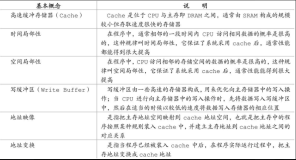
buffer cache 里有三种数据结构来管理内存空间
1 hash chain 2 LRU LIST 3 DIRTY LIST
hash chain 是为快速定位buffer cache中块的结构,主要通过hash链表实现。每个hash桶对应一个hash链。链上每个header指向一个数据块,
一个hash latch管理多个hash桶。
有对应隐含参数管理latch个数,和hash桶的个数。大概一个latch管理32个hash桶。latch就是桶上的锁,如果两个进程都已只读方式读取链上
的两个块,那么latch可以对只读共享。如果一个进程读一个块,另一个进程要修改桶对应链上的另一个块,就是独占方式访问,于是要等前一个
进程释放latch才能用独占方式访问这个块。后一个进程在等待前一个进程释放latch时,发生等待事件latch:cache buffers chains。
对这个等待事件解决方法,可能遇到大量逻辑读很多的sql,要逻辑读,就要访问一个块,就可能获取latch,引发大量latch:cache buffers chains
争用,于是根据逻辑读排序找出逻辑读最多的sql,调整其执行计划。
等待事件具体诊断可参考 latch:cache buffers chains的优化思路 http://blog.itpub.net/24742969/viewspace-1692853/
LRU list在缓存初始加载时,所有buffer cache 块都放到LRU list管理,从磁盘读取数据到内存前,先查看LRU list找到一个空块,以便存放磁盘
读到内存的数据。读LIST的时候如果有块时脏块,就把这样的块放到dirty LIST。扫描LRU list超过40%还没找到空块,停止扫描写dirty LIST脏数据
到磁盘,并给出free buffer wait等待事件,如果经常发生这个事件就要考虑加大Buffer Cache了。还有如果dirty LIST超过25%也会写脏数据
到磁盘。
通俗的说就是先通过hash chain找到内存块读数据,如果读取的数据没在内存块,就要从磁盘读数据到内存,读入内存时哪个块是空块,或要换出内存被
写入磁盘数据由LRU决定。如果块上的数据是脏数据就用dirtyLIST 管理,脏数据写出后,该块仍由LRU管理
LRU LIST 和 DIRTY LIST 统一称为working set 他们也需要latch保护,因为他们是共享的用于管理内存的块,需要latch防止数据的破坏