访存、执行、写回、等若干个阶段。然后,多条指令可以同时存在于流水线中,同时被执行。
指令流水线并不是串行的,并不会因为一个耗时很长的指令在“执行”阶段呆很长时间,而导致后续的指令都卡在“执行”之前的阶段上。
相反,流水线是并行的,多个指令可以同时处于同一个阶段,只要CPU内部相应的处理部件未被占满即可。比如说CPU有一个加法器和一个除法器,那么一条加法指令和一条除法指令就可能同时处于“执行”阶段, 而两条加法指令在“执行”阶段就只能串行工作。
相比于串行+阻塞的方式,流水线像这样并行的工作,效率是非常高的。
然而,这样一来,乱序可能就产生了。比如一条加法指令原本出现在一条除法指令的后面,但是由于除法的执行时间很长,在它执行完之前,加法可能先执行完了。再比如两条访存指令,可能由于第二条指令命中了cache而导致它先于第一条指令完成。
一般情况下,指令乱序并不是CPU在执行指令之前刻意去调整顺序。CPU总是顺序的去内存里面取指令,然后将其顺序的放入指令流水线。但是指令执行时的各种条件,指令与指令之间的相互影响,可能导致顺序放入流水线的指令,最终乱序执行完成。这就是所谓的“顺序流入,乱序流出”。
指令流水线除了在资源不足的情况下会卡住之外(如前所述的一个加法器应付两条加法指令的情况),指令之间的相关性也是导致流水线阻塞的重要原因。
CPU的乱序执行并不是任意的乱序,而是以保证程序上下文因果关系为前提的。有了这个前提,CPU执行的正确性才有保证。比如:
a++; b=f(a); c--;
由于b=f(a)这条指令依赖于前一条指令a++的执行结果,所以b=f(a)将在“执行”阶段之前被阻塞,直到a++的执行结果被生成出来;而c--跟前面没有依赖,它可能在b=f(a)之前就能执行完。(注意,这里的f(a)并不代表一个以a为参数的函数调用,而是代表以a为操作数的指令。C语言的函数调用是需要若干条指令才能实现的,情况要更复杂些。)
像这样有依赖关系的指令如果挨得很近,后一条指令必定会因为等待前一条执行的结果,而在流水线中阻塞很久,占用流水线的资源。而编译器的乱序,作为编译优化的一种手段,则试图通过指令重排将这样的两条指令拉开距离, 以至于后一条指令进入CPU的时候,前一条指令结果已经得到了,那么也就不再需要阻塞等待了。比如将指令重排为:
a++; c--; b=f(a);
相比于CPU的乱序,编译器的乱序才是真正对指令顺序做了调整。但是编译器的乱序也必须保证程序上下文的因果关系不发生改变。
乱序的后果
乱序执行,有了“保证上下文因果关系”这一前提,一般情况下是不会有问题的。因此,在绝大多数情况下,我们写程序都不会去考虑乱序所带来的影响。
但是,有些程序逻辑,单纯从上下文是看不出它们的因果关系的。比如:
*addr=5; val=*data;
从表面上看,addr和data是没有什么联系的,完全可以放心的去乱序执行。但是如果这是在某某设备驱动程序中,这两个变量却可能对应到设备的地址端口和数据端口。并且,这个设备规定了,当你需要读写设备上的某个寄存器时,先将寄存器编号设置到地址端口,然后就可以通过对数据端口的读写而操作到对应的寄存器。那么这么一来,对前面那两条指令的乱序执行就可能造成错误。
对于这样的逻辑,我们姑且将其称作隐式的因果关系;而指令与指令之间直接的输入输出依赖,也姑且称作显式的因果关系。CPU或者编译器的乱序是以保持显式的因果关系不变为前提的,但是它们都无法识别隐式的因果关系。再举个例子:
obj->data = xxx; obj->ready = 1;
当设置了data之后,记下标志,然后在另一个线程中可能执行:
if (obj->ready) do_something(obj->data);
虽然这个代码看上去有些别扭,但是似乎没错。不过,考虑到乱序,如果标志被置位先于data被设置,那么结果很可能就杯具了。因为从字面上看,前面的那两条指令其实并不存在显式的因果关系,乱序是有可能发生的。
总的来说,如果程序具有显式的因果关系的话,乱序一定会尊重这些关系;否则,乱序就可能打破程序原有的逻辑。这时候,就需要使用屏障来抑制乱序,以维持程序所期望的逻辑。
屏障的作用
内存屏障主要有:读屏障、写屏障、通用屏障、优化屏障、几种。
以读屏障为例,它用于保证读操作有序。屏障之前的读操作一定会先于屏障之后的读操作完成,写操作不受影响,同属于屏障的某一侧的读操作也不受影响。类似的,写屏障用于限制写操作。而通用屏障则对读写操作都有作用。而优化屏障则用于限制编译器的指令重排,不区分读写。前三种屏障都隐含了优化屏障的功能。比如:
tmp = ttt; *addr = 5; mb(); val = *data;
有了内存屏障就了确保先设置地址端口,再读数据端口。而至于设置地址端口与tmp的赋值孰先孰后,屏障则不做干预。
有了内存屏障,就可以在隐式因果关系的场景中,保证因果关系逻辑正确。
多处理器情况
前面只是考虑了单处理器指令乱序的问题,而在多处理器下,除了每个处理器要独自面对上面讨论的问题之外,当处理器之间存在交互的时候,同样要面对乱序的问题。
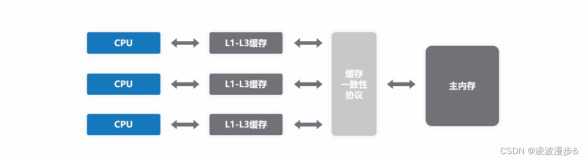
一个处理器(记为a)对内存的写操作并不是直接就在内存上生效的,而是要先经过自身的cache。另一个处理器(记为b)如果要读取相应内存上的新值,先得等a的cache同步到内存,然后b的cache再从内存同步这个新值。而如果需要同步的值不止一个的话,就会存在顺序问题。再举前面的一个例子:
obj->data = xxx;
wmb(); if (obj->ready)
obj->ready = 1; do_something(obj->data);
前面也说过,必须要使用屏障来保证CPU-a不发生乱序,从而使得ready标记置位的时候,data一定是有效的。但是在多处理器情况下,这还不够。data和ready标记的新值可能以相反的顺序更新到CPU-b上!
其实这种情况在大多数体系结构下并不会发生,不过内核文档memory-barriers.txt举了alpha机器的例子。alpha机器可能使用分列的cache结构,每个cache列可以并行工作,以提升效率。而每个cache列上面缓存的数据是互斥的(如果不互斥就还得解决cache列之间的一致性),于是就可能引发cache更新不同步的问题。
假设cache被分成两列,而CPU-a和CPU-b上的data和ready都分别被缓存在不同的cache列上。
首先是CPU-a更新了cache之后,会发送消息让其他CPU的cache来同步新的值,对于data和ready的更新消息是需要按顺序发出的。如果 cache只有一列,那么指令执行的顺序就决定了操作cache的顺序,也就决定了cache更新消息发出的顺序。但是现在假设了有两个cache列,可能由于缓存data的cache列比较繁忙而使得data的更新消息晚于ready发出,那么程序逻辑就没法保证了。不过好在SMP下的内存屏障在解决指令乱序问题之外,也将cache更新消息乱序的问题解决了。只要使用了屏障,就能保证屏障之前的cache更新消息先于屏障之后的消息被发出。
然后就是CPU-b的问题。在使用了屏障之后,CPU-a已经保证data的更新消息先发出了,那么CPU-b也会先收到data的更新消息。不过同样,CPU-b上缓存data的cache列可能比较繁忙,导致对data的更新晚于对ready的更新。这里同样会出问题。
所以,在这种情况下,CPU-b也得使用屏障。CPU-a上要使用写屏障,保证两个写操作不乱序,并且相应的两个cache更新消息不乱序。CPU-b上则需要使用读屏障,保证对两个cache单元的同步不乱序。可见,SMP下的内存屏障一定是需要配对使用的。
所以,上面的例子应该改写成:
obj->data = xxx; if (obj->ready)
wmb(); rmb();
obj->ready = 1; do_something(obj->data);
CPU-b上使用的读屏障还有一种弱化版本,它不保证读操作的有序性,叫做数据依赖屏障。顾名思义,它是在具有数据依赖情况下使用的屏障,因为有数据依赖(也就是之前所说的显式的因果关系),所以CPU和编译器已经能够保证指令的顺序。
再举个例子:
init(newval); p = data;
data = &newval; val = *p;
这里的屏障就可以保证:如果data指向了newval,那么newval一定是初始化过的。
摘自:http://blog.chinaunix.net/uid-12461657-id-3156862.html